Advanced machine-learning techniques in drug discovery
尊敬的各位乘客: 您好!您所搭乘的本次2020列车即将到站,请您抓紧时间收拾自己的回忆,准备下车,不要留下遗憾,本次列车将永不返航。
那趁着2020年结束还有几天,赶紧冲一波业绩,话不多说,论文读起。
题目:Advanced machine-learning techniques in drug discovery
检索号:https://doi.org/10.1016/j.drudis.2020.12.003
【注:这是一篇综述论文】
The popularity of machine learning (ML) across drug discovery continues to grow, yielding impressive results. As their use increases, so do their limitations become apparent. Such limitations include their need for big data, sparsity in data, and their lack of interpretability. It has also become apparent that the techniques are not truly autonomous, requiring retraining even post deployment. In this review, we detail the use of advanced techniques to circumvent these challenges, with examples drawn from drug discovery and allied disciplines. In addition, we present emerging techniques and their potential role in drug discovery. The techniques presented herein are anticipated to expand the applicability of ML in drug discovery.
机器学习(ML)在药物发现中的普及度持续增长,产生了令人印象深刻的结果。随着使用量的增加,它们的局限性也越来越明显。这些限制包括对大数据的需求,数据的稀疏性以及缺乏可解释性。同样很明显,这些技术并不是真正的自主性,甚至在部署后也需要重新训练。在这篇综述中,我们详细介绍了先进技术的使用来规避这些挑战,并举例说明了药物发现和相关学科。此外,我们介绍了新兴技术在药物发现中的潜在作用。预期本文提出的技术将扩大ML在药物发现中的适用性。
Introduction(介绍)
The application of ML applied in the field of drug discovery continues to grow, facilitating research in numerous avenues. The success of ML is demonstrated by the increasing number of pharmaceutical companies in which ML is central to their business model (Table 1). In addition, ML has also been explored by large pharmaceutical companies for drug discovery 1, 2, 3, 4, 5, 6. Such success is a testament to the necessity and utility of ML for drug discovery, and an unambiguous indication that drug discovery will be intrinsically tied with ML. The goal is to reduce the resource- and labour-intensiveness of drug discovery, primarily the high-throughput screening (HTS) technique. Another aim of ML is to obviate the need for animal testing, which has received negative publicity of late.
ML在药物发现领域的应用不断增长,促进了众多领域的研究。越来越多的制药公司证明了ML的成功,在这些公司中ML是其业务模型的核心(表1)。此外,大型制药公司还探索了ML,以发现药物。这样的成功证明了ML用于药物发现的必要性和实用性,并且明确表明药物发现将与ML本质上联系在一起。其目标是降低药物发现的资源和劳动强度,主要是高通量筛选(HTS)技术。ML的另一个目的是避免动物试验的必要性,因为近来动物试验受到负面宣传。
Table 1. Examples of pharmaceutical companies in which ML is central to their business model



The success of ML lies in its ability to discern patterns in complex and large volume data sets [7]. In addition, ML techniques (MLT) can be developed using common programming languages, including Python and R, which are accessible to most researchers. Furthermore, there are third-party software that provide access to ML techniques for researchers unfamiliar with coding, such as Apple’s Create ML. Despite their simplicity, third-party software are limited in their capacity to perform ML techniques, as well as other aspects of the ML pipeline.
ML的成功在于它能够识别复杂和大容量数据集中的模式。此外,ML技术(MLT)可以使用公共编程语言开发,包括Python和R,大多数研究人员都可以访问这些语言。此外,还有第三方软件可以为不熟悉编码的研究人员提供对ML技术的访问,比如苹果的Create ML。尽管它们很简单,但是第三方软件执行ML技术以及ML pipeline的其他方面的能力受到限制。
Conventional MLTs have been thoroughly explored in drug discovery 8, 9, 10. Such techniques include both supervised and unsupervised MLTs, including k-Nearest Neighbour (kNN), decision tree, random forest, support vector machines (SVM), artificial neural networks (ANN), principal component analysis (PCA), and k-means. Their appeal stems from their simplicity, computationally undemanding, yet improved prediction accuracy compared with traditional predictive algorithms [11]. Equally, the underlying mechanisms for conventional techniques can be cognitively comprehended by noncomputer scientist researchers. For example, for kNN, the user has one parameter to control, the k value, which in turn determines the classification search space based on a plurality vote. Another example is SVM, which delineates categories using a hyperplane in conjunction with support vectors to maximise the distance between the different categories. SVM benefits from using the kernel trick, which allows for nonlinear mapping of the data, which has been widely used for nonlinear data sets [12]. The technique is also available for PCA (kernel PCA; kPCA) [12]. A recent study found that kPCA can be used to improve the classification of linear models, with comparable performance to nonlinear models, although at a significantly faster rate [13].
传统的MLTs在药物发现中已经得到了深入的探索。这些技术包括有监督和无监督的MLTs,包括k-最近邻(kNN)、决策树、随机森林、支持向量机(SVM)、人工神经网络(ANN)、主成分分析(PCA)和k-均值。与传统的预测算法相比,它们的吸引力来自于它们的简单性、无需计算,但预测精度有所提高。同样,非计算机科学家研究人员可以从认知上理解常规技术的基本机制。例如,对于kNN,用户可以控制一个参数k值,而k值又可以基于多个投票确定分类搜索空间。另一个例子是支持向量机,它使用一个超平面结合支持向量来描绘类别,以最大化不同类别之间的距离。支持向量机的优点在于使用了核技巧,它允许数据的非线性映射,这在非线性数据集中得到了广泛的应用。该技术也适用于PCA(kernel-PCA;kPCA)。最近的一项研究发现,kPCA可以用来改进线性模型的分类,并且具有与非线性模型相当的性能,尽管其速度要快得多。
Despite their simplicity, conventional MLTs have their drawbacks. kNN suffers from the curse of dimensionality, wherein, at high dimensional space, the predictive performance begins to weaken [14]. Similarly, the performance of SVM begins to degrade when the number of dimensions is greater than the sample size [15]. Increasing the number of trees in random forest improves the predictive accuracy, although a large number of tree results produces an algorithm inefficient for real-time monitoring 16, 17. However, there are two chief criticisms of MLT, which are their demand for big data and lack of transparency. Addressing these limitations is required given that the collection of data can be challenging, costly, and time-consuming. In addition, transparency might facilitate the user’s understanding of the discovery process and minimise their reliance on ML to understand the process. Another limitation with conventional MLTs is their lack of autonomy. For example, supervised learning requires labelling of the target variable (i.e., the variable to be predicted). In addition, once deployed, for example as a web-based software, it will require post-production maintenance, particularly as the data set evolves. To address these limitations, new techniques have been adopted by research communities and with promising results. It is anticipated that these advanced techniques will further expand the application of ML. Ultimately, the goal is to achieve artificial intelligence (AI) in the drug discovery pipeline [18]. AI is a broad branch in computer science that seeks to create human intelligence using machines, of which ML is central to achieving this goal. In recent years, a subset of ML, deep learning, as emerged as a technique capable of achieving high accuracies from big data, while handling both structured and unstructured data.
