bert中的sep_BERT 详解
bert 是什么?

BERT(Bidirectional Encoder Representations from Transformers) 是一个语言表示模型(language representation model)。它的主要模型结构是trasnformer的encoder堆叠而成,它其实是一个2阶段的框架,分别是pretraining,以及在各个具体任务上进行finetuning。 pretaining阶段需要大量的数据,以及大量的计算机资源,所以google开源了多国的语言预训练模型,我们可以直接在这个基础上进行finetune。
bert 能干什么
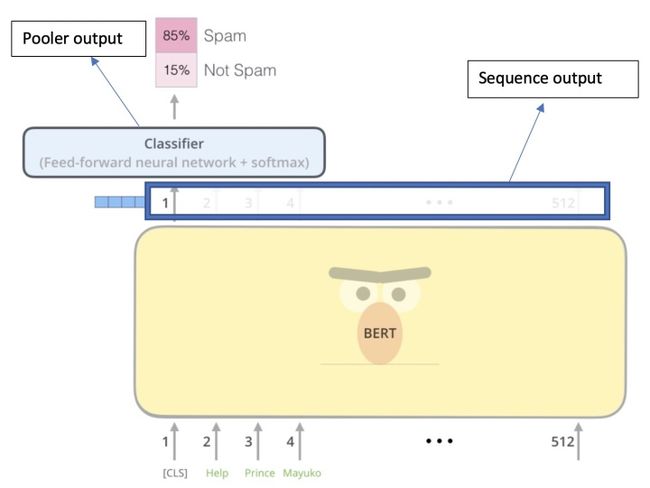
首先我们可以看到BERT 具有两种输出,一个是pooler output,对应的[CLS]的输出,以及sequence output,对应的是序列中的所有字的最后一层hidden输出。所以BERT主要可以处理两种,一种任务是分类/回归任务(使用的是pooler output),一种是序列任务(sequence output)。
- 分类任务
- Single Sentence Classification tasks
例如:文本分类,我想听音乐,分到音乐这个domain

- Sentence Pair Classification tasks 例如:自然语言推断任务(NLI),给定前提,推断假设是否成立

- 回归任务 回归任务其实是分类任务的一种特殊形式,最后的输出是一个数值而不是具体的某个类别的概率。
- 具体任务例如:文本相似度,可以判断两个句子是不是类似的,得到具体的分数。
- 序列任务
- 命名实体识别(NER)
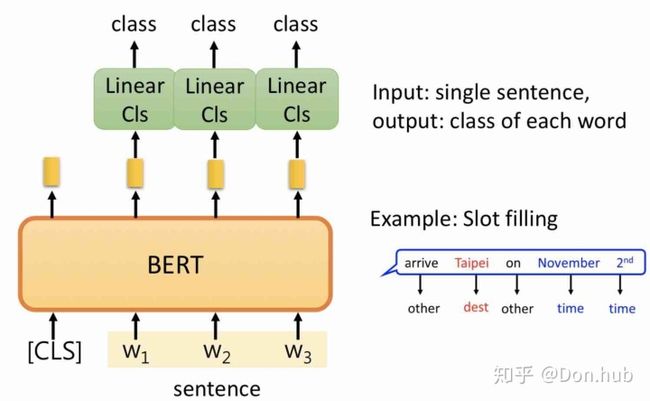
- Cloze task(完形填空)其实这就是bert预训练的一种任务。
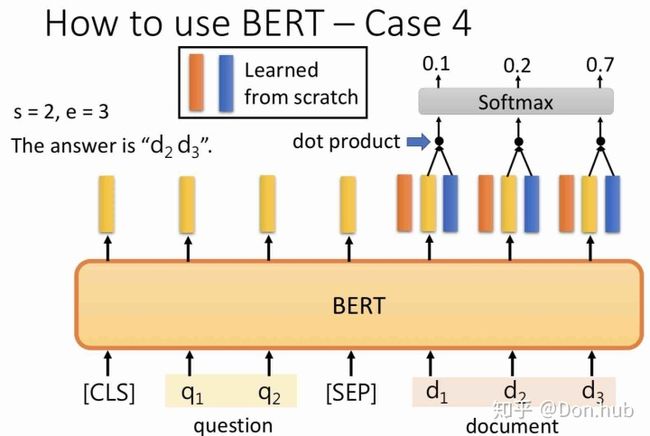
- SQuAD(Standford Question Answering Dataset) task

SQuAD任务传入的是
具体做法是:我们学习两个向量,分别是

为什么要用bert
首先我们从General Language Understanding Evaluation (GLUE) benchmark leaderboard 数据来源日期2020/01/01。
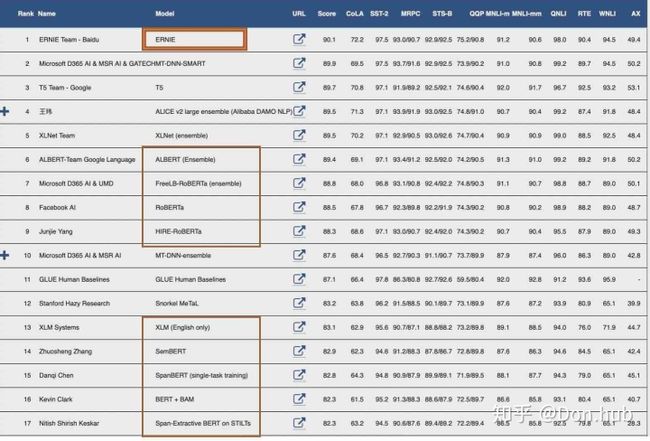
我们可以看到屠榜的模型绝大部分都是BERT based。 另外它的出现,也直接带动了pretrain+finetune的预训练模型的时代。它的预训练模型的使得模型只需要少数的训练数据就可以得到非常好的效果。 此外它是第一个将双向网络和finetuning结合的模型。(虽然finetuning和pretraining在Unifit提出,然后统一下游框架是GPT提出的,但是双向的网络是BERT提出)
bert模型结构解析

模型可以简单的归纳为三个部分,分别是输入层,中间层,以及输出层。这些都和transformer的encoder一致,除了输入层有略微变化
输入层

为了使得BERT模型适应下游的任务(比如说分类任务,以及句子关系QA的任务),输入将被改造成[CLS]+句子A(+[SEP]+句子B+[SEP]) 其中
- [CLS]: 代表的是分类任务的特殊token,它的输出就是模型的pooler output
- [SEP]:分隔符
- 句子A以及句子B是模型的输入文本,其中句子B可以为空,则输入变为[CLS]+句子A
因为trasnformer无法获得字的位置信息,BERT和transformer一样也加入了 绝对位置 position encoding,但是和transformer不同的是,BERT使用的是不是transformer对应的函数型(functional)的encoding方式,而是直接采用类似word embedding的方式(Parametric),直接获得position embedding。
因为我们对输入进行了改造,使得模型可能有多个句子Segment的输入,所以我们也需要加入segment的embedding,例如[CLS], A_1, A_2, A_3,[SEP], B_1, B_2, B_3, [SEP] 对应的segment的输入是[0,0,0,0,1,1,1,1], 然后在根据segment id进行embedding_lookup得到segment embedding。 code snippet如下。
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
tokens.append("[SEP]")
segment_ids.append(1)输入层为三个embedding相加(position embedding + segment embedding + token embedding)这是为什么?
我们简单地假设我们有一个token,我们假设我们的字典大小(vocabulary_size) = 5, 对应的的token_id 是2,这个token所在的位置是第0个位置,我们最大的位置长度为max_position_size = 6,以及我们可以有两种segment,这个token是属于segment = 0的情况。
