机器学习模型自我代码复现:使用numpy复现GRU
根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述。
如文中或代码有错误或是不足之处,还望能不吝指正。
由于GRU的过程较为复杂,使用XMind画了一张图作为原理上的参考。
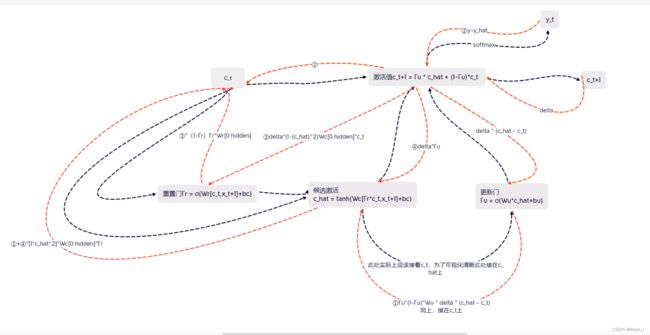
GRU属于RNN的一类,使用门控在一定程度上抑制了梯度消失的问题。在实际实现时,由于没有精力在数学层面上进行优化,这里使用梯度裁剪以及LayerNormalization以避免梯度爆炸以及过拟合。
代码:
import numpy as np
# from mxnet import nd
# import minpy.numpy as np
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
import math
from visdom import Visdom
import datetime
from collections import dequemnist_train = datasets.MNIST('mnist_data',train=True,transform=transforms.Compose(
[transforms.Resize((28,28)),
transforms.ToTensor()]
),download = False)
mnist_test = datasets.MNIST('mnist_data',train=False,transform=transforms.Compose(
[transforms.Resize((28,28)),
transforms.ToTensor()]
),download = False)
train_loader = DataLoader(mnist_train,batch_size=512,shuffle=True)
test_loader = DataLoader(mnist_train,batch_size=512,shuffle=True)class Clip_Gradient:
"""
通过范数梯度裁剪,
参考:https://blog.csdn.net/qq_40035462/article/details/123312774
"""
def __init__(self):
pass
def clip(self,x,c=100):
norm = np.linalg.norm(np.stack([np.linalg.norm(i.flatten()) for i in delta]))
clip_coef = c/(max(norm,c)+1e-6)
return x*clip_coefclass LayerNorm:
def __init__(self):
self.gamma = 1
self.beta = 0
def forward(self,x):
self.x = x
self.mu = np.mean(x,axis=1)
self.var = np.var(x,axis=1)
self.mu = self.mu.reshape(x.shape[0],1)
self.var = self.var.reshape(x.shape[0],1)
self.x_hat = (x-self.mu)/np.sqrt(self.var+1e-6)
self.y = self.gamma*self.x_hat+self.beta
return self.y
def backward(self,delta,lr=1e-3):
loss_to_hat = self.gamma*delta
hat_to_xi = 1/np.sqrt(self.var+1e-8)
hat_to_var = -(1/2)*(self.x-self.mu)*np.power(self.var+1e-6,-2/3)
var_to_xi = 2*(1/self.x.shape[0])*(self.x-self.mu)
hat_to_mu = -1/np.sqrt(self.var+1e-8)
var_to_mu = -2*(1/self.x.shape[0])*(self.x-self.mu)
mu_to_xi = 1/self.x.shape[0]
self.res = loss_to_hat*hat_to_xi+loss_to_hat*hat_to_var*var_to_xi+(loss_to_hat*hat_to_mu+loss_to_hat*hat_to_var*var_to_mu)*mu_to_xi
self.loss_to_gamma = np.sum(delta*self.x_hat)
self.loss_to_beta = np.sum(delta)
# self.gamma -= lr*self.loss_to_gamma
# self.beta -= lr*self.loss_to_beta
return self.resclass GRU:
def __init__(self,input_size,hidden_size,AddLayerNorm=True):
"""
初始化以下内容:
self.input_size:输入feature的大小
self.hidden_size:隐层大小
self.weights_c:用以激活c_hat的权重
self.weights_r:用以计算gamma_r的权重
self.weights_u:用以计算gamma_u的权重