尽管简单,传统的MLTs也有其缺点。k-NN遭受维数灾难,在高维空间,预测性能开始减弱。同样,当维数大于样本大小时,SVM的性能开始下降。在随机森林中增加树的数量可以提高预测的准确性,但是大量的树结果会导致算法对实时监测的效率低下。然而,对MLT有两个主要的批评,一个是对大数据的需求,另一个是缺乏透明度。考虑到数据收集具有挑战性、成本高昂且耗时,需要解决这些限制。此外,透明性可能有助于用户理解发现过程,并尽量减少他们对ML的依赖来理解该过程。常规MLT的另一个限制是它们缺乏自治性。例如,监督学习需要标记目标变量(即要预测的变量)。此外,一旦部署,例如作为基于web的软件,它将需要后期维护,特别是随着数据集的发展。为了解决这些局限性,研究团体采用了新技术,并取得了令人满意的结果。预计这些先进的技术将进一步扩大最大似然法的应用范围。预计这些先进技术将进一步拓展ML的应用范围,最终目标是在药物发现管道中实现人工智能。人工智能是计算机科学的一个广泛分支,旨在使用机器来创造人类智能,而机器学习对于实现这一目标至关重要。
近年来,作为一种能够在处理结构化和非结构化数据时从大数据中获得较高准确性的技术,出现了机器学习的一部分,即深度学习。
As mentioned earlier, ML in drug discovery continues to grow. This growth is accompanied by suitable reviews discussing the fundamentals and the application of conventional MLTs [8], and deep learning [19]. There is also a recent review of natural language processing, a field that is gaining attention in drug discovery [20].Here, we focus on advanced techniques that have not received sufficient attention, albeit that have strong potential to advance the field. We prioritise examples used in drug discovery, although, if not available, we draw examples from allied fields. The reviewed techniques include reinforcement learning (RL), transfer learning, and multitask learning. In their well-received review centred on ML for drug discovery, Lo et al. remarked that techniques with increased visibility, as well methods for preventing overfitting, warrant further development [8]. We address their remark by describing Bayesian neural networks (BNNs) and explainable algorithms. We also detail the emergence of hybrid quantum-ML and recommender systems.
如前所述,药物开发中的ML持续增长。这种增长伴随着适当的评论,这些评论讨论了传统MLT的基本原理和应用,以及深度学习。最近也有一篇关于自然语言处理的综述,这是一个在药物发现中引起关注的领域。在这里,我们关注的是尚未得到足够重视的先进技术,尽管这些技术具有很强的发展潜力。我们优先考虑在药物发现中使用的例子,尽管,如果没有,我们从相关领域的例子。回顾了强化学习(RL)、迁移学习和多任务学习。在他们广受好评的关于药物发现的ML的综述中,Lo等人评论说,增加可见性的技术以及防止过度拟合的方法值得进一步发展。我们通过描述贝叶斯神经网络(BNNs)和可解释的算法来处理他们的评论。我们还详细介绍了混合量子ML和推荐系统的出现。
Advanced machine-learning techniques(先进的机器学习技术)
Some of the criticisms of MTLs include the need for large data sets and for human intervention. From these remarks, advanced techniques were investigated to address the shortcomings of conventional MLT, and thereby further widen their applicability. These advanced techniques include RL, which bridges the gap toward self-autonomous learning techniques; transfer learning, and multi-task learning for developing predictive models where big data are lacking. Here, we provide an overview of these advanced techniques and illustrate examples of their application in drug discovery where possible. A summary of the techniques are tabulated in Table 2.
对MTLs的一些评论包括需要大数据集和人为干预。从这些评论,先进的技术进行了研究,以解决传统的MLT的缺点,从而进一步扩大其适用性。这些先进的技术包括RL,它弥补了与自主学习技术之间的差距;迁移学习和多任务学习,用于在缺乏大数据的情况下开发预测模型。在这里,我们提供了这些先进技术的概述,并举例说明了它们在药物发现中的应用。表2列出了这些技术的摘要。
Table 2. Overview of advanced techniques described in this review

Reinforcement learning(强化学习)
RL is an exhilarating subcategory of ML that is sparking interest across both academia and industry. It has been around since the 1950s and its recent rise in popularity was sparked when RL models were victorious in a game of Go against professional human opponents, where no algorithm before was able to achieve this remarkable feat. The game Go is one of the world’s oldest continuously played games [21], and is used as a benchmark for AI because the number of possible configurations in the game is thought to be![]() [22]. This far exceeds both the number of proteins in the human body and the number of protons in the universe [23].
[22]. This far exceeds both the number of proteins in the human body and the number of protons in the universe [23].
RL是ML的一个令人振奋的子类别,在学术界和工业界都引起了兴趣。它从20世纪50年代就出现了,最近它的流行是因为RL模型在一场与职业人类对手的围棋比赛中获胜而引发的,在这场比赛中,没有任何一种算法能够实现这一惊人的壮举。Go游戏是世界上最古老的连续游戏之一,被用作AI的基准,因为游戏中可能的配置数量被认为是![]() 。这远远超过了人体中蛋白质的数量和宇宙中质子的数量。
。这远远超过了人体中蛋白质的数量和宇宙中质子的数量。
RL distinguishes itself from supervised and unsupervised learning in that it is a form of continuous learning while being autonomous. This is because RL algorithms produce judgements, whereas most supervised and unsupervised algorithms make predictions. This ability of RL to rapidly respond to dynamic environments is why it is being used for gaming, robotics, and trading in the finance sector [24]. Indeed, there are applications where RL outperformed classification tasks compared with supervised learning [25], but it is the ability of RL to continuously learn with minimal human interference that is desirable [26].