首先我们分别对三种不同类型的分别进行 embedding lookup的操作,下面的代码中我们,固定了三种类型的embedding matrix,分别是token_embedding,position_embedding,segment_embedding。首先我们要清楚,正常的embedding lookup就是embedding id 进行onehot之后,然后在和embedding matrix 进行矩阵相乘,具体看例子中的 embd_embd_onehot_impl 和 embd_token,这两个的结果是一致的。
我们分别得到了三个类别数据的embedding之后(embd_token, embd_position, embd_sum),再将它们进行相加,得到embd_sum。
其结果跟,将三个类别进行onehot之后的结果concat起来,再进行embedding lookup的结果是一致的。比如下面,我们将token_id_onehot, position_id_onehot, segment_id_onehot 这三个onehot后的结果concat起来得到concat_id_onehot, 与三者的embedding matrix的concat后的结果concat_embedding,进行矩阵相乘,得到的结果 embd_cat。
可以发现 embd_sum == embd_cat。 具体参照下面代码。
import tensorflow as tf
token_id = 2
vocabulary_size = 5
position = 0
max_position_size = 6
segment_id = 0
segment_size = 2
embedding_size = 4
token_embedding = tf.constant([[-3.,-2,-1, 0],[1,2,3,4], [5,6,7,8], [9,10, 11,12], [13,14,15,16]]) #size: (vocabulary_size, embedding_size)
position_embedding = tf.constant([[17., 18, 19, 20], [21,22,23,24], [25,26,27,28], [29,30,31,32], [33,34,35,36], [37,38,39,40]]) #size:(max_position_size, embedding_size)
segment_embedding = tf.constant([[41.,42,43,44], [45,46,47,48]]) #size:(segment_size, embedding_size)
token_id_onehot = tf.one_hot(token_id, vocabulary_size)
position_id_onehot = tf.one_hot(position, max_position_size)
segment_id_onehot = tf.one_hot(segment_id, segment_size)
embd_embd_onehot_impl = tf.matmul([token_id_onehot], token_embedding)
embd_token = tf.nn.embedding_lookup(token_embedding, token_id)
embd_position = tf.nn.embedding_lookup(position_embedding, position)
embd_segment = tf.nn.embedding_lookup(segment_embedding, segment_id)
embd_sum = tf.reduce_sum([embd_token, embd_position, embd_segment], axis=0)
concat_id_onehot = tf.concat([token_id_onehot, position_id_onehot, segment_id_onehot], axis=0)
concat_embedding = tf.concat([token_embedding, position_embedding, segment_embedding], axis=0)
embd_cat = tf.matmul([concat_id_onehot], concat_embedding)
with tf.Session() as sess:
print(sess.run(embd_embd_onehot_impl)) # [[5. 6. 7. 8.]]
print(sess.run(embd_token)) # [5. 6. 7. 8.]
print(sess.run(embd_position)) # [17. 18. 19. 20.]
print(sess.run(embd_segment)) # [41. 42. 43. 44.]
print(sess.run(embd_sum)) # [63. 66. 69. 72.]
print(sess.run(concat_embedding))
'''
[[-3. -2. -1. 0.]
