深度强化学习CS285 lec13-lec15 基础知识:变分推断VI与GAN
变分推断Variational Inference、生成对抗网络GAN
- 概述
- 一、简要回顾信息论
-
- 1.1 概念与公式
- 1.2小总结
- 二、 变分推断(Variational Inference)
-
- 2.1背景
- 2.2 Variational Inference
- 三、GAN
-
- 3.1 原始GAN
- 3.2 “-log D trick”的GAN
- 小结
概述
- Lec1-Lec4 RL Introduction
- 介绍传统Imitation Learning的背景、算法、难点.IL学习的方式是通过Supervised Learning以state-action直接建立策略 π ( a ∣ s ) \pi(a|s) π(a∣s)的mapping,因此只能拟合数据与label的相关性.
- 引入额外监督信息 r ( s , a ) r(s,a) r(s,a),尝试添加因果性,因此增加了灵活性(多solution应对更复杂的任务)的同时,付出了复杂度增大的代价(credit-assignment、exploration与exploitation).
- 对RL监督信息的来源、问题的建模、算法的大致分类进行了抽象介绍.
- Lec5-Lec9 Model-free RL
- 假设 无环境dynamics model,已知reward function、且为MDP的情况下,基于与真实环境交互得到的样本trajectory来估计梯度 ∇ J ( θ ) \nabla J(\theta) ∇J(θ)或值函数 Q ∗ ( s , a ) Q^*(s,a) Q∗(s,a),从而进行策略优化PI(Policy Improvement).
- 讨论了Policy Gradient、Value-based(V与Q)、Actor-Critic三大类型的model-free算法大致原理.
- 根据状态state、动作action的离散(discrete)或连续(continuous)、高维(high-dim)或低维(low-dim)进行Model-free算法选型.
- Lec10-Lec12 LQR framework
- 主要介绍了LQR、iLQR、DDP三种规划(planning)算法
- 在LQR应对deterministic dynamics system,iLQR应对stochastic dynamics system,DDP是对dynamics model以及cost function都做了quadratic approximation的LQR扩展形态
- Lec10-Lec12 Model-based RL
- 引入了dynamics model p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a)或 f ( x t , u t ) f(x_t,u_t) f(xt,ut) ,分为deterministic与stochastic两种,介绍了Model-based RL的基本算法(当然有进阶版)
- 介绍了Stochastic Optimizatin、MCTS和LQR framework三种经典规划算法planning,也统称Trajectory Optimization在已有dynamics model上怎么去做Optimal Control,得到较优控制序列
- 怎么更好的拟合dynamics model,引入DAgger、MPC replan、Uncertainty-Award、Latent Model来相应解决Distribution Mismatch、Compound Error、Diverse Exploration in State Space、State Representation的问题
- 介绍了通过dynamics model来辅助Policy学习的General Dyna-Style算法以及Divide and Conquer RL中的比较经典的Guided Policy Search.
本文主要是为推导较繁琐的lec14-Reframe Control As Inference与lec15-Inverse Reinforcement Learning进行基础铺垫,介绍变分推断VI、对抗生成网络GAN的理论基础,减轻一些负担,是是是,我知道这个都很常见啦,当回顾一下。
本文安排:
- 回顾一些信息论的概念,如信息量、熵Entropy、交叉熵Cross Entropy、KL散度、JS散度等.
- 介绍Latent Variable Model、EM算法、变分推断VI
- 介绍GAN的理论基础,这跟逆强化学习IRL联系很!很!很紧密!
一、简要回顾信息论
1.1 概念与公式
假设: p ( x ) p(x) p(x)为真实分布, q ( x ) q(x) q(x)为模型分布.
- 信息量
I x 0 ∼ p ( x ) ( x 0 ) = − l o g p ( x 0 ) I_{x_0\sim p(x)}(x_0)=-logp(x_0) Ix0∼p(x)(x0)=−logp(x0)
| p ( x 0 ) p(x_0) p(x0) | 1 2 \frac{1}{2} 21 | 1 3 \frac{1}{3} 31 | 1 6 \frac{1}{6} 61 |
|---|---|---|---|
| l o g p ( x 0 ) logp(x_0) logp(x0) | − l o g 2 -log2 −log2 | − l o g 3 -log3 −log3 | − l o g 6 -log6 −log6 |
| I ( x 0 ) I(x_0) I(x0) | l o g 2 log2 log2 | l o g 3 log3 log3 | l o g 6 log6 log6 |
说明:概率越小,信息量越大.
(啰嗦的缘由是希望从数值上得到直观印象,直接将 − l o g p ( x 0 ) -logp(x_0) −logp(x0)就看成一个整体,避免自己老是 p ( x 0 ) p(x_0) p(x0)小, l o g p ( x 0 ) logp(x_0) logp(x0)小, − l o g p ( x 0 ) -logp(x_0) −logp(x0)就大,像个呆板的沙雕=.=)
-
熵(Entropy)
H ( p ) = ∑ x 0 ∼ p ( x ) p ( x 0 ) [ − l o g p ( x 0 ) ] = ∫ p ( x ) [ − l o g p ( x ) ] d x = E x 0 ∼ p ( x ) [ − l o g p ( x 0 ) ] H(p)=\sum_{x_0\sim p(x)}p(x_0)[-logp(x_0)]=\int p(x)[-logp(x)]dx=E_{x_0\sim p(x)}\big[-logp(x_0)\big] H(p)=x0∼p(x)∑p(x0)[−logp(x0)]=∫p(x)[−logp(x)]dx=Ex0∼p(x)[−logp(x0)]说明:真实分布 p p p的信息量 − l o g p ( x ) -logp(x) −logp(x)在自身的期望,熵越低分布越deterministic,熵越高分布越stochastic.
用途:用来衡量一个分布自身的随机程度,类似于数据中的方差variance.