RL与有监督和无监督学习的区别在于,它是一种自主学习的持续学习形式。这是因为RL算法产生判断,而大多数有监督和无监督算法进行预测。RL对动态环境的快速响应能力正是它被用于游戏、机器人和金融行业交易的原因。事实上,与监督学习相比,在有些应用中,RL的性能优于分类任务,但是RL能够以最小的人为干扰持续学习。
The concept of RL draws inspiration from the reward mechanism found in animals [27]. In RL, the system is not presented with examples of desired strategies. Rather, RL empirically learns the optimal decision to take through receiving reinforcement signals from its environment. The main components of RL are an agent, environment, state, policy, and reward function [28]. An agent is trained by interacting with the environment, which can have multiple states (i.e., scenarios). The agent will select an action for a given state and will receive either a positive or a negative (i.e., penalise) reward. The agent will continue taking actions for each of the different states while looking to increase the cumulative reward it receives. The reward is a mathematical formula and is defined by the user with a specific goal in mind [29]. Using gaming as an example, the agent’s goal, or policy, is to win the game and it will receive +1 for when it does, and –1 for when it loses. In the case of financial trading, the policy can be to maximise profits and, hence, the agent will be rewarded for taking the series of actions that result in maximising the profit [30]. There are multiple versions of the reward function [31].
RL的概念从动物的奖励机制中得到启发。在RL中,系统没有给出期望策略的示例。相反,RL通过接收来自其环境的强化信号,从经验上学习要采取的最佳决策。RL的主要组成部分是代理、环境、国家、政策和奖励功能。代理通过与环境交互来训练,环境可以有多个状态(即场景)。代理将为给定的状态选择一个操作,并将获得正面或负面(即惩罚)奖励。代理将继续为每个不同的状态采取行动,同时寻求增加其获得的累积奖励。奖励是一个数学公式,由用户在心里有一个特定的目标。以游戏为例,代理的目标或策略是赢得游戏,当它赢得游戏时,它将获得+1,当它失败时,它将获得-1。在金融交易的情况下,政策可以是使利润最大化,因此,代理将采取一系列导致利润最大化的行动而获得奖励[30]。奖励功能有多种版本。
Contemporary RL has centred on de novo molecule designs 32, 33, 34, 35 or molecule optimisation [36]. A noteworthy study that combined both aspects was conducted by Popova et al. for the de novo design of drugs (Fig. 1a) [37]. With this approach, RL was combined with two deep-learning techniques. One technique, the generative model, acted as the agent and generated ostensibly chemically feasible molecules. The other technique, the predictive model, acted as the critic, whereby it rewarded or penalised the generative model for every generated molecule. Using this approach, the researchers used ∼1.5 million structures from the CheMBL21 database to train the generative model based on their SMILES strings. The results were that 1 million compounds were generated, from which 95% were confirmed to be feasible using the structure checker from ChemAxon. Moreover, they discovered that ∼32 000 molecules of de novo-generated structures existed in a separate database (ZINC). The study went further and demonstrated that novel compounds optimised for desirable physical properties, chemical complexity, or biological activity were attainable via deep RL. Although the study demonstrated that RL can be exploited to generate new compounds, further work is needed to refine the model. For example, the strategy adopted might not guarantee drug-specific compounds [38]. Moreover, the study used SMILES, which, despite being a simple and elegant representation of compounds, issues have been raised with its use in generative models [32].
当代RL集中于从头分子设计或分子优化。Popova等人进行了将两个方面结合起来的值得注意的研究。用于药物的从头设计(图1a)。通过这种方法,RL结合了两种深度学习技术。其中一种技术,即生成模型,作为媒介,产生表面上化学上可行的分子。另一种技术,预测模型,充当了批评家的角色,它对每一个生成的分子奖励或惩罚生成模型。使用这种方法,研究人员使用了来自CheMBL21数据库的约150万个结构来训练基于SMILES字符串的生成模型。结果表明,合成了100万个化合物,其中95%的化合物通过ChemAxon的结构检查器被证实是可行的。此外,他们发现在一个单独的数据库(ZINC)中有32000个从头生成的结构分子。这项研究进一步证明,新的化合物优化了理想的物理性质,化学复杂性,或生物活性是可以通过深RL实现的。这项研究进一步证明,通过深度RL可以获得优化的新化合物,以获得理想的物理性质、化学复杂性或生物活性。虽然研究表明RL可以被用来生成新的化合物,但是还需要进一步的工作来完善这个模型。例如,所采用的策略可能无法保证特定于药物的化合物。此外,这项研究使用了SMILES,尽管SMILES是一种简单而优雅的化合物表示,但在生成模型中的使用也引发了一些问题。

Figure 1. Examples of generated compounds using reinforcement learning (RL) reported by (a) Popova et al. [37] and (b) Zhavoronkov et al. [39].
In a separate study, Zhavoronkov et al. developed a model for de novo for specific compounds: DDR1 kinase inhibitors (Fig. 1b) [39]. Their aim was to demonstrate the effectiveness of RL for rapidly identifying potent compounds, thereby demonstrating that RL can address important drawbacks of drug development, namely the slow development phase and drug selectivity. In just 46 days, the authors were able to design, synthesise, and perform both in vitro and in vivo tests. However, one of the generated compounds was similar to both a compound that was used to train the model, as well as an existing marketed drug [40]. Hence, despite the success of demonstrating how RL can expedite the drug discovery pipeline, future models will need to be coded such that newly generated compounds are dissimilar from both the input data and existing marketed compounds. Although in the pharmaceutical discipline, the use of RL has been limited to drug design, the wider medical community has explored other potentials for the algorithm. In a step towards personalised dosage, several simulation-based studies explored using RL to provide dynamic decision-making for sepsis treatment [41], anaesthetic drug delivery control [42], and detection of diabetic retinopathy [43]. The use of RL has also been extended to ‘omics, bioimaging, and medical studies [28]. A schematic representation of RL is illustrated in Fig. 2a.