[ 1. 2. 3. 4.]
[ 5. 6. 7. 8.]
[ 9. 10. 11. 12.]
[13. 14. 15. 16.]
[17. 18. 19. 20.]
[21. 22. 23. 24.]
[25. 26. 27. 28.]
[29. 30. 31. 32.]
[33. 34. 35. 36.]
[37. 38. 39. 40.]
[41. 42. 43. 44.]
[45. 46. 47. 48.]]
[[63. 66. 69. 72.]]
'''
print(sess.run(concat_id_onehot)) # [0. 0. 1. 0. 0. 1. 0. 0. 0. 0. 0. 1. 0.]
print(sess.run(embd_cat)) # [[63. 66. 69. 72.]]
中间层
模型的中间层和transformer的encoder一样,都是由self-attention layer + ADD&BatchNorm layer + FFN 层组成的。

输出层

模型的每一个输入都对应这一个输出,根据不同的任务我们可以选择不同的输出,主要有两类输出
- pooler output:对应的是[CLS]的输出。
- sequence output:对应的是所有其他的输入字的最后输出。
BERT 框架
BERT提出的是一个框架,主要由两个阶段组成。分别是Pre-training以及Fine-Tuning。

Pre-training
语言预训练模型的主要是采用大量的训练预料,然后作无监督学习。
- BERT模型的目标: 传统的语言模型就是预测下一个词,例如我们键盘的输入法。一般采用的是从左到右的顺序。但是这就限制了模型的能力,不能考虑到后面的序列的信息。如果要考虑双向的信息的话,可以再使用从右到左的顺序,预测下一个词,然后再将两个模型融合,这样子就考虑到了双向的信息(这个是ELMO的做法)。但是这样做有个的坏处主要是,
- 首先参数量变成了之前单向的两倍,也是直接考虑双向的两倍
- 而且这个对于某些任务,例如QA任务不合理,因为我们不能够考虑完答案再考虑问题
- 这比直接考虑双向模型更差,因为双向模型能够在同一个layer中直接考虑左边和右边的context code 参考
task-1: Mask Language Model(MLM)
所以BERT采用了双向的语言模型的方式,但是这个如果采用双向的话,就不可以采用预测下一个词的方式了,因为模型会看到要预测的值。所以BERT第一次采用了mask language model(MLM)任务,这就类似于完形填空(Cloze task)。
具体的做法: 我们会随机mask输入的几个词,然后预测这个词。但是这样子做的坏处是因为fine-tuning阶段中并没有[MASK] token,所以导致了pre-training 和 fine-tuning的不匹配的情况。所以为了减轻这个问题,文章中采用的做法是:对于要MASK 15%的tokens,
- (1) 80%的情况是替换成[MASK]
- (2) 10%的情况是替换为随机的token
- (3) 10%的情况是保持不变 具体的code snippet如下。
for index in cand_indexes:
if len(masked_lms) >= num_to_predict: # 15% of total tokens
break
...
masked_token = None
# 80% of the time, replace with [MASK]
if rng.random() < 0.8:
masked_token = "[MASK]"
else:
# 10% of the time, keep original
if rng.random() < 0.5:
masked_token = tokens[index]
# 10% of the time, replace with random word
else:
masked_token = vocab_words[rng.randint(0, len(vocab_words) - 1)]
output_tokens[index] = masked_token注意,这边的token的level是采用Byte Pair Encoding (BPE)生成word piece级别的,什么是word piece呢,就是一个subword的编码方式,经过WordpieceTokenizer 之后,将词变为了word piece, 例如:
# input = "unaffable"
# output = ["un", "##aff", "##able"]这样子的好处是,可以有效的解决OOV的问题,但是mask wordpiece的做法也被后来(ERNIE以及SpanBERT等)证明是不合理的,没有将字的知识考虑进去,会降低精度,于是google在此版的基础上,进行Whole Word Masking(WWM)的模型。需要注意的是,中文的每个字都是一个word piece,所以WWM的方法在中文中,就是MASK一个词组,参考论文。
task#2: Next sentence order(NSP)
为了适配下游任务,使得模型懂得句子之间的关系,BERT加了一个新的训练任务,预测两个句子是不是下一句的关系。
具体来说:50%的概率,句子A和句子B是来自同一个文档的上下句,标记为is_random_next=False, 50%的概率,句子A和句子B不是同一个文档的上下句,具体的做法就是,采用从其他的文档(document)中,加入新的连续句子(segments)作为句子B。具体参考create_instances_from_document函数。
首先我们会有一个all_documents存储所有的documents,每个documents是由句子segemnts组成的,每个segment是由单个token组成的。我们首先初始化一个chunk数组,每次都往chunk中添加同一个document中的一个句子,当chunk的长度大于target的长度(此处target的长度一般是max_seq_length,但是为了匹配下游任务,target的长度可以设置一定比例short_seq_prob的长度少于max_seq_length)的时候,随机选择一个某个句子作为分割点,前面的作为句子A,后面的作为句子B。 chunk = [Sentence1, Sentence2,..., SentenceN], 我们随机选择选择一个句子作为句子A的结尾,例如2作为句子结尾,则句子A为=[Sentence1, Sentence2]。我们有50%的几率选择剩下的句子[Sentence3,...SentenceN]作为句子B,或者50%的几率时的句子B是从其他文档中的另外多个句子。
这时候可能会导致我们的训练样本的总长度len(input_ids)大于或者小于我们的需要的训练样本长度max_seq_length。
- 如果
len(input_ids) > max_seq_length, 具体的做法是分别删除比较长的一个句子中的头(50%)或尾(50%)的token
```Python
def truncate_seq_pair(tokens_a, tokens_b, max_num_tokens, rng):
"""Truncates a pair of sequences to a maximum sequence length."""
