pytorch---模型篇
说明:总结了以下pytorch进行深度学习的常用的写法和API
文章目录
-
-
- 1. 数据篇
-
- 1.1 Dataset
- 1.2 DataLoader
- 其他
- 2. 网络篇
-
- 2.1 层的使用
- 2.2 网络参数
- 2.3 输出网络结构
- 2.4 其他操作
- 3. 训练篇
-
- 3.1 损失函数
- 3.2 优化器
- 其他
- 4. 测试篇
- 5. 作图
-
1. 数据篇
1.1 Dataset
继承Dataset类写自己的数据集- 一般在
__init__()函数中定义类的变量,在创建类的对象时会被自动调用,可以写一些初始化语句 - 需要重写
__getitem__()和__len__()函数
- 一般在
1.2 DataLoader
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False):将dataset的数据打包成一个个batch
collate_fn()函数:返回自定义的batch的数据
def ssd_dataset_collate(batch):
# print('ssd_dataset_collate函数被执行...')
images = []
bboxes = []
for img, box in batch:
images.append(img)
bboxes.append(box)
images = np.array(images)
bboxes = np.array(bboxes)
return images, bboxes
gen = DataLoader(train_dataset, \
batch_size=Batch_size, \
num_workers=8, \
pin_memory=True,\
drop_last=True, \
collate_fn=ssd_dataset_collate)
# collate_fn=None)
参考链接:torch.utils.data.DataLoader中的collate_fn的使用
torch.utils.data.DataLoader中collate_fn函数的使用
其他
glob.glob(match string):匹配所有的符合条件的文件,并将其以list的形式返回。
glob.glob函数的参数是字符串,查找文件只用到三个匹配符:““, “?”, “[ ]”。其中,”“表示匹配任意字符串,”?” 匹配任意单个字符, “[ ]” 匹配指定范围内的字符,如:[0-9] 与 [a-z] 表示匹配 0-9 的单个数字与 a-z 的单个字符
all_filenames = glob.glob('../data/names/*.txt')
2. 网络篇
继承nn.Module类注意
在__init__()函数中必须要调用父类的__init__()函数在初始化程序之前。
2.1 层的使用
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None):线性层,又叫全连接层。对输入进行线性变换,即 y = w T x + b y=w^Tx+b y=wTx+b,也可以理解为将输入映射到输出的纬度空间。
input:( ∗ , H i n *,H_in ∗,Hin), H i n H_in Hin=in_features
input:( ∗ , H o u t *,H_out ∗,Hout), H o u t H_out Hout=out_features
>>> m = nn.Linear(20, 30)
>>> input = torch.randn(128, 20)
>>> output = m(input)
>>> print(output.size()) # torch.Size([128, 30])
ps:其内部是维护一个(out,in)的张量w和(out,)的b作为参数
self.weight = Parameter(torch.empty((out_features, in_features),**factory_kwargs))
if bias:
self.bias = Parameter(torch.empty(out_features, **factory_kwargs))
else:
self.register_parameter('bias', None)
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0,...):卷积层。
输入: ( N , C i n , H , W ) (N, C_{in}, H, W) (N,Cin,H,W)
输出: ( N , C o u t , H o u t , W o u t ) (N, C_{out}, H_{out}, W_{out}) (N,Cout,Hout,Wout)

rand_input = torch.randn(20, 16, 50, 100) #(N, in_chanles, h, w)
m = torch.nn.Conv2d(16, 33, 3, stride=2) #(in_chanles,out_chanles(即卷积核个数),kernels,stride)
CNN一般结构![]()
torch.nn.MaxPool2d(kernel_size, stride=None,...):池化层。一般使用 2 ∗ 2 2*2 2∗2的核
输入: ( N , C i n , H , W ) (N, C_{in}, H, W) (N,Cin,H,W)
>>> m = nn.MaxPool2d(2,2) # kernel: 2*2 , stride:2
>>> # pool of non-square window
>>> m = nn.MaxPool2d((3, 2), stride=(2, 1))
>>> input = torch.randn(20, 16, 50, 32)
>>> output = m(input)
简单的卷积神经网络例子
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 64, 5)
self.fc1 = nn.Linear(64 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
torch.nn.RNN(input_size, hidden_size, num_layers,...,bidirectional)
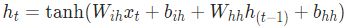
参数解释:input_size表示单个输入的纬度(embedding的纬度);hidden_size表示hidden state的纬度;num_layers表示要将RNN堆叠几次,例如当num_layers=2时,第二个RNN的输入为第一个RNN的输出,最后一个RNN的输出作为最终输出;bidirectional如果为True,表示双向RNN。
Inputs: input, h_0
input: ( L , N , H i n ) (L , N , H_{in} ) (L,N,Hin)
h_0:( D∗num_layers , H h i d d e n H_{hidden} Hhidden )
Outputs: output, h_n
output: ( L , N , D ∗ H h i d d e n ) (L , N , D*H_{hidden} ) (L,N,D∗Hhidden)
h_n:( D∗num_layers , H h i d d e n H_{hidden} Hhidden )
注释:L表示sequence length(sentence中的word数量);N表示batch size; H i n H_{in} Hin表示input size(word的embedding纬度);D表示RNN的方向数目若bidirectional=false,D=1,否则D=2; H h i d d e n H_{hidden} Hhidden表示hidden的纬度,在pytorch官网中也表示为 H o u t H_{out} Hout
>>> rnn = nn.RNN(10, 20, 2)
>>> input = torch.randn(5, 3, 10)
>>> h0 = torch.randn(2, 3, 20)
>>> output, hn = rnn(input, h0)
torch.nn.LSTM(input_size, hidden_size, num_layers,...,bidirectional)
Inputs: input, (h_0, c_0)
Outputs: output, (h_n, c_n)
shape与RNN的类似,c_0与h_0一致
lstm = nn.LSTM(3, 3) # Input dim is 3, output dim is 3 parameters:input size, hidden size, num_layers=1
inputs = [torch.randn(1, 3) for _ in range(5)] # make a sequence of length 5
inputs = torch.cat(inputs).view(len(inputs), 1, -1)