在另一项研究中,Zhavoronkov等人开发了一个特定化合物的从头模型:DDR1激酶抑制剂(图1b)。他们的目的是证明RL在快速识别强效化合物方面的有效性,从而证明RL可以解决药物开发的重要缺点,即缓慢开发阶段和药物选择性。在仅仅46天的时间里,作者就能够设计、合成并进行体外和体内试验。然而,其中一种生成的化合物既与用于训练模型的化合物相似,也与现有的上市药物相似。因此,尽管成功地证明了RL如何加速药物发现管道,未来的模型将需要编码,以使新生成的化合物与输入数据和现有的市场化合物都不同。虽然在药学领域,RL的应用仅限于药物设计,但更广泛的医学界已经探索了该算法的其他潜力。在向个性化剂量迈进的一步中,几项基于模拟的研究探索使用RL为败血症治疗提供动态决策、麻醉药物输送控制和糖尿病视网膜病变的检测。RL的应用也扩展到了“组学、生物成像和医学研究。RL的示意性表示如图2a所示。

Figure 2. Schematic representations of (a) reinforcement learning (RL), (b) transfer learning and (c) multitask learning.
Transfer learning(迁移学习)
If data are in short supply, then there are techniques that can be used to circumvent this problem. One such technique is transfer learning, which is the process of transferring knowledge acquired from solving one task to another related task. Transfer learning is an increasingly popular ML framework, particularly in medical image classification 44, 45, that encompasses a range of techniques. Transfer learning is the improvement of learning a new task through the transfer of knowledge from a related task that has already been learned. The technique leverages the features generated from a large data set, A that is used to predict its target variable Ya, and sequentially transfer the knowledge to predict a different target, Yb, from a data set, B, which has insufficient data. In the context of deep learning, the learned weights of the models are trained using the larger data set and then transferred to perform models for new similar tasks (Fig. 2b). The approach has been found to outperform conventional MLTs that were trained on the smaller data set. Furthermore, transfer learning can be rapidly deployed for new models because the optimisation process has already been performed. It makes the assumption that the predictive features in the larger data set can in principle be applied to a different yet related task. In addition, if the features are physically related, the features learned can be transferred partially as input features for the target domain [46]. Transfer learning frameworks can comprise supervised and unsupervised learning techniques, where the latter is lacking labelled output variables for the target domain [47]. Transfer learning has been implemented using spectral 48, 49, images 50, 51, audio, text [52], and numeric [53] data types.
如果数据短缺,那么有一些技术可以用来规避这个问题。其中一种技术是迁移学习,即将从解决一个任务获得的知识迁移到另一个相关任务的过程。迁移学习是一个越来越流行的ML框架,尤其是在医学图像分类中,它包含了一系列的技术。迁移学习是指通过从已经学习的相关任务中迁移知识来改进学习新任务。该技术利用从一个大数据集(A用于预测其目标变量Ya)生成的特征,并按顺序传递知识,从数据集B(数据不足)预测不同的目标Yb。在深度学习的背景下,使用更大的数据集训练模型的学习权重,然后将其传输到执行新的类似任务的模型(图2b)。研究发现,该方法的性能优于在较小数据集上训练的传统MLT。此外,由于优化过程已经完成,因此可以为新模型快速部署迁移学习。它假设较大数据集中的预测特征原则上可以应用于不同但相关的任务。此外,如果特征在物理上是相关的,则所学习的特征可以部分地作为目标域的输入特征进行传输。迁移学习框架可以包括有监督和无监督的学习技术,后者缺少目标域的标记输出变量。已经使用光谱、图像、音频、文本、和数字数据类型实现了迁移学习。
Turki et al. illustrated the potency of transfer learning in predicting the drug sensitivity of patients with multiple myeloma, where there was a lack of gene expression data, and acquiring new data was costly [54]. Using SVM and ridge regressions, the researchers trained the model on data from patients with lung and breast cancer, which were in abundance, and subsequently applied it to the multiple myeloma data set. The authors recorded a higher accuracy compared with their baseline. Most gene data sets generated by individual researchers are too small for MLTs. Taroni et al. leveraged the large, public expression compendia for transfer learning [55] and demonstrated that it was possible to describe biological processes more effectively than by using models trained only on their original features when using transfer learning. kNN regression-based transfer learning was combined with latent regression prediction to predict the sensitivity of different anticancer compounds [56]. Transfer learning was recently used to identify adverse drug reactions based on a model developed for automatic text classification of sentences to detect mentions of adverse drug reaction [57]. A large corpora source was used to train the model, and the knowledge gained was sequentially applied to a small-scale corpora. Other applications of transfer learning include incorporating the technique in de novo drug design 58, 59, 60.
Turki等阐明了迁移学习在预测多发性骨髓瘤患者药物敏感性方面的潜力,在那里缺乏基因表达数据,并且获取新的数据是昂贵的。利用支持向量机和岭回归,研究人员根据大量肺癌和乳腺癌患者的数据训练模型,随后将其应用于多发性骨髓瘤数据集。与基准相比,作者记录了更高的准确度。大多数由个体研究者产生的基因数据集对于MLT来说太小了。Taroni等人利用了大型的公共表达纲要进行迁移学习,并证明了在使用迁移学习时,使用仅针对其原始特征进行训练的模型能够更有效地描述生物过程。将基于kNN回归的迁移学习与潜在回归预测相结合,预测不同抗癌药物的敏感性。最近,迁移学习被用于识别药物不良反应,该模型基于句子的自动文本分类来检测药物不良反应的提及。使用大型语料库源对模型进行训练,并将所获得的知识依次应用于小规模语料库。迁移学习的其他应用包括将该技术应用于从头药物设计。
ML has also been applied in material science, although its use is not as developed as in drug discovery and development. Material science is of interest to pharmaceutical formulation, and indeed is an allied field, sharing similar research concepts and approaches. Recently, transfer learning was applied to various materials, including small molecules, polymers, and inorganic crystalline materials [46]. The study was able to successfully apply transfer learning to a data set with a small number of observations. In addition, underlying links between small molecules and polymers, and between inorganic and organic chemistry, were revealed. For example, a mean absolute error and correlation values of 0.063 and 0.832, respectively, for predicting the refractive index were obtained using the transferred features. By contrast, a notably poor error and correlation of 0.833 and 0.541, respectively, were obtained without transfer learning.