while True:
total_length = len(tokens_a) + len(tokens_b)
if total_length <= max_num_tokens:
break
trunc_tokens = tokens_a if len(tokens_a) > len(tokens_b) else tokens_b
assert len(trunc_tokens) >= 1
# We want to sometimes truncate from the front and sometimes from the
# back to add more randomness and avoid biases.
if rng.random() < 0.5:
del trunc_tokens[0]
else:
trunc_tokens.pop()
```- 如果
len(input_ids) < max_seq_length, 采用的做法是补0。
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)根据我们的两个任务,我们预训练模型的输入主要由以下7个特征组成。
input_ids: 输入的token对应的idinput_mask: 输入的mask,1代表是正常输入,0代表的是padding的输入segment_ids: 输入的0:代表句子A或者padding句子,1代表句子Bmasked_lm_positions:我们mask的token的位置masked_lm_ids:我们mask的token的对应idmasked_lm_weights:我们mask的token的权重,1代表是真实mask的,0代表的是padding的masknext_sentence_labels:句子A和B是否是上下句
features = collections.OrderedDict()
features["input_ids"] = create_int_feature(input_ids)
features["input_mask"] = create_int_feature(input_mask)
features["segment_ids"] = create_int_feature(segment_ids)
features["masked_lm_positions"] = create_int_feature(masked_lm_positions)
features["masked_lm_ids"] = create_int_feature(masked_lm_ids)
features["masked_lm_weights"] = create_float_feature(masked_lm_weights)
features["next_sentence_labels"] = create_int_feature([next_sentence_label])Fine-Tuning
在Fine-Tuning阶段的时候,我们可以简单的plugin任务特定的输入和输出,作为训练。 例如:
- 2句子 pairs: 相似度任务,
- 假设-前提 pairs: 推理任务,
- 问题-文章 pairs : QA任务
-
pair: 文本分类 or 序列标注.
[CLS] representation 被喂到 最后一层作为classification的结果例如 推理任务或者 情感分析任务。
在这个任务中,就不需要MLM任务以及NSP任务所需要的输入了,所以就只有固定输入features(input_ids, input_mask, segment_ids)以及任务特定features
例如分类任务的输入特征:
input_ids: 输入的token对应的idinput_mask: 输入的mask,1代表是正常输入,0代表的是padding的输入segment_ids: 输入的0:代表句子A或者padding句子,1代表句子Blabel_ids:输入的样本的label
features["input_ids"] = create_int_feature(feature.input_ids)
features["input_mask"] = create_int_feature(feature.input_mask)
features["segment_ids"] = create_int_feature(feature.segment_ids)
features["label_ids"] = create_int_feature([feature.label_id])bert源码解析
源码地址, bert的源码的结构主要为(部分删减):
├── chinese_L-12_H-768_A-12 # 中文的预训练模型
│ ├── bert_config.json # 配置文件
│ ├── bert_model.ckpt.data-00000-of-00001 # 模型文件
│ ├── bert_model.ckpt.index # 模型文件
│ ├── bert_model.ckpt.meta # 模型文件1
│ └── vocab.txt # 模型字典
├── sample_text.txt # 预训练的语料
├── create_pretraining_data.py # 将预训练的语料转换为训练所需数据
├── run_pretraining.py # 进行预训练的脚本
├── modeling.py # 模型结构脚本
├── run_classifier.py # 分类任务脚本
├── run_squad.py # SQuAD QA任务脚本
├── extract_features.py # 提取bert特征脚本,这里的特征指的是模型的所有层的输出特征,不止是最后一层为什么要懂得bert的源码?因为你一下子懂得了很多其他基于bert改进模型的源码,例如说Albert,Roberta,XLM等模型的代码。
PreTraining
首先我们在进行模型预训练的时候,我们需要准备训练数据,类似repo中的sample_text.txt。 我们首先来看Pretraining,我们需要准备训练数据,这里只是为了阅读代码,因此我们准备很少的数据就行。它的格式类似于:
准备数据
当然上面的数据也太少了点,读者可以把这些内容复制个几百次。我们简单的介绍训练数据的格式。每一行代表一个句子。如一个空行代表一个新的文档(document)的开始,一篇文档可以包括多个段落(paragraph),我们可以在一个段落的最后加一个表示这个段落的结束(和新段落的开始)。
This is the first sentence.
