R语言实战笔记 基本统计分析-相关
相关
相关系数可以用来描述定量变量之间的关系。
将使用R基础安装中的state.x77数据集,提供了美国50个州在1977年的人口、收入、文盲率、预期寿命、谋杀率和高中毕业率数据等。
数据如下:

相关的类型
Pearson、Spearman和Kendall相关:
可以用cor(x, use= , method= )函数计算三种相关系数。而cov()函数可用来计算协方差。
cor和cov的参数:
x:矩阵或数据框
use:指定缺失数据的处理方式。可选的方式为all.obs(假设不存在缺失数据——遇到缺失数据时将报错)、everything(遇到缺失数据时,相关系数的计算结果将被设为missing)、complete.obs(行删除)以及pairwise.complete.obs(成对删除,pairwise deletion)
method:指定相关系数的类型。可选类型为pearson、spearman或kendall。
> states<-state.x77[,1:6]
> cov(states)
> cor(states)
> cor(states,method = "spearman")

cov()计算了方差和协方差
第一个cor()计算了Pearson积差相关系数
第二个cor()计算了Spearman登记相关系数(可以看到收入和高中毕业率之间存在很强的正相关,而文盲率和预期寿命之间存在很强的负相关)
默认情况下得到的结果是一个方阵。你同样可以计算非方形的相关矩阵。
> x<-states[,c("Population","Income","Illiteracy","HS Grad")]
> y<-states[,c("Life Exp","Murder")]
> cor(x,y)

偏相关
偏相关是指在控制一个或多个定量变量时,另外两个定量变量之间的相互关系。
函数格式:pcor(u , s)
u是一个数值向量,前两个数值表示要计算相关系数的变量下标,其余的数值为条件变量(即要排除影响的变量)的下标。
S为变量的协方差阵。
> library(ggm)
> colnames(states)
> pcor(c(1,5,2,3,6),cov(states))

在控制了收入、文盲率和高中毕业率的影响时,人口和谋杀率之间的相关系数为0.346。偏相关系数常用于社会科学的研究中。
其他类型的相关
polycor 包中的 hetcor() 函数可以计算一种混合的相关矩阵,其中包括数值型变量的Pearson积差相关系数、数值型变量和有序变量之间的多系列相关系数、有序变量之间的多分格相关系数以及二分变量之间的四分相关系数。
相关性的显著性检验
在计算好相关系数后,要进行统计显著性检验。
常用原假设为变量间不相关(即总体的相关系数为0)。
- cor.test(x, y, alternative = , method = )
cor.test(x, y, alternative = , method = )对单个的Pearson、Spearman和Kendall相关系数进行检验。
x和y:要检验相关性的变量;
alternative:用来指定进行双侧检验或单侧检验(“two.side”、“less”、“greater”);
method:用以指定要计算的相关类型(“pearson”、“kendall”、“spearman”);
> cor.test(states[,3],states[,5])

检验了预期寿命和谋杀率的Pearson相关系数为0的原假设。在一千万次中只会有少于一次的机会见到0.703这样大的样本相关度(即p=1.258e–08)。拒绝原假设。即预期寿命和
谋杀率之间的总体相关度不为0。
- corr.test()
corr.test()函数可以计算相关矩阵和显著性水平。
use= 的取值可为 “pairwise” 或 “complete” (分别表示对缺失值执行成对删除或行删除)。
method= 的取值可为 “pearson” (默认值)、 “spearman” 或 “kendall”
> library(psych)
> corr.test(states,use="complete")
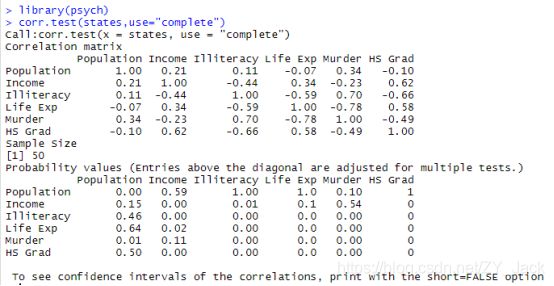
这里可以看到,人口数量和高中毕业率的相关系数(–0.10)并不显著地不为0(p=0.5)。
其他显著性检验
- pcor.test(r, q, n)
psych包中的pcor.test(r, q, n)函数可以用来检验在控制一个或多个额外变量时两个变量之间的条件独立性。
r是由pcor()函数计算得到的偏相关系数
q是要控制的变量数(用数值表示位置)
n为样本大小