ML也已应用于材料科学,尽管它的使用不如药物发现和开发。材料科学与药物制剂有关,并且确实是一个联合领域,共享相似的研究概念和方法。最近,迁移学习被应用于各种材料,包括小分子,聚合物和无机晶体材料。这项研究能够成功地将迁移学习应用于少量观察到的数据集。此外,还揭示了小分子与聚合物之间以及无机与有机化学之间的潜在联系。例如,使用迁移的特征获得用于预测折射率的平均绝对误差和相关值分别为0.063和0.832。相反,在不进行迁移学习的情况下,获得的差错和相关性分别为0.833和0.541。
Multitask learning(多任务学习)
Whereas transfer learning is the sequential learning and subsequent transfer of knowledge to another task, multitask learning is the simultaneous learning of different tasks in one model. It was observed that learning related tasks simultaneously led to an improved predictive performance than when learning the tasks individually (i.e., single task learning). The benefits of multitask learning are particularly useful in low-volume data sets and/or when noise is significant [61]. In addition, multitask learning was found to outperform traditional MLT, particularly when data were relatively sparse. Using the example of a neural network, a traditional architecture learns a single task at a time that outputs a single layer for the predictive task. By contrast, multitask learning outputs multiple hidden layers corresponding to the number of tasks predicted. The related tasks could be uncorrelated at the output layer, but they should be correlated at the internal representation level. Multitask learning allows for the inductive transfer of knowledge between tasks. This optimises multiple loss functions that can enable models to better generalise across multiple tasks. The improved predictability of multitask learning can be attributed to different factors [62]. With multitask learning, the data are amplified because of the extra information shared between the related tasks (Fig. 2c). The multiple tasks are able to learn from one another and are able to filter between relevant and irrelevant features, particularly where data are few and/or significant noise is present. Furthermore, bias and overfitting are mitigated, because the multiple tasks learn cooperatively. In the case of overfitting, multitask learning affords the multiple tasks to help each other to create a smoother dependence on common features. Multitask learning can be used for both supervised and unsupervised learning 63, 64, and can be realised with different MLTs, such as neural networks, kNN [63], Bayesian multiple linear regression [65], and SVM [66].
迁移学习是顺序学习以及随后知识向另一任务的迁移,而多任务学习是在一个模型中同时学习不同任务。据观察,与单独学习任务(即,单个任务学习)相比,与学习相关的任务同时导致改进的预测性能。多任务学习的好处在小批量数据集和/或噪声很大的情况下特别有用。此外,发现多任务学习优于传统的MLT,尤其是在数据相对稀疏的情况下。使用神经网络的示例,传统体系结构一次学习单个任务,并为预测任务输出单个层。相比之下,多任务学习输出对应于预测任务数的多个隐藏层。相关任务在输出层可能不相关,但是应该在内部表示级别将它们相关。多任务学习允许在任务之间进行知识的归纳式传输。这优化了多个损失函数,可以使模型更好地概括多个任务。多任务学习的改进的可预测性可以归因于不同的因素。在多任务学习中,由于相关任务之间共享了额外的信息,因此数据得到了放大(图2c)。多个任务能够相互学习,并且能够在相关特征和无关特征之间进行过滤,尤其是在数据很少和/或存在大量噪声的情况下。此外,由于可以同时学习多个任务,因此可以减少偏置和过度拟合。在过度拟合的情况下,多任务学习提供了多个任务,以相互帮助,从而使对共同特征的依赖更加平滑。多任务学习既可以用于有监督的学习,也可以用于无监督的学习,并且可以通过不同的MLT实现,例如神经网络,kNN,贝叶斯多元线性回归和SVM。
In drug discovery, multitask learning has found application in addressing the effect of multitarget drugs. Such candidates were studied because their severe adverse effects, which is a negative consequence of acting on multiple targets. Of equal importance, it was recently demonstrated that multitarget drugs have been found to be more effective than single-target drugs for several complex diseases, such as cancer and metabolic diseases. This rationale was leveraged by Li et al., who showed that multitask learning could discover useful multiple targets that are affected by the same drug [67]. The researchers used unsupervised ML for their approach and both expression data and compound structure information. Yang et al. developed a multitask framework, called Macau, for large-scale drug screening, while simultaneously deriving interpretable insights about the interactions between the characteristics of the drugs and the cell lines [68]. Their algorithm used Bayesian multitask multi-relation to explore the interaction between the drug targets and signalling pathway activation using drug and gene data. Gene expressions were used as molecular inputs to predict signalling pathways; whereas, for the drug, their nominal targets were used as inputs. The rationale for their work was that the interaction between drug targets and signalling pathways can provide novel in-depth views of cellular mechanisms and drug mode of action.
在药物发现中,多任务学习已发现可用于解决多靶点药物的作用。对此类候选物进行研究是因为它们具有严重的不利影响,这是对多个目标采取行动的不利结果。同样重要的是,最近证明,对于多种复杂疾病,例如癌症和代谢性疾病,多靶点药物比单靶点药物更有效。 Li等人利用了这一原理,他表明多任务学习可以发现受同一药物影响的有用的多个靶标。研究人员将无监督的ML用于他们的方法以及表达数据和化合物结构信息。杨等开发了一个名为“Macau”的多任务框架,用于大规模药物筛选,同时获得了有关药物特性与细胞系之间相互作用的可解释的见解。他们的算法使用贝叶斯多任务多关系来利用药物和基因数据探索药物靶标与信号通路激活之间的相互作用。基因表达被用作预测信号通路的分子输入。而对于药物,其名义目标被用作输入。他们工作的理由是,药物靶标和信号通路之间的相互作用可以提供细胞机制和药物作用方式的新颖深入的见解。
In addition to sequential learning, multitask learning can be combined with gradient-boosting decision trees for small data sets [69]. Four data sets were investigated using this approach, with test sizes of 7413, 1792, 823, and 353 compounds. For the smallest set of 353 compounds, the R2 values when gradient boosting and multitask learning were used were 0.472 and 0.721, respectively. Combining the two techniques resulted in a R2 value of 0.733, which is an improvement on both individual techniques.