This is the second sentence and also the end of the paragraph.
Another paragraph.
Another document starts here. 比如上面的例子,总共有两篇文档,第一篇3个句子,第二篇1个句子。而第一篇的三个句子又分为两个段落,前两个句子是一个段落,最后一个句子又是一个段落。
运行create_pretraining_data.py 得到训练数据。
由于数据会被一次性加载在进内存,进行转化成tfrecord的格式,所以数据不宜过大,只要最后输出存在一个文件夹下即可。如果我们有1000万个文档要训练,那么我们可以把这1000万文档拆分成1万个文件,每个文件中放入1000个文档,从而生成10000个TFRecord文件。
运行脚本如下:
python create_pretraining_data.py
--input_file=./sample_text.txt
--output_file=/tmp/tf_examples.tfrecord
--vocab_file=$BERT_BASE_DIR/vocab.txt
--do_lower_case=True
--max_seq_length=128
--max_predictions_per_seq=20
--masked_lm_prob=0.15
--random_seed=12345
--dupe_factor=5max_seq_length Token序列的最大长度max_predictions_per_seq最多生成多少个MASKmasked_lm_prob多少比例的Token变成MASKdupe_factor一个文档重复多少次
首先说一下参数dupe_factor,比如一个句子”it is a good day”,为了充分利用数据,我们可以多次随机的生成MASK,比如第一次可能生成”it is a [MASK] day”,第二次可能生成”it [MASK] a good day”。这个参数控制重复的次数。 详细参考解析
大体的框架如下:
def main(_):
tokenizer = tokenization.FullTokenizer(
vocab_file=FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case)
input_files = []
# 省略了文件通配符的处理,我们假设输入的文件已经传入input_files
rng = random.Random(FLAGS.random_seed)
instances = create_training_instances(
input_files, tokenizer, FLAGS.max_seq_length, FLAGS.dupe_factor,
FLAGS.short_seq_prob, FLAGS.masked_lm_prob, FLAGS.max_predictions_per_seq,
rng)
output_files = ....
write_instance_to_example_files(instances, tokenizer, FLAGS.max_seq_length,
FLAGS.max_predictions_per_seq, output_files)假设我们的max_seq_length=15, masked_lm_prob=0.2, max_predictions_per_seq=2 我们的写入tfrecord的文本的格式就类似如下,因为我们的句子A(7个token)和句子B(6个token)加起来只有13,所以需要padding2个token。max_seq_length* masked_lm_prob=3 > max_predictions_per_seq=2, 所以只mask两个
1. tokens = ["[CLS], "it", "is" "a", "[MASK]", "day", "[SEP]", "I", "apple", "to", "go", "out", "[SEP]", 0,0]
2. input_mask = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0] # 13 个1 ,2 个0 表示最后两个是padding的
3. segment_ids=[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0] # 前7个0表示句子A,后6个表示句子B,最后两个是padding
4. is_random_next=False
5. masked_lm_positions=[4, 8]
#表示Mask后为["[CLS], "it", "is" "a", "[MASK]", "day", "[SEP]", "I", "[MASK]", "to", "go", "out", "[SEP]"]
6. masked_lm_weights=[1, 1] # 表示前2个是真正mask的被mask的,长度=len(masked_lm_positions), 如果有的mask的token是padding,则weigjt = 0。
7. masked_lm_labels=["good", "want"]运行run_pretraining.py 进行预训练
python run_pretraining.py
--input_file=/tmp/tf_examples.tfrecord
--output_dir=/tmp/pretraining_output
--do_train=True
--do_eval=True
--bert_config_file=$BERT_BASE_DIR/bert_config.json
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt
--train_batch_size=32
--max_seq_length=128
--max_predictions_per_seq=20
--num_train_steps=20
--num_warmup_steps=10
--learning_rate=2e-5参数都比较容易理解,通常我们需要调整的是num_train_steps、num_warmup_steps和learning_rate。
def model_fn(features, labels, mode, params):
省略...