(啰嗦的缘由是建立 p ( x ) p(x) p(x)与 − l o g p ( x ) -logp(x) −logp(x)的直观印象, p ( x ) p(x) p(x)小, − l o g p ( x ) -logp(x) −logp(x)大,即该样本 x x x属于真实分布的概率小,则信息量 − l o g p ( x ) -logp(x) −logp(x)大) -
交叉熵(Cross Entropy)
H ( p , q ) = ∑ x 0 ∼ p ( x ) p ( x 0 ) [ − l o g q ( x 0 ) ] = ∫ p ( x ) [ − l o g q ( x ) ] d x = E x 0 ∼ p ( x ) [ − l o g q ( x 0 ) ] H(p,q)=\sum_{x_0\sim p(x)}p(x_0)[-logq(x_0)]=\int p(x)[-logq(x)]dx=E_{x_0\sim p(x)}\big[-logq(x_0)\big] H(p,q)=x0∼p(x)∑p(x0)[−logq(x0)]=∫p(x)[−logq(x)]dx=Ex0∼p(x)[−logq(x0)]说明:模型分布 q q q的信息量 − l o g q ( x ) -logq(x) −logq(x)在真实分布 p p p下的期望,Cross Entropy越大p与q越不相似,Cross Entropy越小p与q越接近
用途:衡量模型分布与真实分布之间的相似程度, H ( p ) = H ( p , p ) H(p)=H(p,p) H(p)=H(p,p)
(又来啰嗦了,该样本 x x x属于模型分布 q q q的概率小,则信息量 − l o g q ( x ) -logq(x) −logq(x)大,若属于真实分布 p p p的概率大,则 p ( x ) [ − l o g q ( x ) ] p(x)[-logq(x)] p(x)[−logq(x)]大,于是在该点 x x x上, p , q p,q p,q越不相似,一高一低) -
KL散度(Kullback–Leibler divergence)
K L ( p , q ) = ∑ x 0 ∼ p ( x ) p ( x 0 ) l o g p ( x 0 ) q ( x 0 ) = ∫ p ( x ) l o g p ( x ) q ( x ) d x = E x 0 ∼ p ( x ) [ l o g p ( x ) q ( x ) ] KL(p,q)=\sum_{x_0\sim p(x)}p(x_0)log\frac{p(x_0)}{q(x_0)}=\int p(x)log\frac{p(x)}{q(x)}dx=E_{x_0\sim p(x)}\Big[log\frac{p(x)}{q(x)}\Big] KL(p,q)=x0∼p(x)∑p(x0)logq(x0)p(x0)=∫p(x)logq(x)p(x)dx=Ex0∼p(x)[logq(x)p(x)]
K L ( p , q ) = ∫ p ( x ) l o g p ( x ) q ( x ) d x = ∫ p ( x ) [ [ − l o g q ( x ) ] − [ − l o g p ( x ) ] ] d x = E p ( x ) [ I ( q ) − I ( p ) ] ( 1 ) = ∫ p ( x ) l o g p ( x ) d x + ∫ p ( x ) [ − l o g q ( x ) ] d x = − H ( p ) + H ( p , q ) ≥ 0 ( 2 ) \begin{aligned} KL(p,q)&=\int p(x)log\frac{p(x)}{q(x)}dx\\ &=\int p(x)\Big[[-logq(x)]-[-logp(x)]\Big]dx\\ &=E_{p(x)}\Big[I(q)-I(p)\Big]\quad (1)\\ &=\int p(x)logp(x)dx+\int p(x)[-logq(x)]dx\\ &=-H(p)+H(p,q)\geq0 \quad(2)\\ \end{aligned} KL(p,q)=∫p(x)logq(x)p(x)dx=∫p(x)[[−logq(x)]−[−logp(x)]]dx=Ep(x)[I(q)−I(p)](1)=∫p(x)logp(x)dx+∫p(x)[−logq(x)]dx=−H(p)+H(p,q)≥0(2)说明:两者越相似, p ( x ) q ( x ) → 1 , l o g p ( x ) q ( x ) → 0 \frac{p(x)}{q(x)}\rightarrow1,log\frac{p(x)}{q(x)}\rightarrow0 q(x)p(x)→1,logq(x)p(x)→0, K L ( p , q ) KL(p,q) KL(p,q)越小;
用途: K L ( p , q ) KL(p,q) KL(p,q)是用来衡量两个分布之间的差异.
(突然啰嗦症晚期,由 ( 1 ) (1) (1)可知,KL散度可看作两个分布信息量的差在真实分布 p p p上的期望,两者相等时,期望为0;两者相差越远时,如在样本点x上, q ( x ) q(x) q(x)小, p ( x ) p(x) p(x)大,则两者信息量差距越大。由 ( 2 ) (2) (2)可知,KL散度=交叉熵-熵.) -
JS散度(Jensen-Shannon)
J S ( p ∣ ∣ q ) = 1 2 K L ( p ∣ ∣ p + q 2 ) + 1 2 K L ( q ∣ ∣ p + q 2 ) = 1 2 ∫ [ p ( x ) l o g 2 p ( x ) p ( x ) + q ( x ) + q ( x ) l o g 2 q ( x ) p ( x ) + q ( x ) ] d x \begin{aligned} JS(p||q)&=\frac{1}{2}KL(p||\frac{p+q}{2})+\frac{1}{2}KL(q||\frac{p+q}{2})\\ &=\frac{1}{2}\int\Big[ p(x)log\frac{2p(x)}{p(x)+q(x)}+q(x)log\frac{2q(x)}{p(x)+q(x)}\Big]dx\\ \end{aligned} JS(p∣∣q)=21KL(p∣∣2p+q)+21KL(q∣∣2p+q)=21∫[p(x)logp(x)+q(x)2p(x)+q(x)logp(x)+q(x)2q(x)]dx
1.2小总结
一般数据来源为真实分布,算法拟合的为模型分布。
- H ( q ) H(q) H(q)衡量拟合数据的模型分布的随机程度,对于策略 π ( a ∣ s ) \pi(a|s) π(a∣s),一般希望其随机利于探索,则可在目标中添加 max θ H ( π θ ( a ∣ s ) ) \max_\theta H(\pi_\theta(a|s)) maxθH(πθ(a∣s))即 min θ − H ( π θ ( a ∣ s ) ) \min_\theta-H(\pi_\theta(a|s)) minθ−H(πθ(a∣s))