self.bias_c:用以激活c_hat的偏置
self.bias_r:用以计算gamma_r的偏置
self.bias_u:用以计算gamma_u的偏置
self.c_t_1_list:用以保存每一个c_t_1,此处使用list;但是使用栈应该也可以
self.gamma_r_list:保存gamma_r
self.c_t_hat_list:保存c_t_hat
self.gamma_u_list:保存gamma_u
self.c_t_list:保存c_t
self.LNS:保存每一个c_t状态下的LayerNorm层
"""
self.input_size = input_size
self.hidden_size = hidden_size
self.weights_c = np.random.normal(0,1,(hidden_size+input_size,hidden_size))
self.weights_r = np.random.normal(0,1,(hidden_size+input_size,hidden_size))
self.weights_u = np.random.normal(0,1,(hidden_size,hidden_size))
self.bias_c = np.random.normal(0,1,(hidden_size,))
self.bias_r = np.random.normal(0,1,(hidden_size,))
self.bias_u = np.random.normal(0,1,(hidden_size,))
self.c_t_1_list = []
self.gamma_r_list = []
self.c_t_hat_list = []
self.gamma_u_list = []
self.c_t_list = []
self.AddLayerNorm = AddLayerNorm
if AddLayerNorm:
self.LNS = []
def sigmoid(self,x):
return 1.0/(1.0+np.exp(-x))
def forward(self,x_t):
"""
输入x_t:[bsize,feature],其中1个seq的正向传播
"""
bsize = x_t.shape[0]
#重置门
self.c_t_1_x = self.ct
self.c_t_1_x = self.c_t_1_x.reshape((bsize,self.hidden_size))
c_t_m = np.concatenate([self.c_t_1_x,x_t],axis=1)
self.gamma_r = self.sigmoid(np.dot(c_t_m,self.weights_r)+self.bias_r)
#候选激活值
c_t_m = np.concatenate([self.gamma_r*self.c_t_1_x,x_t],axis=1)
self.c_t_hat = np.tanh(np.dot(c_t_m,self.weights_c)+self.bias_c)
#更新门
self.gamma_u = self.sigmoid(np.dot(self.c_t_hat,self.weights_u)+self.bias_u)
#激活值
self.c_t = (1-self.gamma_u)*self.c_t_1_x+self.gamma_u*self.c_t_hat
self.c_t_1_list.append(self.c_t_1_x)
self.gamma_r_list.append(self.gamma_r)
self.c_t_hat_list.append(self.c_t_hat)
self.gamma_u_list.append(self.gamma_u)
self.c_t_list.append(self.c_t)
#加入layerNorm层
if self.AddLayerNorm:
if len(self.LNS)class Linear:
def __init__(self,input_size,output_size):
self.input_size = input_size
self.output_size = output_size
self.weight = np.random.normal(0,1,(input_size,output_size))
self.bias = np.random.normal(0,1,(output_size,))
def forward(self,x):
self.x = x
return np.dot(x,self.weight)+self.bias
def backward(self,delta,act=None,lr=0.01):
if act is not None:
d_act=act.backward(act.res)
delta *= d_act
w_grad = np.dot(self.x.T,delta)
b_grad = np.sum(delta,axis=0)
res = np.dot(delta,self.weight.T)
self.weight -= w_grad*lr
self.bias -= b_grad*lr
return resclass Softmax:
def __init__(self):
pass
def forward(self,x):
x = x.T
m = np.max(x,axis=0)