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
(masked_lm_loss,
masked_lm_example_loss, masked_lm_log_probs) = get_masked_lm_output(
bert_config, model.get_sequence_output(), model.get_embedding_table(),
masked_lm_positions, masked_lm_ids, masked_lm_weights)
(next_sentence_loss, next_sentence_example_loss,
next_sentence_log_probs) = get_next_sentence_output(
bert_config, model.get_pooled_output(), next_sentence_labels)
total_loss = masked_lm_loss + next_sentence_loss # 多任务学习
"""
其实就是
1。 将需要计算mask的词的hidden output 取出,再过一个dense layer(以及layer norm)
2。 再通过embedding table相乘,得到对应的字的index(参考XLNET的公式)(+ 每个的bias)
3。 计算这几个词的softmax with cross entropy(*weights 再norm)
output:
- loss: 归一化的总的cross entropy loss(去掉padding 的mask的loss)
- per_example_loss: 每个mask位置上的cross entropy loss
- log_probs: 输出每个位置的的log logits
"""
def get_masked_lm_output(bert_config, input_tensor, output_weights, positions,
label_ids, label_weights):
"""得到masked LM的loss和log概率"""
# 只需要Mask位置的Token的输出。注意我们这边的input_tensor是模型的model.get_sequence_output()
input_tensor = gather_indexes(input_tensor, positions)
with tf.variable_scope("cls/predictions"):
# 在输出之前再加一个非线性变换,这些参数只是用于训练,在Fine-Tuning的时候就不用了。
with tf.variable_scope("transform"):
input_tensor = tf.layers.dense(
input_tensor,
units=bert_config.hidden_size,
activation=modeling.get_activation(bert_config.hidden_act),
kernel_initializer=modeling.create_initializer(
bert_config.initializer_range))
input_tensor = modeling.layer_norm(input_tensor)
# output_weights是复用输入的word Embedding,所以是传入的,
# 这里再多加一个bias。
output_bias = tf.get_variable(
"output_bias",
shape=[bert_config.vocab_size],
initializer=tf.zeros_initializer())
# input_tensor shape(batch size* masked length, hidden size)
# output_wights = (vocabulary size, hidden size)
logits = tf.matmul(input_tensor, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
log_probs = tf.nn.log_softmax(logits, axis=-1)
# label_ids的长度是20,表示最大的MASK的Token数
# label_ids里存放的是MASK过的Token的id
label_ids = tf.reshape(label_ids, [-1])
label_weights = tf.reshape(label_weights, [-1])
one_hot_labels = tf.one_hot(
label_ids, depth=bert_config.vocab_size, dtype=tf.float32)
# 但是由于实际MASK的可能不到20,比如只MASK18,那么label_ids有2个0(padding)
# 而label_weights=[1, 1, ...., 0, 0],说明后面两个label_id是padding的,计算loss要去掉。
per_example_loss = -tf.reduce_sum(log_probs * one_hot_labels, axis=[-1])
numerator = tf.reduce_sum(label_weights * per_example_loss)
denominator = tf.reduce_sum(label_weights) + 1e-5
loss = numerator / denominator
return (loss, per_example_loss, log_probs)
"""
input_tensor : 是模型的model.get_pooled_output()即CLS对应的hidden输出
经过一个dense层直接进行2分类。
Output:
- loss: batch的平均loss
- per_example_loss: 每个样本的输出loss
- log_probs: 每个样本的输出log 概率
"""
def get_next_sentence_output(bert_config, input_tensor, labels):
"""预测下一个句子是否相关的loss和log概率"""
# 简单的2分类,0表示真的下一个句子,1表示随机的。这个分类器的参数在实际的Fine-Tuning
# 会丢弃掉。
with tf.variable_scope("cls/seq_relationship"):
output_weights = tf.get_variable(
"output_weights",
shape=[2, bert_config.hidden_size],
initializer=modeling.create_initializer(bert_config.initializer_range))
output_bias = tf.get_variable(
"output_bias", shape=[2], initializer=tf.zeros_initializer())
logits = tf.matmul(input_tensor, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
log_probs = tf.nn.log_softmax(logits, axis=-1)
labels = tf.reshape(labels, [-1])
one_hot_labels = tf.one_hot(labels, depth=2, dtype=tf.float32)
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)
loss = tf.reduce_mean(per_example_loss)
return (loss, per_example_loss, log_probs)google 开源了两种不同大小的模型,分别是
Fine-Tuning
首先需要下载中文预训练的模型,chinese_L-12_H-768_A-12, 例如这个代表的是layer=12,hidden size=768, attention head=12。
对于不同的任务,只需要简单将任务的输入数据传入bert模型,然后再进行finetune就行了。 我们以分类任务为例:我们只需要在官方提供的run_classifier.py脚本上进行少量修改就可以实现一个文本分类的任务。
- Step1:写好自己的processor,参照官方的其他processor的写法,这个processor的作用是解析训练数据。
class DomainClf_Processor(DataProcessor):
"""Processor for the domain classification."""
# 从文本中读取训练集数据
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, FLAGS.train_file)), "train")
# 从文本中读取验证集数据
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, FLAGS.dev_file)), "dev")
# 从文本中读取测试集数据
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, FLAGS.test_file)), "test")
# 定义分类的label
def get_labels(self):
"""See base class."""
return ["alerts", "baike", "calculator", "call", "car_limit", "chat", "cook_book", "fm", "general_command",
"home_command", "master_command", "music", "news", "shopping", "stock", "time", "translator", "video",
"weather"]
# 组装训练的example,我们这是单文本分类所以 使用的是 text-∅ pair
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
guid = "%s-%s" % (set_type, i)
text_a = tokenization.convert_to_unicode(line[0])
label_txt = line[1].replace("__label__", "")
label = tokenization.convert_to_unicode(label_txt)
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
- Step2:加到main函数的processors字典里
processors = {
"domainclf": DomainClf_Processor,
"cola": ColaProcessor,
...