- H ( p , q ) H(p,q) H(p,q)与 K L ( p , q ) KL(p,q) KL(p,q)主要区别是,当p为真实分布时, H ( p ) H(p) H(p)为常数,所以有 m i n K L ( p , q ) = m i n H ( p , q ) − H ( p ) ≡ m i n H ( p , q ) minKL(p,q)=minH(p,q)-H(p)\equiv minH(p,q) minKL(p,q)=minH(p,q)−H(p)≡minH(p,q)。所以监督学习时,一般数据是真实分布,最小化KL散度等价于最小化交叉熵,可以算少一点。若要衡量两个模型分布的差异,则需要使用KL散度,如Knowledge Distillation,如TRPO中施加的约束,希望更新的Policy与之前的Poilcy差异不要太大 D K L ( π θ ( a ∣ s ) ∣ ∣ π θ ˉ ( a ∣ s ) ) ≤ ϵ D_{KL}\big(\pi_\theta(a|s)||\pi_{\bar\theta}(a|s)\big)\leq\epsilon DKL(πθ(a∣s)∣∣πθˉ(a∣s))≤ϵ
- JS散度是为了解决KL散度不对称性提出的一个指标。
二、 变分推断(Variational Inference)
2.1背景
现在有一个可看作从真实分布 p p p采样的数据集 D = { x 1 , x 2 , . . . , x N } D=\{x_1,x_2,...,x_N\} D={x1,x2,...,xN}, x i x_i xi表示第 i i i个样本,label为 { y 1 , y 2 , . . . , y N } \{y_1,y_2,...,y_N\} {y1,y2,...,yN},先忽略分类的label,用模型参数 θ \theta θ去拟合数据本身的概率密度 p ( x ) p(x) p(x)
最大似然目标为:
θ ← arg max θ 1 N ∑ i l o g p θ ( x i ) \theta\leftarrow \argmax_\theta \frac{1}{N}\sum_ilogp_\theta(x_i) θ←θargmaxN1i∑logpθ(xi)
假设数据有隐变量: p ( x ) = ∫ p ( x ∣ z ) p ( z ) d z p(x)=\int p(x|z)p(z)dz p(x)=∫p(x∣z)p(z)dz
θ ← arg max θ 1 N ∑ i l o g ∫ p θ ( x i ∣ z ) p ( z ) d z \theta\leftarrow \argmax_\theta \frac{1}{N}\sum_ilog\int p_\theta(x_i|z)p(z)dz θ←θargmaxN1i∑log∫pθ(xi∣z)p(z)dz
由于关于隐变量的积分是intractable的,回顾一下EM算法:
l o g p ( x i ) = l o g ∫ p θ ( x i ∣ z ) p ( z ) d z = l o g ∫ p θ ( x i , z ) d z = l o g ∫ p θ ( x i , z ) q i ( z ) q i ( z ) d z = l o g E z ∼ q i ( z ) [ p θ ( x i , z ) q i ( z ) ] ( 1 ) ≥ E z ∼ q i ( z ) [ l o g p θ ( x i , z ) q i ( z ) ] ( 2 ) = ∫ q i ( z ) l o g p θ ( x i , z ) q i ( z ) d z = ∫ q i ( z ) [ − l o g q i ( z ) ] d z + ∫ q i ( z ) l o g p θ ( x i , z ) d z = E z ∼ q i ( z ) [ l o g p θ ( x i , z ) ] + H ( q i ) \begin{aligned} logp(x_i)&=log\int p_\theta(x_i|z)p(z)dz\\ &=log\int p_\theta(x_i,z)dz\\ &=log\int p_\theta(x_i,z)\frac{q_i(z)}{q_i(z)}dz\\ &=logE_{z\sim q_i(z)}\Big[\frac{p_\theta(x_i,z)}{q_i(z)}\Big]\quad (1)\\ &\geq E_{z\sim q_i(z)}\Big[log\frac{p_\theta(x_i,z)}{q_i(z)}\Big]\quad(2)\\ &=\int q_i(z)log\frac{p_\theta(x_i,z)}{q_i(z)}dz\\ &=\int q_i(z)[-logq_i(z)]dz+\int q_i(z)logp_\theta(x_i,z)dz\\ &=E_{z\sim q_i(z)}\Big[logp_\theta(x_i,z)\Big]+H(q_i) \end{aligned} logp(xi)=log∫pθ(xi∣z)p(z)dz=log∫pθ(xi,z)dz=log∫pθ(xi,z)qi(z)qi(z)dz=logEz∼qi(z)[qi(z)pθ(xi,z)](1)≥Ez∼qi(z)[logqi(z)pθ(xi,z)](2)=∫qi(z)logqi(z)pθ(xi,z)dz=∫qi(z)[−logqi(z)]dz+∫qi(z)logpθ(xi,z)dz=Ez∼qi(z)[logpθ(xi,z)]+H(qi)
( 1 ) (1) (1)到 ( 2 ) (2) (2)使用了 l o g E [ f ] ≥ E [ l o g f ] logE[f]\geq E[logf] logE[f]≥E[logf],且等号成立条件为 p θ ( x i , z ) q i ( z ) = c \frac{p_\theta(x_i,z)}{q_i(z)}=c qi(z)pθ(xi,z)=c,且 ∫ q i ( z ) d z = 1 , c \int q_i(z)dz=1,c ∫qi(z)dz=1,c为常数,有