除了顺序学习之外,多任务学习还可以与用于小数据集的梯度增强决策树相结合。使用这种方法研究了四个数据集,测试量分别为7413、1792、823和353种化合物。对于最小的353种化合物,使用梯度增强和多任务学习时的R2值分别为0.472和0.721。两种技术的结合导致R2值为0.733,这是对两种技术的改进。
Multitask learning was also revealed by Weng et al. to simultaneously learn both classification and regression task analyses for drug–target interactions [70]. Classification tasks are prone to higher bias, whereas regression models are susceptible to overfitting because of the large variance encountered. Thus, to address the trade-off between bias and variance, a convolutional neural network model was developed to simultaneously optimise the regression and classification loss, using shared features. In another application. Han et al. used multitask learning for sentiment analysis of drug reviews [71]. The main objective was to identify people’s sentiment, opinions, and attitudes from a collection of 4200 drug reviews. In addition, Zubatyuk et al. combined multitask and multimodal learning to overcome sparsity in training data. Another key benefit of their approach is that the results were comparable to the density functional theory (DFT) method, which is a considerably more expensive modelling method.
Weng等人也揭示了多任务学习。同时学习药物和药物相互作用的分类和回归任务分析。分类任务易于产生较高的偏置,而回归模型由于遇到较大的差异而容易过拟合。因此,为了解决偏差和方差之间的折衷,开发了卷积神经网络模型,以使用共享特征同时优化回归和分类损失。在另一个应用程序中。Han等人使用多任务学习进行药物评论的情绪分析。主要目的是从4200份药品评论中找出人们的情绪,观点和态度。此外,Zubatyuk等人。结合多任务和多模式学习来克服训练数据中的稀疏性。他们的方法的另一个主要优点是,结果与密度泛函理论(DFT)方法相当,后者是相当昂贵的建模方法。
Active learning(主动学习)
Active learning is a unique semiautomated ML approach that also seeks to address the issue of low-labelled data sets using user feedback. In contrast to passive learning, active learning is ideal where there is an abundance of unsupervised training data that require costly and resource-intensive experiments to label. Consequently, the user can conduct experiments and subsequently label the data for a subset of the data set and use active learning to obtain the predictions for the remaining unlabelled data. Using this approach, active learning makes queries of samples that it is unsure of. For example, in using ML to predict the penetration of drugs through the blood–brain barrier, one can perform the experiment on 10% of the molecules, and train the model using said 10% to make predictions for the other 90%. Where the model is uncertain, it will make a query and the researcher can then perform the experiments on those samples. Hence, compared with passive learning, it has the potential to require considerably fewer labelled data [72], and thereby accelerate the drug discovery process while minimising costs. Further information regarding active learning, including sampling method and query strategies, can be found in [73].
主动学习是一种独特的半自动机器学习方法,它也试图使用用户反馈来解决低标签数据集的问题。与被动学习相比,主动学习是理想的选择,因为在这种情况下,大量无监督的训练数据需要昂贵且耗费资源的实验来标记。因此,用户可以进行实验并随后为数据集的子集标记数据,并使用主动学习来获得对其余未标记数据的预测。使用这种方法,主动学习可以查询不确定的样本。例如,使用ML预测药物通过血脑屏障的渗透率时,一个人可以对10%的分子进行实验,并使用10%的分子训练模型以对另外90%的分子进行预测。如果模型不确定,它将进行查询,然后研究人员可以对这些样本进行实验。因此,与被动学习相比,它有可能需要更少的标记数据,从而加快药物开发过程,同时将成本降至最低。在中可以找到有关主动学习的更多信息,包括采样方法和查询策略。
Active learning models can be built using conventional MLTs, such as SVM, and also deep learning 73, 74. Recent work demonstrated that active learning can be used for predicting small-molecule bioactivity, ligand–target interactions, and toxicity 75, 76, 77, 78.
可以使用传统的MLT(例如SVM)和深度学习来建立主动学习模型。最近的研究表明,主动学习可以用于预测小分子生物活性,配体-靶标相互作用和毒性。
Generative models(生成模型)
As described earlier, generative models are MLTs capable of generating new samples. This was leveraged for RL de novo applications, but generative models can also be used as standalone techniques. Generative models distinguish themselves from discriminative models by directly learning from the input data and do not necessarily require explicit rules to be coded by users. Generative models can generate new data instances through implementing a probabilistic estimator of data distribution, where the new data lie within the distribution. In other words, generative models are able to generate new samples for a given distribution. This contrasts with discriminative models, which reveal the probability of the labelled data given the data instance, regardless of whether the data instance is valid (Fig. 3). Recent studies used deep-learning generative models, which, in addition to generating new compounds, can be used for data augmentation when working with small data sets, and dimensionality reduction 79, 80, 81. As mentioned earlier, newly generated molecules will need to be thoroughly assessed to ensure that they are distinct from compounds that already exist in the market and/or different to compounds fed into the model.