} - Step3: 配置好脚本的flags - Step 4: 运行run_classifier.py`
通常建议写一个启动脚本,例如:
#!/bin/bash
#description: BERT fine-tuning
export BERT_BASE_DIR=AI_QA/models/RoBERTa-tiny-clue
export DATA_DIR=AI_QA/ALBERT/1-data/command
export TRAINED_CLASSIFIER=./output
export MODEL_NAME=roberta_tiny_clue_command_gpu
export CUDA_VISIBLE_DEVICES=2
python run_classifier_serving_gpu.py
--task_name=command
--do_train=false
--do_eval=false
--do_predict=true
--do_export=false
--do_frozen=true
--data_dir=$DATA_DIR
--vocab_file=$BERT_BASE_DIR/vocab.txt
--test_file=test
--bert_config_file=$BERT_BASE_DIR/bert_config.json
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt
--max_seq_length=128
--train_batch_size=32
--learning_rate=1e-4
--num_train_epochs=6.0
--output_dir=$TRAINED_CLASSIFIER/$MODEL_NAME可以看到对于loss的计算,对于整个segment的分类问题,我们直接使用的是model.get_pooled_output(), 而对于token level的loss计算,我们需要调用模型的model.get_sequence_output() 输出
"""Creates a classification model."""
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
# In the demo, we are doing a simple classification task on the entire
# segment.
#
# If you want to use the token-level output, use model.get_sequence_output()
# instead.
output_layer = model.get_pooled_output()
hidden_size = output_layer.shape[-1].value
output_weights = tf.get_variable(
"output_weights", [num_labels, hidden_size],
initializer=tf.truncated_normal_initializer(stddev=0.02))
output_bias = tf.get_variable(
"output_bias", [num_labels], initializer=tf.zeros_initializer())
with tf.variable_scope("loss"):
if is_training:
# I.e., 0.1 dropout
output_layer = tf.nn.dropout(output_layer, keep_prob=0.9)
logits = tf.matmul(output_layer, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
probabilities = tf.nn.softmax(logits, axis=-1)
log_probs = tf.nn.log_softmax(logits, axis=-1)
one_hot_labels = tf.one_hot(labels, depth=num_labels, dtype=tf.float32)
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)
loss = tf.reduce_mean(per_example_loss)
return (loss, per_example_loss, logits, probabilities)
modeling.py中我们可以看到:
self.sequence_output = self.all_encoder_layers[-1]
# The "pooler" converts the encoded sequence tensor of shape
# [batch_size, seq_length, hidden_size] to a tensor of shape
# [batch_size, hidden_size]. This is necessary for segment-level
# (or segment-pair-level) classification tasks where we need a fixed
# dimensional representation of the segment.
with tf.variable_scope("pooler"):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token. We assume that this has been pre-trained
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)
self.pooled_output = tf.layers.dense(
first_token_tensor,
config.hidden_size,
activation=tf.tanh,
kernel_initializer=create_initializer(config.initializer_range))
那么bert是如何进行模型精调的呢?我们在精调的时候能采取和原本下载好的预训练模型不同的configuration吗?以及我们可以创新自己的模型结构么?
相信很多人第一反应就是那肯定不行!我们的预训练就是在原本的模型的基础上,进行的模型参数精调,怎么可以改变模型的结构呢。但是其实我们通过看源码可以得到答案!答案就是可以的,当然这个效果往往没有直接在原本预训练模型配置下精调效果好。但是这也给了大家一些新的思路,比如说我要做一些新的实验,但是初始化还是可以大大提升效果的,或者我们想要训练一个4或者8层的BERT,我们都可以用现有的结构进行初始化。
- 第一步,构建模型 根据bert config 创建模型(所以你可以修改模型的配置,例如将层数减少等)
(total_loss, per_example_loss, logits, probabilities) = create_model(bert_config, is_training, input_ids, input_mask, segment_ids, label_ids, num_labels, use_one_hot_embeddings)
- 第二步,得到新模型于预训练模型的映射关系
首先我们可以知道我们新创的模型的所有的可训练的变量 tvars, 然后通过函数 get_assignment_map_from_checkpoint(tvars, init_checkpoint) 获得变量和预训练模型的变量的映射关系 assignment_map
tvars = tf.trainable_variables()
initialized_variable_names = {}
scaffold_fn = None
if init_checkpoint:
(assignment_map, initialized_variable_names
) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
我们可以看到,最重要的函数就是get_assignment_map_from_checkpoint(tvars, init_checkpoint),可以根据这个函数,知道具体这个映射表是怎么获得的。
常见的tensorflow 的变量名称比如说 [, < tf.Variable 'rnn/gru_cell/gates/bias:0' shape=(8,) dtype=float32_ref>, , ]
def get_assignment_map_from_checkpoint(tvars, init_checkpoint):
"""Compute the union of the current variables and checkpoint variables."""