hidden = (torch.randn(1, 1, 3), torch.randn(1, 1, 3)) # clean out hidden state
out, hidden = lstm(inputs, hidden)
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None):相当于词典,词典的大小是word_num * word_dim(即num_embeddings*embedding_dim),初始为随机数,requires_grad=True。
input: 任何shape的索引(must be IntTensor or LongTensor)
output:input ∗ * ∗embedding_dim,输出为所在索引的word对应的embedding。
>>> # an Embedding module containing 10 tensors of size 3
>>> embedding = nn.Embedding(10, 3)
>>> # a batch of 2 samples of 4 indices each
>>> input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
>>> embedding(input)
tensor([[[-0.0251, -1.6902, 0.7172],
[-0.6431, 0.0748, 0.6969],
[ 1.4970, 1.3448, -0.9685],
[-0.3677, -2.7265, -0.1685]],
[[ 1.4970, 1.3448, -0.9685],
[ 0.4362, -0.4004, 0.9400],
[-0.6431, 0.0748, 0.6969],
[ 0.9124, -2.3616, 1.1151]]])
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None):一维BN。input为2D(NC)或3D(NC*L),对C纬度进行BN处理。又称为时域卷积。
Input: (N, C)(N,C) or (N, C, L)(N,C,L)
Output: (N, C)(N,C) or (N, C, L)(N,C,L) (same shape as input)
BN = nn.BatchNorm1d(3)
input1 = torch.arange(6).reshape(2,3).float()
print(input1,'\n')
# tensor([[0., 1., 2.],
# [3., 4., 5.]])
output = BN(input1)
print(output,'\n')
# tensor([[-1.0000, -1.0000, -1.0000],
# [ 1.0000, 1.0000, 1.0000]], grad_fn=)
input2 = torch.arange(24).reshape(2,3,4).float()
output = BN(input2)
print(output)
# tensor([[[-1.2288, -1.0650, -0.9012, -0.7373],
# [-1.2288, -1.0650, -0.9012, -0.7373],
# [-1.2288, -1.0650, -0.9012, -0.7373]],
# [[ 0.7373, 0.9012, 1.0650, 1.2288],
# [ 0.7373, 0.9012, 1.0650, 1.2288],
# [ 0.7373, 0.9012, 1.0650, 1.2288]]],
# grad_fn=)
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None):二维BN,在batch纬度上做归一化,对NWH做均值。又称为空间BN
Input: (N, C, H, W) or (N,C,H,W)
Output: (N, C, H, W) or (N,C,H,W) (same shape as input)
>>> # With Learnable Parameters
>>> m = nn.BatchNorm2d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm2d(100, affine=False)
>>> input = torch.randn(20, 100, 35, 45)
>>> output = m(input)
torch.nn.BatchNorm3d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None):三维BN。又称为时空BN。
Input: (N, C, D, H, W)(N,C,D,H,W)
Output: (N, C, D, H, W)(N,C,D,H,W) (same shape as input)
>>> # With Learnable Parameters
>>> m = nn.BatchNorm3d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm3d(100, affine=False)
>>> input = torch.randn(20, 100, 35, 45, 10)
>>> output = m(input)
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True, device=None, dtype=None):在通道纬度进行归一化,对CWH求均值。
Input: (N, *)(N,∗)
Output: (N, *)(N,∗) (same shape as input)
>>> # NLP Example
>>> batch, sentence_length, embedding_dim = 20, 5, 10
>>> embedding = torch.randn(batch, sentence_length, embedding_dim)
>>> layer_norm = nn.LayerNorm(embedding_dim)
>>> # Activate module
>>> layer_norm(embedding)
>>>
>>> # Image Example
>>> N, C, H, W = 20, 5, 10, 10
>>> input = torch.randn(N, C, H, W)
>>> # Normalize over the last three dimensions (i.e. the channel and spatial dimensions)
>>> # as shown in the image below
>>> layer_norm = nn.LayerNorm([C, H, W])
>>> output = layer_norm(input)
归一化总结
-
BatchNorm:batch方向做归一化,算NHW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布
-
LayerNorm:channel方向做归一化,算CHW的均值,主要对RNN作用明显;
-
InstanceNorm:一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
-
GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束。
SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。

-
torch.nn.Softmax(dim=None):接受一个实数向量并按照指定纬度返回一个概率分布,每个值在KaTeX parse error: Expected '}', got 'EOF' at end of input: {0,1]之间,其和为1,计算方式如下。输入与输出的shape一致

input:( ∗ * ∗)
output:( ∗ * ∗)
import torch.nn as nn
m = nn.Softmax(dim=1)
input = torch.randn(2, 3)
m(input)
# tensor([[0.1603, 0.4265, 0.4133],
# [0.2507, 0.5309, 0.2184]])
2.2 网络参数
torch.nn.parameter.Parameter(data=None, requires_grad=True):在Module中使用会作为模块属性加入参数列表。
from torch.nn.parameter import Parameter, UninitializedParameter
class model(nn.Module):
def __init__(self, parameters...):
super(model, self).__init__()
self.w_ii = Parameter(Tensor(hidden_size, input_size))
...