如前所述,生成模型是能够生成新样本的MLT。这被用于RL de novo应用程序,但是生成模型也可以用作独立技术。生成模型通过直接从输入数据中学习而将自己与区分模型区分开,并不一定要求用户编写明确的规则。生成模型可以通过实现数据分布的概率估计器来生成新的数据实例,其中新数据位于分布内。换句话说,生成模型能够为给定的分布生成新的样本。这与判别模型相反,判别模型在给定数据实例的情况下揭示了标记数据的概率,而与数据实例是否有效无关(图3)。最近的研究使用了深度学习生成模型,该模型除了生成新化合物外,还可用于处理小型数据集时的数据扩充,以及降低维度。如前所述,新生成的分子将需要进行彻底评估,以确保它们与市场上已经存在的化合物不同和/或与输入模型的化合物不同。
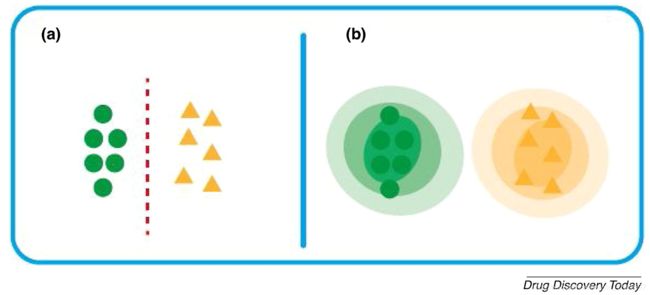
Figure 3. Differences between (a) discriminative and (b) generative modelling. Discriminative modelling seeks to classify through establishing, for example, decision boundaries. By contrast, generative models look at the probability distribution of the classes.
Bayesian neural networks(贝叶斯神经网络)
BNNs are ensemble models that combine multiple neural network models using Bayesian inference [82]. Unlike conventional neural networks, which require large amount of data for training, BNN can handle small data sets because of their ability to avoid overfitting. Overfitting is a problem associated with most conventional MLTs, which BNN avoids through prior probability distribution to compute the average across numerous models during training, which yields a regularisation effect to the network [83]. In other words, the weights and biases for neurons are not a single value but rather sampled from a distribution, which is regularly updated to train the BNN. The use of BNN has not been thoroughly explored for drug discovery. A recent study revealed that Bayesian graph networks outperformed conventional graph networks in predicting the inhibitory activity of molecules, using the ChEMBL data set [84]. BNNs were also used to identify genes associated with anticancer drug sensitivities using data gathered from the cancer cell line encyclopaedia study [85]. More recently, BNN were applied for identifying drug-likeness, where the Bayesian error distribution of individual classifiers can yield an accuracy of 93% for distinguishing drug-like from nondrug-like molecules [86]. Although BNNs are able to address some of the shortcomings of neural networks, they require a comparatively large effort to design the neural net, which can lead to establishing casual influences that are recognised by the individual programming it.
BNN是集成模型,使用贝叶斯推理结合了多个神经网络模型。与需要大量数据进行训练的常规神经网络不同,BNN可以处理小的数据集,因为它们具有避免过度拟合的能力。过拟合是与大多数传统MLT相关的问题,BNN避免通过事先的概率分布来计算训练期间众多模型之间的平均值,这对网络产生了正则化效果。换句话说,神经元的权重和偏置不是单个值,而是从分布中采样,该分布会定期更新以训练BNN。尚未完全探索BNN在药物研发中的用途。最近的一项研究表明,使用ChEMBL数据集,贝叶斯图网络在预测分子的抑制活性方面优于传统图网络。利用从癌细胞系百科全书研究中收集的数据,BNN还被用于鉴定与抗癌药敏感性相关的基因。最近,BNN被用于识别类药性,其中单个分类器的贝叶斯误差分布可以产生93%的准确度,以区分药物样分子与非药物样分子。尽管BNN能够解决神经网络的某些缺点,但是它们需要付出较大的努力来设计神经网络,这可能会导致建立偶然的影响力,而这种影响力可以通过对其进行单独编程来识别。
Explainable algorithms(可解释性算法)
The use of ML is indeed to facilitate and expedite decision-making, particularly for routine tasks. Thus, it might not be necessary to understand the decision-making process achieved by the model. However, understanding the decision process made by ML will instil confidence in researchers. Interpreting the model can help researchers troubleshoot when the model appears erroneous. In addition, the insight from the decision process could lead to plausible research questions. In addition, it can facilitate research understanding by providing insight into the decision making. Equally, transparency might also instil trust in regulatory bodies if the technology is to be commercialised.
ML的使用确实可以促进和加快决策,尤其是对于日常任务。因此,可能没有必要了解该模型实现的决策过程。但是,了解ML做出的决策过程将灌输研究人员的信心。解释模型可以帮助研究人员解决模型出现错误的问题。此外,决策过程中的洞察力可能会引发合理的研究问题。另外,它可以通过提供决策制定的见解来促进研究理解。同样,如果要将技术商业化,透明度也可能会引起对监管机构的信任。
A recent example of explainable ML was applied to quality structure–activity relationship modelling, wherein semisupervised regression trees were found to outperform supervised regression trees [87]. Using a different strategy for predicting activity, Rodriguez-Perez and Bajorath developed a method that elucidates the prediction process of conventional techniques, as well as ensemble and deep-learning models [88]. The focus of their work was to eliminate the ‘black-box’ nature of ML models. The approach was based on Shapley values that was initially developed for game theory, but were demonstrated by the authors to be applicable to ML. In their approach, each feature was assigned an importance value for a given prediction and, in turn, it provided an overview of which features have the most contribution to a model. Moreover, their approach uncovered model errors and consequently provided rationales for inaccurate predictions, which otherwise could not have been readily rationalised.
最近一个可解释的机器学习示例被应用到质量结构-活动关系建模中,其中发现半监督的回归树优于监督的回归树。 Rodriguez-Perez和Bajorath使用不同的策略来预测活动,开发了一种方法,该方法阐明了传统技术以及集成和深度学习模型的预测过程。他们的工作重点是消除ML模型的“黑匣子”性质。该方法基于最初为博弈论开发的Shapley值,但作者证明适用于ML。在他们的方法中,为每个特征分配了给定预测的重要性值,并依次概述了哪些特征对模型的贡献最大。而且,他们的方法发现了模型错误,因此为不准确的预测提供了理由,否则就无法轻易地使之合理化。
Emerging machine-learning techniques(新兴的机器学习技术)
Hybrid quantum-machine learning(混合量子机器学习)
The hybridisation of ML with quantum computing has emerged as a powerful technology in predictive analysis [89]. The main promise of quantum computing is the efficiency to solve complex problems that are prohibitively expensive for classical computers [90]. In classical models, the processing units compute bits that are either 0 or 1, whereas for quantum computing, the quantum bits, qubits, are in a superimposed state of both 0 and 1 [91]. The qubits are processed by quantum logic gates, which, in contrast to classical logic gates, are reversible. This yields computing prowess that prevents loss of information [92], faster analysis, and low power consumption [93]. The qubits and quantum gates are components of the quantum circuit that has been demonstrated to perform tasks that were quadratic, polynomial, or exponentially faster than their classical counterparts 94, 95, 96, 97. The definition of hybrid quantum ML is yet to be decided upon. To date, it encompasses the use of quantum computers to execute ML algorithms or adopting quantum information processing into ML 94, 98. The former approach can be regarded of as quantum-enhanced ML, whereas the latter can be regarded as quantum-inspired ML. Examples of hybrid quantum ML include supervised [99], unsupervised [100], and RL [101].