assignment_map = {}
initialized_variable_names = {}
name_to_variable = collections.OrderedDict()
for var in tvars:
name = var.name
m = re.match("^(.*):d+$", name)
if m is not None:
name = m.group(1)
name_to_variable[name] = var
init_vars = tf.train.list_variables(init_checkpoint)
assignment_map = collections.OrderedDict()
for x in init_vars:
(name, var) = (x[0], x[1])
if name not in name_to_variable:
continue
assignment_map[name] = name
initialized_variable_names[name] = 1
initialized_variable_names[name + ":0"] = 1
return (assignment_map, initialized_variable_names)
-
- a) 首先先获得我们所有变量的名称name
比如一个变量, 可以得到它的name为 'rnn/gru_cell/gates/kernel',上面的正则表达式是为了获取变量名称,看不懂可以参考re 链接1 链接2。
得到变量名称后,可以获得一个变量名称到变量的字典name_to_variable`
-
- b) 之后我们将预训练模型中的变量去匹配我们新创的模型的变量,如果存在同名的变量,就加到映射表中。所以就可以知道,我们的新模型并不一定要和预训练模型相同,而是共有的结构,通过相同的变量名进行映射,从而进行初始化。
- 第三步,参数根据预训练模型进行初始化
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
bert的不足
- 模型太大,训练太慢
对于模型太大:BERT的模型压缩(参考:Don.hub:BERT 我变瘦了!但还是很强!model compression),各种DistilBERT,BERT-PKD以及华为的TinyBERT,都提出了基于知识蒸馏的方式进行模型压缩,并且达到了非常好的效果。同时Albert也进行了模型结构的改造,使用了parameter sharing以及embedding的factorization,使得模型参数减少,模型效果更好。 对于训练太慢:
-
- 可以使用LAMB 优化器,使得模型可以使用更大的batch size
- 使用Nvidia的Mixed Precision Training,可以在不降低模型的效果的基础上,大大降低参数的储存空间
- 分布式训练
- 此外由于transformer的限制,google最新提出的REFORMER : THE EFFICIENT TRANSFORMER (参考:Don.hub:Reformer 详解),将时间和空间复杂度降低至
, 相信会是最新的研究前景。
- tensorRT加速预测(GPU),CPU加速参考(bert-as-service)。
- vocabulary size非常大,对于中文推荐使用CLUE Benchmark 团队的预训练模型的vocabulary,能大大提升速度,词汇表大小变小,但是精度不变。
- 完全训练了?
RoBERTa(参考:Don.hub:RoBERTa 详解) 提出,BERT并没有完全训练,只要使用更多的数据,训练更多的轮次,就可以得到超过XLNET的效果。同时Albert也提出了,模型在大数据集上并没有overfitting,去掉了dropout之后,效果更好了。
- 训练的效率高吗?
在预训练中,我们只通过15%的masked tokens去更新参数,而85%的token对参数更新是没有起到作用的,ELECTRA论文中发现,采用100%的tokens能有效的提高模型效果。
- Position encoding的方法好吗?
bert 使用的是绝对的参数型的position encoding,华为基于bert提出的中文预训练模型NEZHA (参考:Don.hub:中文语言预训练模型--哪吒)中提出一种新的函数型的相对位置的position encoding的方法,并且说比目前的bert的方式更优。同时Self-Attention with Relative Position Representations 这篇文章也提出了一种relative position encoding的方式 (参考:Don.hub:你应该知道的transformer),并且在实作上比transformer更好。
- MASK的机制好吗?
BERT采用的是MASK wordpiece的方式,百度的ERNIE,BERT-WWM,以及SpanBERT都证明了mask连续一段的词效果比mask wordpiece更优。 此外,RoBERT采用的了一种Dynamic Masking的方式,每一次训练的时候动态生成MASK。 此外,MASK的机制在finetuning阶段没有,这个是模型的一个比较大的问题。
- [MASK] token在预训练中出现,但是在finetuning中没有出现。
这个问题XLNET(参考:Don.hub:XLNET 详解)结果的办法是使用Auto-regression,而在ELECTRA中,采用的是通过一个小的generator去生成replaced token,但是ELECTRA 论文中指出,这个discrepancy对效果的影响是小的。
- Loss有用吗?
XLNET,SpanBERT,RoBERTa,和ALbert都分析发现NSP loss对模型的下游任务起到了反作用,Albert给出了具体的解析。
- Loss够吗?
对于后面的研究,不同的模型都或多或少加了自己的定义的loss objectives,例如Albert的SOP等,微软的MT-DNN甚至直接把下游的任务当作预训练的多任务目标,ERNIE2.0提出了多种不同的训练目标,这些都证明,语言模型的强大,并且多个不同的loss是对模型训练有效果的。
- 不能够做自然语言生成NLG
XLNET以及GPT(参考:Don.hub:GPT 详解)都是auto regressive 的模型,可以生成语言,但是BERT的机制限制了它的这种能力,但是目前的研究发现经过改变mask的机制,可以让BERT模型具备NLG的能力,统一了NLU和NLG的榜单,参见UniLM (参考:Don.hub:UniLM 模型详解)
关于BERT的estimator,可以参考我的另外一篇文章:
Don.hub:自定义 Estimator 实现(以BERT为例)zhuanlan.zhihu.com