t = np.exp((x-m.T))#防溢出
s = np.sum(t,axis=0)
self.res = t/s
self.res = self.res.T
return self.res
def backward(self,delta):
d=np.zeros(self.res[0].shape)
#print(d.shape)
for i in range(delta.shape[0]):
yiyj = np.outer(self.res[i],self.res[i])
soft_grad = np.dot(np.diag(self.res[i])-yiyj,delta[i].T)
d = np.vstack([d,soft_grad])
#print(d)
return d[1:]class Sigmoid:
def __init__(self):
pass
def forward(self,x):
self.res = 1.0/(1.0+np.exp(-x))
return self.res
def backward(self,delta):
return delta*(1-delta)class CrossEntropy:
def __init__(self,num_classes):
self.num_classes = num_classes
def forward(self,pred,label):
label = np.eye(self.num_classes)[label]
loss = -np.sum(label*np.log(pred))
delta = -label/pred
return loss,deltaclass Net:
def __init__(self):
self.GRU = GRU(28,64,AddLayerNorm=False)
self.Linear1 = Linear(64,30)
self.sigmoid = Sigmoid()
self.Linear2 = Linear(30,10)
self.softmax = Softmax()
self.loss_fn = CrossEntropy(num_classes=10)
def forward(self,x):
x = self.GRU.forward_m(x)
x = self.Linear1.forward(x)
x = self.sigmoid.forward(x)
#print("方差最大为",np.max(np.abs(np.var(x,axis=1))))
x = self.Linear2.forward(x)
logits = self.softmax.forward(x)
return logits
def calc_loss(self,pred,y):
loss,delta = self.loss_fn.forward(pred,y)
return loss,delta
def train(self,x,y):
pred = self.forward(x)
self.loss,self.delta = self.calc_loss(pred,y)
self.backward(self.delta)
return self.loss
def backward(self,delta):
delta = self.softmax.backward(delta)
delta = self.Linear2.backward(delta,lr=0.001)
delta = self.Linear1.backward(delta,act=self.sigmoid,lr=0.001)
d = self.GRU.backward_m(delta,lr=0.001)
#print(np.sum(d))net = Net()
visdom = Visdom()for epoch in range(1000):
# loss = 0
# ttl = 0
for bidx,(x,y) in enumerate(train_loader):
x = x.view(-1,28,28)
x = np.array(x)
y = np.array(y)
loss = net.train(x,y)
ttl=x.shape[0]
if ttl_step%100 == 0 and ttl_step>0:
visdom.line([np.mean(loss)],[ttl_step],win="train_loss",update="append",
opts = dict(title="训练集上的损失值"))
ttl_step+=1
#if epoch % 5 == 0:
corr = 0
ttl = 0
for bidx,(x,y) in enumerate(test_loader):
x = x.view(-1,28,28)
x = np.array(x)
y = np.array(y)
pred = net.forward(x)
pred = np.argmax(pred,axis=1)
corr += np.sum(np.equal(pred,y))
ttl += x.shape[0]
print("epoch:",epoch,"的测试集上准确率:",corr/ttl)结果:
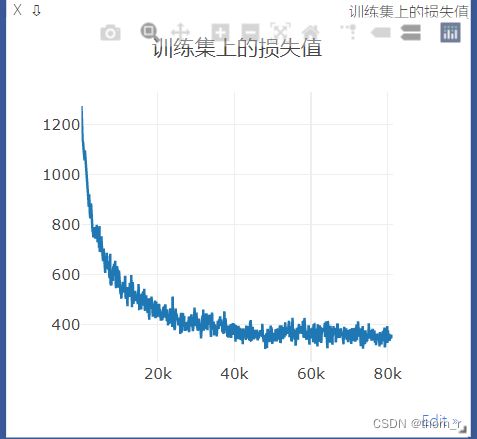
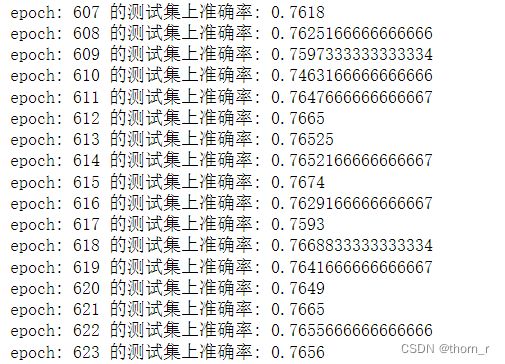
最终测试集上的准确率稳定在了0.76左右;手写的gru还有优化空间,作为小练手这个结果聊胜于无。