∫ q i ( z ) d z = ∫ p θ ( x i , z ) c d z = 1 ∫ p θ ( x i , z ) d z = p θ ( x i ) = c q i ( z ) = p θ ( x i , z ) c = p θ ( x i , z ) p θ ( x i ) = p θ ( z ∣ x i ) \int q_i(z)dz=\int\frac{p_\theta(x_i,z)}{c}dz=1\\ \int p_\theta(x_i,z)dz=p_\theta(x_i)=c\\ q_i(z)=\frac{p_\theta(x_i,z)}{c}=\frac{p_\theta(x_i,z)}{p_\theta(x_i)}=p_\theta(z|x_i) ∫qi(z)dz=∫cpθ(xi,z)dz=1∫pθ(xi,z)dz=pθ(xi)=cqi(z)=cpθ(xi,z)=pθ(xi)pθ(xi,z)=pθ(z∣xi)
所以在EM算法中的最大似然目标变化如下:
arg max θ ∑ i l o g p θ ( x i ) = arg max θ ∑ i l o g ∫ p θ ( x i , z ) d z = arg max θ ∑ i E z ∼ p θ ( z ∣ x i ) [ l o g p θ ( x i , z ) ] \begin{aligned} \argmax_\theta \sum_ilogp_\theta(x_i)&=\argmax_\theta\sum_ilog\int p_\theta(x_i,z)dz\\ &=\argmax_\theta \sum_i E_{z\sim p_\theta (z|x_i)}[logp_\theta(x_i,z)]\\ \end{aligned} θargmaxi∑logpθ(xi)=θargmaxi∑log∫pθ(xi,z)dz=θargmaxi∑Ez∼pθ(z∣xi)[logpθ(xi,z)]
(解释一下,由上面推导可知 l o g p θ ( x i ) ≥ E z ∼ q i ( z ) [ l o g p θ ( x i , z ) ] + H ( q i ) logp_\theta(x_i)\geq E_{z\sim q_i(z)}\Big[logp_\theta(x_i,z)\Big]+H(q_i) logpθ(xi)≥Ez∼qi(z)[logpθ(xi,z)]+H(qi),而等号成立时有 q i ( z ) = p θ ( z ∣ x i ) q_i(z)=p_\theta(z|x_i) qi(z)=pθ(z∣xi),所以相当于优化下界,EM算法流程为:
输入观察数据 x = ( x 1 , x 2 , ⋯ , x N ) x=(x_1,x_2,\cdots,x_N) x=(x1,x2,⋯,xN),联合分布 p θ ( x , z ) p_\theta(x,z) pθ(x,z),条件分布 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x),迭代次数 J J J
- 初始化参数 θ 0 \theta_0 θ0
- For j=1 to J 开始EM算法迭代:
E-step:
q i ( z i ) = p ( z i ∣ x i , θ j ) L ( θ , θ j ) = ∑ i = 1 N ∑ z ∼ q i ( z ) q i ( z ) l o g p θ ( x i , z ) q_i(z_i)=p(z_i|x_i,\theta_j)\\ L(\theta,\theta_j)=\sum_{i=1}^N\sum_{z\sim q_i(z)}q_i(z)logp_\theta(x_i,z) qi(zi)=p(zi∣xi,θj)L(θ,θj)=i=1∑Nz∼qi(z)∑qi(z)logpθ(xi,z)
M-step:
θ j + 1 = arg max θ L ( θ , θ j ) \theta_{j+1}=\argmax_\theta L(\theta,\theta_j) θj+1=θargmaxL(θ,θj) - 直到 θ j + 1 \theta^{j+1} θj+1收敛,输出模型参数 θ \theta θ
可参见刘建平的EM算法总结
算法是这样没有错,但细究一下, p ( z ∣ x , θ ) p(z|x,\theta) p(z∣x,θ)这个真实隐变量分布,如果不人为设定的话,应该如何计算呢?
这时候就需要变分推断通过迭代的方式,使 q ( z ∣ x ) q(z|x) q(z∣x)迭代地近似 p ( z ∣ x ) p(z|x) p(z∣x)这个分布了。因为数据复杂的时候,根本不清楚隐变量是什么情况呀,简单的时候可以假设每个样本 x i x_i xi服从一个隐变量高斯分布 q i ( z ) = N ( u i , σ i ) q_i(z)=N(u_i,\sigma_i) qi(z)=N(ui,σi),但复杂的时候,只能拟合隐变量的分布了。
总结:算法里已知的是观察数据,未知的是隐含变量 z z z和模型参数 θ \theta θ,在E步,我们所做的事情是固定模型参数的值 θ j \theta_j θj,优化隐含数据的分布 p ( z ∣ x i , θ j ) p(z|x_i,\theta_j) p(z∣xi,θj),而在M步,我们所做的事情是固定隐含数据分布,优化模型参数的值
2.2 Variational Inference
由上一节可知,对于每一个样本有:
l o g p ( x i ) ≥ E z ∼ q i ( z ) [ l o g p θ ( x i , z ) ] + H ( q i ) logp(x_i)\geq E_{z\sim q_i(z)}\Big[logp_\theta(x_i,z)\Big]+H(q_i) logp(xi)≥Ez∼qi(z)[logpθ(xi,z)]+H(qi)
记 L i ( p , q i ) = E z ∼ q i ( z ) [ l o g p θ ( x i , z ) ] + H ( q i ) 记 L_i(p,q_i)=E_{z\sim q_i(z)}\Big[logp_\theta(x_i,z)\Big]+H(q_i) 记Li(p,qi)=Ez∼qi(z)[logpθ(xi,z)]+H(qi)
先下结论:
l o g p ( x i ) = L i ( p , q i ) + K L ( q i ( z ) ∣ ∣ p ( z ∣ x i ) ) logp(x_i)=L_i(p,q_i)+KL\big(q_i(z)||p(z|x_i)\big) logp(xi)=Li(p,qi)+KL(qi(z)∣∣p(z∣xi))
然后证明:
K L ( q i ( z ) ∣ ∣ p ( z ∣ x i ) ) = ∫ q i ( z ) l o g q i ( z ) p ( z ∣ x i ) d z = ∫ q i ( z ) l o g q i ( z ) d z − ∫ q i ( z ) l o g p ( z ∣ x i ) d z = − H ( q i ) − ∫ q i ( z ) l o g p ( x i , z ) p ( x i ) d z = − H ( q i ) − E z ∼ q i ( z ) l o g p ( x i , z ) + ∫ q i ( z ) l o g p ( x i ) d z = − L i ( p , q i ) + l o g p ( x i ) \begin{aligned} KL(q_i(z)||p(z|x_i))&=\int q_i(z)log\frac{q_i(z)}{p(z|x_i)}dz\\ &=\int q_i(z)logq_i(z)dz-\int q_i(z)logp(z|x_i)dz\\ &=-H(q_i)-\int q_i(z)log\frac{p(x_i,z)}{p(x_i)}dz\\ &=-H(q_i)-E_{z\sim q_i(z)}logp(x_i,z)+\int q_i(z)logp(x_i)dz\\ &=-L_i(p,q_i)+logp(x_i) \end{aligned} KL(qi(z)∣∣p(z∣xi))=∫qi(z)logp(z∣xi)qi(z)dz=∫qi(z)logqi(z)dz−∫qi(z)logp(z∣xi)dz=−H(qi)−∫qi(z)logp(xi)p(xi,z)dz=−H(qi)−Ez∼qi(z)logp(xi,z)+∫qi(z)logp(xi)dz=−Li(p,qi)+logp(xi)
因此有:
arg max θ ∑ i l o g p θ ( x i ) ≡ arg max θ L ( p , q i ) 同 时 arg min q i K L ( q i ∣ ∣ p ( z ∣ x i ) ) \argmax_\theta\sum_ilogp_\theta(x_i)\equiv \argmax_\theta L(p,q_i)同时\argmin_{q_i} KL(q_i||p(z|x_i)) θargmaxi∑logpθ(xi)≡θargmaxL(p,qi)同时qiargminKL(qi∣∣p(z∣xi))
对于每一个样本 x i x_i xi(或一个batch):
\quad 计算 ∇ θ L i ( p , q i ) \nabla_\theta L_i(p,q_i) ∇θLi(p,qi):
\quad \quad 从简单分布 q i ( z ) q_i(z) qi(z)中采样隐变量 z z z
\quad \quad ∇ θ L i ( p , q i ) ≈ ∇ θ l o g p θ ( x i ∣ z ) \nabla_\theta L_i(p,q_i)\approx\nabla_\theta logp_\theta(x_i|z) ∇θLi(p,qi)≈∇θlogpθ(xi∣z)
\quad 参数更新: θ ← θ + α ∇ θ L i ( p , q i ) \theta \leftarrow\theta+\alpha\nabla_\theta L_i(p,q_i) θ←θ+α∇θLi(p,qi)
\quad 然后更新近似分布: q i ← arg max q i L i ( p , q i ) q_i\leftarrow\argmax_{q_i}L_i(p,q_i) qi←qiargmaxLi(p,qi)
那用来近似真实分布 p ( z ∣ x i ) p(z|x_i) p(z∣xi)的 q i q_i qi应该是什么比较好呢?
如果是高斯分布有, z ∼ N ( u i , σ i ) z\sim N(u_i,\sigma_i) z∼N(ui,σi),如果每个样本一个高斯分布,那就有 N × ( ∣ u i ∣ + ∣ σ i ∣ ) N\times(|u_i|+|\sigma_i|) N×(∣ui∣+∣σi∣)个参数,那可以选择GMM模型来拟合隐变量分布,即 N N N个样本用 M < N M
我们需要建模的有 p θ ( x ∣ z ) , q ϕ ( z ∣ x ) p_\theta(x|z),q_\phi(z|x) pθ(x∣z),qϕ(z∣x),用 θ \theta θ代表隐变量下模型参数,用 ϕ \phi ϕ代表隐变量分布结构的参数

 于是流程变为
于是流程变为
对于每一个样本 x i x_i xi(或一个batch):
\quad 计算 ∇ θ L ( p θ ( x i ∣ z ) , q ϕ ( z ∣ x i ) ) \nabla_\theta L(p_\theta(x_i|z),q_\phi(z|x_i)) ∇θL(pθ(xi∣z),qϕ(z∣xi)):
\quad \quad 从简单分布 q ϕ ( z ∣ x i ) q_\phi(z|x_i) qϕ(z∣xi)中采样隐变量 z z z
\quad \quad ∇ θ L ≈ ∇ θ l o g p θ ( x i ∣ z ) \nabla_\theta L\approx\nabla_\theta logp_\theta(x_i|z) ∇θL≈∇θlogpθ(xi∣z)
\quad 更新模型参数: θ ← θ + α ∇ θ L \theta \leftarrow\theta+\alpha\nabla_\theta L θ←θ+α∇θL
\quad 更新近似分布: ϕ ← ϕ + α ∇ ϕ L \phi\leftarrow\phi+\alpha\nabla_\phi L ϕ←ϕ+α∇ϕL
∇ ϕ L \nabla_\phi L ∇ϕL的计算方式有两种:
- Policy Gradient形式
∇ ϕ L i = E z ∼ q ϕ ( z ∣ x i ) [ l o g p θ ( x i ∣ z ) + l o g p ( z ) ] ⏟ J ( ϕ ) + H ( q ϕ ( z ∣ x i ) ) \nabla_\phi L_i=\underbrace{E_{z\sim q_\phi(z|x_i)}\Big[logp_\theta(x_i|z)+logp(z)\Big]}_{J(\phi)}+H(q_\phi(z|x_i)) ∇ϕLi=J(ϕ) Ez∼qϕ(z∣xi)[logpθ(xi∣z)+logp(z)]+H(qϕ(z∣xi))
记 r ( x i , z ) = l o g p θ ( x i ∣ z ) + l o g p ( z ) 记r(x_i,z)=logp_\theta(x_i|z)+logp(z) 记r(xi,z)=logpθ(xi∣z)+logp(z)
所以采样估计期望有:
∇ J ( ϕ ) ≈ 1 M ∑ j ∇ ϕ l o g q ϕ ( z j ∣ x i ) r ( x i , z j ) \nabla J(\phi)\approx \frac{1}{M}\sum_j\nabla_\phi logq_\phi(z_j|x_i)r(x_i,z_j) ∇J(ϕ)≈M1j∑∇ϕlogqϕ(zj∣xi)r(xi,zj)
∇ H ( q ϕ ( z ∣ x i ) ) \nabla H(q_\phi(z|x_i)) ∇H(qϕ(z∣xi))可看作对高斯分布的熵求导,即