机器学习与量子计算的混合已经成为预测分析中的一项强大技术。量子计算的主要前景是能够解决复杂问题的效率,而这些问题对于传统计算机而言却过于昂贵。在经典模型中,处理单元计算的位为0或1,而对于量子计算,量子位qubit处于0和1的叠加状态。量子位由量子逻辑门处理,与经典逻辑门相反,量子逻辑门是可逆的。这产生了计算能力,可以防止信息丢失,更快的分析和较低的功耗。量子位和量子门是量子电路的组成部分,已证明它们比传统的能够执行二次,多项式或指数级的任务。混合量子ML的定义尚待确定在。迄今为止,它包括使用量子计算机执行ML算法或在ML中采用量子信息处理。前一种方法可以看作是量子增强的ML,而后者可以看作是量子启发式ML。混合量子ML的示例包括有监督的,无监督的和RL 。
The advantages of H-QML can indeed be leveraged in pharmaceutical sciences, however, at the time of writing, the technology has not yet been applied. In 2018, International Business Machines Corporation (IBM) published an article on The potential of quantum computing for drug discovery, wherein the authors included the potential of quantum ML in the scope of their review [102]. More recently, Google LLC released an open-access quantum ML framework for python that will enable researchers to use hybrid quantum ML [103]. Therefore, the promise of hybrid-quantum ML in pharmaceutical sciences is likely to be realised soon.
H-QML的优势确实可以在制药科学中加以利用,但是,在撰写本文时,该技术尚未得到应用。 2018年,国际商业机器公司(IBM)发表了一篇关于量子计算在药物发现中的潜力的文章,其中作者将量子ML的潜力纳入了其综述范围。最近,Google LLC发布了针对python的开放访问量子ML框架,该框架将使研究人员能够使用混合量子ML 。因此,制药科学中的混合量子ML有望很快实现。
Recommendation systems(推荐系统)
Recommendation systems gained fame in 2006 with the announcement of a Netflix competition seeking to create accurate user preference content for its users. A recommendation system is a ML framework that is based on data establishing links between a set of users (e.g., customers) to a set of items (e.g., products) [104]. Recommendation systems are heavily used in e-commerce, for example by Amazon and YouTube, to drive their sales [105]. The advantageous of such techniques are their ability to handle sparsity in data, to make predictions if prior information is unavailable, and to provide transparency by explaining how the recommender system makes the decision [106].
推荐系统在2006年声名鹊起,原因是Netflix宣布举办一项旨在为用户创建准确的用户偏好内容的竞赛。推荐系统是一种ML框架,它基于在一组用户(例如,客户)与一组项目(例如,产品)之间建立链接的数据。推荐系统在电子商务中被大量使用,例如亚马逊和YouTube,以促进其销售。此类技术的优势在于它们具有处理数据稀疏性,在无法获得先验信息的情况下进行预测的能力,以及通过解释推荐系统如何做出决策来提供透明度的能力。
Recommender systems have been investigated for medical applications, where the right treatment is proposed based on the patient’s medical history 107, 108. However, applications in drug discovery and development are yet to be established. Sosnina et al. developed a recommender system for compound–target interaction prediction for antiviral drug discovery [109]. The authors used a content-based filtering recommender system, which is suitable for sparse data and interpretability. In addition, their model made it possible to perform cold-start prediction, in which predictions can be made where there is no experimental data. Given that data in drug discovery and development are afflicted by all three issues, it is anticipated that the use of recommender system will increase.
已经针对医学应用研究了推荐系统,其中根据患者的病史提出了正确的治疗方案。但是,尚未建立在药物发现和开发中的应用。 Sosnina等人开发了用于预测抗病毒药物的化合物-靶标相互作用的推荐系统。作者使用了基于内容的过滤推荐系统,该系统适用于稀疏数据和可解释性。此外,他们的模型使执行冷启动预测成为可能,其中可以在没有实验数据的情况下进行预测。考虑到药物发现和开发中的数据受这三个问题的困扰,预计推荐系统的使用将会增加。
Concluding remarks
Here, we have presented examples of MLT used to circumvent the issues surrounding conventional techniques. We have detailed the use of ML for automating processes without human involvement; the use of transfer learning and multitask learning for when big data are lacking; BNNs for avoiding overfitting; and explainable algorithms that can shed light the decision-making process of a model. In addition, emerging techniques and their potential involvement in drug discovery were also discussed. Hybrid quantum-ML has the potential to further improve prediction performance, whereas recommendation systems can address data sparsity. It is anticipated that the use of the techniques discussed herein will be adopted in the near future, and that their application will further progress research in drug discovery. Ultimately, the quality of the predictions made by the models will depend on the quality of the data. Thus, the application of ML in drug discovery will benefit from a strategic and unified database.
在这里,我们提供了MLT的示例,用于规避围绕常规技术的问题。我们已经详细介绍了使用ML来实现流程自动化,而无需人工干预;在缺乏大数据时使用迁移学习和多任务学习; BNN用来避免过度拟合;可解释的算法可以阐明模型的决策过程。此外,还讨论了新兴技术及其在药物发现中的潜在作用。混合量子ML有可能进一步提高预测性能,而推荐系统可以解决数据稀疏性。预期在不久的将来将采用本文讨论的技术,并且它们的应用将进一步促进药物发现的研究。最终,模型做出的预测的质量将取决于数据的质量。因此,ML在药物发现中的应用将受益于战略性和统一的数据库。