若 p ( x ) = 1 ( 2 π σ 2 ) 1 2 e x p { − ( x − u ) 2 2 σ 2 } p(x)=\frac{1}{(2\pi\sigma^2)^{\frac{1}{2}}}exp\{{-\frac{(x-u)^2}{2\sigma^2}}\} p(x)=(2πσ2)211exp{−2σ2(x−u)2},则 H ( p ) = 1 2 ( l o g 2 ( π σ 2 ) + 1 ) H(p)=\frac{1}{2}\big(log2(\pi\sigma^2)+1\big) H(p)=21(log2(πσ2)+1),仅与方差相关。
∇ ϕ L i = ∇ J ( ϕ ) + ∇ H ( q ϕ ( z ∣ x i ) ) \nabla_\phi L_i=\nabla J(\phi)+\nabla H(q_\phi(z|x_i)) ∇ϕLi=∇J(ϕ)+∇H(qϕ(z∣xi))
( q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)拟合的是高斯分布的均值与方差,即 u ϕ , σ ϕ u_\phi,\sigma_\phi uϕ,σϕ)
- Reparameterization trick
J ( ϕ ) = E z ∼ q ϕ ( z ∣ x i ) [ r ( x i , z j ) ] = E ϵ ∼ N ( 0 , 1 ) [ r ( x i , u ϕ ( x i ) + ϵ σ ϕ ( x i ) ) ] \begin{aligned} J(\phi)&=E_{z\sim q_\phi(z|x_i)}\big[r(x_i,z_j)\big]\\ &=E_{\epsilon\sim N(0,1)}\big[r(x_i,u_\phi(x_i)+\epsilon\sigma_\phi(x_i))\big] \end{aligned} J(ϕ)=Ez∼qϕ(z∣xi)[r(xi,zj)]=Eϵ∼N(0,1)[r(xi,uϕ(xi)+ϵσϕ(xi))]
于是网络图如下:
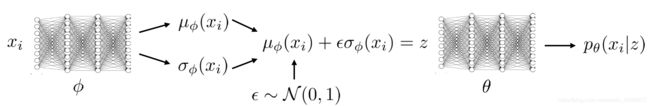
目标函数为:
max θ , ϕ 1 N ∑ i log p θ ( x i ∣ μ ϕ ( x i ) + ϵ σ ϕ ( x i ) ) − D K L ( q ϕ ( z ∣ x i ) ∥ p ( z ) ) \max _{\theta, \phi} \frac{1}{N} \sum_{i} \log p_{\theta}\left(x_{i} | \mu_{\phi}\left(x_{i}\right)+\epsilon \sigma_{\phi}\left(x_{i}\right)\right)-D_{\mathrm{KL}}\left(q_{\phi}\left(z | x_{i}\right) \| p(z)\right) θ,ϕmaxN1i∑logpθ(xi∣μϕ(xi)+ϵσϕ(xi))−DKL(qϕ(z∣xi)∥p(z))
这个就是Variational AutoEncoder,总体梳理可以参见CS236的总结文章中的VAE。
三、GAN
3.1 原始GAN
-
GAN的优化目标如下:
min θ max ϕ V ( G θ , D ϕ ) = E x ∼ p data [ log D ϕ ( x ) ] + E z ∼ p ( z ) [ log ( 1 − D ϕ ( G θ ( z ) ) ) ] \min _{\theta} \max _{\phi} V\left(G_{\theta}, D_{\phi}\right)=\mathbb{E}_{\mathbf{x} \sim \mathbf{p}_{\text {data }}}\left[\log D_{\phi}(\mathbf{x})\right]+\mathbb{E}_{\mathbf{z} \sim p(\mathbf{z})}\left[\log \left(1-D_{\phi}\left(G_{\theta}(\mathbf{z})\right)\right)\right] θminϕmaxV(Gθ,Dϕ)=Ex∼pdata [logDϕ(x)]+Ez∼p(z)[log(1−Dϕ(Gθ(z)))] -
对于判别器D的优化目标:
max D V ( G , D ) = E x ∼ p d a t a [ l o g D ( x ) ] + E x ∼ P G [ 1 − l o g D ( x ) ] = ∫ p d a t a ( x ) l o g D ( x ) + p G ( x ) ( 1 − l o g D ( x ) ) d x \begin{aligned} \max_{D}V(G,D)&=E_{x\sim p_{data}}\big[logD(x)\big]+E_{x\sim P_G}\big[1-logD(x)\big]\\ &=\int p_{data}(x)logD(x)+p_G(x)(1-logD(x))dx\\ \end{aligned} DmaxV(G,D)=Ex∼pdata[logD(x)]+Ex∼PG[1−logD(x)]=∫pdata(x)logD(x)+pG(x)(1−logD(x))dx固定G,优化D时, E x ∼ p d a t a [ l o g D ( x ) ] E_{x\sim p_{data}}\big[logD(x)\big] Ex∼pdata[logD(x)]将属于 p d a t a p_{data} pdata的样本 x x x尽可能判为正例,将属于 p G p_G pG的样本x尽可能判为负例。
对 D D D求导得最优判别器:
D ∗ ( x ) = p d a t a ( x ) p G ( x ) + p d a t a ( x ) D^*(x)=\frac{p_{data}(x)}{p_G(x)+p_{data}(x)} D∗(x)=pG(x)+pdata(x)pdata(x)说明最优的判别器,对一个样本 x x x,其属于G或者data的概率是一样的,则为 1 2 \frac{1}{2} 21。
代入生成器G的优化目标:
min G V ( G , D ) = E x ∼ p d a t a [ l o g p d a t a ( x ) p G ( x ) + p d a t a ( x ) ] + E x ∼ P G [ 1 − l o g p d a t a ( x ) p G ( x ) + p d a t a ( x ) ] = E x ∼ p d a t a [ l o g 2 p d a t a ( x ) p G ( x ) + p d a t a ( x ) ] + E x ∼ P G [ l o g 2 p d a t a ( x ) p G ( x ) + p d a t a ( x ) ] − 2 l o g 2 = 2 J S ( p d a t a ( x ) ∣ ∣ p G ( x ) ) − 2 l o g 2 \begin{aligned} \min_{G}V(G,D)&=E_{x\sim p_{data}}\big[log\frac{p_{data}(x)}{p_G(x)+p_{data}(x)}\big]+E_{x\sim P_G}\big[1-log\frac{p_{data}(x)}{p_G(x)+p_{data}(x)}\big]\\ &=E_{x\sim p_{data}}\big[log\frac{2p_{data}(x)}{p_G(x)+p_{data}(x)}\big]+E_{x\sim P_G}\big[log\frac{2p_{data}(x)}{p_G(x)+p_{data}(x)}\big]-2log2\\ &=2JS(p_{data}(x)||p_G(x))-2log2 \end{aligned} GminV(G,D)=Ex∼pdata[logpG(x)+pdata(x)pdata(x)]+Ex∼PG[1−logpG(x)+pdata(x)pdata(x)]=Ex∼pdata[logpG(x)+pdata(x)2pdata(x)]+Ex∼PG[logpG(x)+pdata(x)2pdata(x)]−2log2=2JS(pdata(x)∣∣pG(x))−2log2
最优的生成器就是 p G ( x ) = p d a t a ( x ) p_G(x)=p_{data}(x) pG(x)=pdata(x)即 J S ( p d a t a ( x ) ∣ ∣ p G ( x ) ) = 0 JS(p_{data}(x)||p_G(x))=0 JS(pdata(x)∣∣pG(x))=0
所以训练流程为:
-
从数据集 D D D中采样m个样本 x ( 1 ) , x ( 2 ) . . . , x ( m ) x^{(1)},x^{(2)}...,x^{(m)} x(1),x(2)...,x(m)
-
从隐变量先验分布 p ( z ) p(z) p(z)中采样m个noises z ( 1 ) , z ( 2 ) . . . , z ( m ) z^{(1)},z^{(2)}...,z^{(m)} z(1),z(2)...,z(m)
-
更新生成器 G G G参数: ∇ θ V ( G θ , D ϕ ) = 1 m ∇ θ ∑ i = 1 m l o g ( 1 − D ϕ ( G θ ( z ( i ) ) ) ) \nabla_\theta V(G_\theta,D_\phi)=\frac{1}{m}\nabla_\theta\sum_{i=1}^mlog(1-D_\phi(G_\theta(z^{(i)}))) ∇θV(Gθ,Dϕ)=m1∇θi=1∑mlog(1−Dϕ(Gθ(z(i))))
-
更新判别器 D D D参数: ∇ ϕ V ( G θ , D ϕ ) = 1 m ∇ ϕ ∑ i = 1 m [ l o g D ϕ ( x ( i ) ) + l o g ( 1 − D ϕ ( G θ ( z ( i ) ) ) ) ] \nabla_\phi V(G_\theta,D_\phi)=\frac{1}{m}\nabla_\phi\sum_{i=1}^m\Big[logD_\phi(x^{(i)})+log(1-D_\phi(G_\theta(z^{(i)})))\Big] ∇ϕV(Gθ,Dϕ)=m1∇ϕi=1∑m[logDϕ(x(i))+log(1−Dϕ(Gθ(z(i))))]
3.2 “-log D trick”的GAN
原始GAN在判别器D训练得比较好时,生成器G的优化目标变成:
min G V ( G , D ∗ ) = 2 J S ( p d a t a ( x ) ∣ ∣ p G ( x ) ) − 2 l o g 2 \min_{G}V(G,D^*)=2JS(p_{data}(x)||p_G(x))-2log2 GminV(G,D∗)=2JS(pdata(x)∣∣pG(x))−2log2
当 p d a t a p_{data} pdata与 p G p_G pG重叠部分可忽略时,会出现JS散度为常数,导致训练过程中的梯度消失现象。
于是把G的优化目标魔改一下:
min G V ( G , D ) = min G E x ∼ P G ( x ) [ l o g ( 1 − D ( x ) ) ] → min G E x ∼ P G ( x ) [ − l o g D ( x ) ] \min_{G}V(G,D)=\min_GE_{x\sim P_G(x)}\big[log(1-D(x))\big]\rightarrow \min_GE_{x\sim P_G(x)}\big[-logD(x)\big] GminV(G,D)=GminEx∼PG(x)[log(1−D(x))]→GminEx∼PG(x)[−logD(x)]
写得详细点的话如下:
min G V ( G , D ) = min G E z ∼ p ( z ) [ l o g ( 1 − D ϕ ( G θ ( z ) ) ) ] → min G E z ∼ p ( z ) [ − l o g D ϕ ( G θ ( z ) ) ] \min_{G}V(G,D)=\min_GE_{z\sim p(z)}\big[log(1-D_\phi(G_\theta(z)))\big]\rightarrow \min_GE_{z\sim p(z)}\big[-logD_\phi(G_\theta(z))\big] GminV(G,D)=GminEz∼p(z)[log(1−Dϕ(Gθ(z)))]→GminEz∼p(z)[−logDϕ(Gθ(z))]
固定 D D D,调整 θ \theta θ,使得生成出来的样本 x = G θ ( z ) x=G_\theta(z) x=Gθ(z),让优化目标 E z ∼ p ( z ) [ − l o g D ϕ ( G θ ( z ) ) ] E_{z\sim p(z)}\big[-logD_\phi(G_\theta(z))\big] Ez∼p(z)[−logDϕ(Gθ(z))]更小,即让 − l o g D ( x ) -logD(x) −logD(x)更小, D ( x ) D(x) D(x)更大,从而直观上使得G生成的样本尽可能让D判别为正例。
我们已知:
E x ∼ p d a t a [ l o g D ∗ ( x ) ] + E x ∼ p G ( x ) [ l o g ( 1 − D ∗ ( x ) ) ] = 2 J S ( p d a t a ( x ) ∣ ∣ p G ( x ) ) − 2 l o g 2 \begin{aligned} E_{x\sim p_{data}}\big[logD^*(x)\big]+E_{x\sim p_G(x)}\big[log(1-D^*(x))\big]=2JS(p_{data}(x)||p_G(x))-2log2\\ \end{aligned} Ex∼pdata[logD∗(x)]+Ex∼pG(x)[log(1−D∗(x))]=2JS(pdata(x)∣∣pG(x))−2log2
K L ( p G ∣ ∣ p d a t a ) = E x ∼ p G [ l o g p G ( x ) p d a t a ( x ) ] = E x ∼ p G [ l o g p G ( x ) p G ( x ) + p d a t a ( x ) p d a t a ( x ) p d a t a ( x ) + p G ( x ) ] = E x ∼ p G [ l o g 1 − D ∗ ( x ) D ∗ ( x ) ] = E x ∼ p G [ l o g ( 1 − D ∗ ( x ) ) ] + E x ∼ p G [ − l o g D ∗ ( x ) ] \begin{aligned} KL(p_G||p_{data})&=E_{x\sim p_G}\Big[log\frac{p_G(x)}{p_{data}(x)}\Big]\\ &=E_{x\sim p_G}\Big[log\frac{\frac{p_G(x)}{p_G(x)+p_{data}(x)}}{\frac{p_{data}(x)}{p_{data}(x)+p_G(x)}}\Big]\\ &=E_{x\sim p_G}\Big[log\frac{1-D^*(x)}{D^*(x)}\Big]\\ &=E_{x\sim p_G}\big[log(1-D^*(x))\big]+E_{x\sim p_G}\big[-logD^*(x)\big] \end{aligned} KL(pG∣∣pdata)=Ex∼pG[logpdata(x)pG(x)]=Ex∼pG[logpdata(x)+pG(x)pdata(x)pG(x)+pdata(x)pG(x)]=Ex∼pG[logD∗(x)1−D∗(x)]=Ex∼pG[log(1−D∗(x))]+Ex∼pG[−logD∗(x)]
所以更换G的目标函数后有:
min G V ( G , D ∗ ) = min G E x ∼ p G [ − l o g D ∗ ( x ) ] = min G K L ( p G ∣ ∣ p d a t a ) − E x ∼ p G [ l o g ( 1 − D ∗ ( x ) ) ] = min G K L ( p G ∣ ∣ p d a t a ) − [ 2 J S ( p d a t a ( x ) ∣ ∣ p G ( x ) ) − 2 l o g 2 − E x ∼ p d a t a [ l o g D ∗ ( x ) ] ] ≡ min G K L ( p G ∣ ∣ p d a t a ) − 2 J S ( p d a t a ( x ) ∣ ∣ p G ( x ) ) ( 最 后 两 项 与 G 无 关 ) \begin{aligned} \min_GV(G,D^*)&=\min_GE_{x\sim p_G}\big[-logD^*(x)\big]\\ &=\min_GKL(p_G||p_{data})-E_{x\sim p_G}\big[log(1-D^*(x))\big]\\ &=\min_GKL(p_G||p_{data})-\Big[2JS(p_{data}(x)||p_G(x))-2log2-E_{x\sim p_{data}}\big[logD^*(x)\big]\Big]\\ &\equiv \min_GKL(p_G||p_{data})-2JS(p_{data}(x)||p_G(x)) (最后两项与G无关) \end{aligned} GminV(G,D∗)=GminEx∼pG[−logD∗(x)]=GminKL(pG∣∣pdata)−Ex∼pG[log(1−D∗(x))]=GminKL(pG∣∣pdata)−[2JS(pdata(x)∣∣pG(x))−2log2−Ex∼pdata[logD∗(x)]]≡GminKL(pG∣∣pdata)−2JS(pdata(x)∣∣pG(x))(最后两项与G无关)
于是对于第二种目标函数,在D比较优的情况下:
- 第一项最小化 K L ( p G ∣ ∣ p d a t a ) KL(p_G||p_{data}) KL(pG∣∣pdata)将生成器G拉近 p d a t a p_{data} pdata
- 第二项最小化 − J S ( p d a t a ( x ) ∣ ∣ p G ( x ) ) -JS(p_{data}(x)||p_G(x)) −JS(pdata(x)∣∣pG(x))将生成器G推远 p d a t a p_{data} pdata
所以这种情况下会出现梯度不稳定,而且
- 对于一个G生成的样本 x x x而言,当 p G ( x ) → 0 , p d a t a ( x ) → 1 p_G(x)\rightarrow0,p_{data}(x)\rightarrow1 pG(x)→0,pdata(x)→1时, K L ( p G ∣ ∣ p d a t a ) → 0 KL(p_G||p_{data})\rightarrow0 KL(pG∣∣pdata)→0。说明明明G生成了一个很接近真实分布的 x x x,但是当前G还很差,使得 p G ( x ) p_G(x) pG(x)接近0,此时这个目标函数竟然接近0!这对G的参数 θ \theta θ几乎没改变。概括为“该优化目标会使得G没能生成真实样本”。
- 对于一个G生成的样本 x x x而言,当 p G ( x ) → 1 , p d a t a ( x ) → 0 p_G(x)\rightarrow1,p_{data}(x)\rightarrow0 pG(x)→1,pdata(x)→0时, K L ( p G ∣ ∣ p d a t a ) → + ∞ KL(p_G||p_{data})\rightarrow+\infty KL(pG∣∣pdata)→+∞。说明此时G生成了一个很符合自身的样本 x x x,但几乎不可能属于真实分布 p d a t a p_{data} pdata,然而目标函数很大!概括为“该优化目标使得G生成了不真实的样本”
所以这种情况下会出现多样性不足即mode collapse的问题。
具体参考郑华滨的知乎文章
小结
上面是两种最原始的GAN,最核心的思想是G与D的对抗性训练,使G具备生成众多样本的特性。
这种对抗性训练也是IRL中的核心思想。
由最原始GAN的问题,由此衍生了一系列GAN的变种以及训练技巧,具体可参见下两个资料。
GAN Zoo Github
Tricks To Train GAN