补充:其实nn.Linear()( W T X + b W^TX+b WTX+b)等模块在内部实现都是封装了Parameter W。参考官方文档
def __init__(self, in_features: int, out_features: int, bias: bool = True,
device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.empty((out_features, in_features), **factory_kwargs))
if bias:
self.bias = Parameter(torch.empty(out_features, **factory_kwargs))
else:
self.register_parameter('bias', None)
self.reset_parameters()
nn.Linear实质上就是通过一个(input,output)的矩阵将input纬度映射到output纬度,即 Y = W T X + b Y=W^TX+b Y=WTX+b。所以如果某一个输入需要将其乘以 W W W进行学习,也可以使用nn.Linear。
补充Parameter()与register_parameter():nn.Parameters 与 register_parameter 都会向 _parameters写入参数,但是后者可以支持字符串命名。从源码中可以看到,nn.Parameters为Module添加属性的方式也是通过register_parameter向 _parameters写入参数。
import torch
from torch import nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
print('before register:\n', self._parameters, end='\n\n')
self.register_parameter('my_param1', nn.Parameter(torch.randn(3, 3)))
print('after register and before nn.Parameter:\n', self._parameters, end='\n\n')
self.my_param2 = nn.Parameter(torch.randn(2, 2))
print('after register and nn.Parameter:\n', self._parameters, end='\n\n')
def forward(self, x):
return x
mymodel = MyModel()
for k, v in mymodel.named_parameters():
print(k, v)
程序返回结果
before register:
OrderedDict()
after register and before nn.Parameter:
OrderedDict([('my_param1', Parameter containing:
tensor([[-1.3542, -0.4591, -2.0968],
[-0.4345, -0.9904, -0.9329],
[ 1.4990, -1.7540, -0.4479]], requires_grad=True))])
after register and nn.Parameter:
OrderedDict([('my_param1', Parameter containing:
tensor([[-1.3542, -0.4591, -2.0968],
[-0.4345, -0.9904, -0.9329],
[ 1.4990, -1.7540, -0.4479]], requires_grad=True)), ('my_param2', Parameter containing:
tensor([[ 1.0205, -1.3145],
[-1.1108, 0.4288]], requires_grad=True))])
my_param1 Parameter containing:
tensor([[-1.3542, -0.4591, -2.0968],
[-0.4345, -0.9904, -0.9329],
[ 1.4990, -1.7540, -0.4479]], requires_grad=True)
my_param2 Parameter containing:
tensor([[ 1.0205, -1.3145],
[-1.1108, 0.4288]], requires_grad=True)
2.3 输出网络结构
net.named_parameters():返回name和参数的tuple
for name, param in self.named_parameters():
net.parameters():返回module的参数列表,即net.named_parameters()中的第二项
>>> for param in model.parameters():
>>> print(type(param), param.size())
(20L,)
(20L, 1L, 5L, 5L)
查看网络各层:
print(net)
遍历网络层:
(1)如果是单独定义各个模块
# 例如在网络的init函数中这样写:
self.fc1 = nn.Linear(10,64)
self.fc2 = nn.Linear(64,128)
...
# 则遍历网络层如下:
print(net.fc1)
print(net.fc1.weight)
print(net.fc1.bias)
(2)如果定义在sequential中
self.fc = nn.Sequential(
nn.Linear(28 * 28, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 10))
# 输出各层信息
print(net.fc)
print(net.fc[0])
print(net.fc[1])
print(net.fc[0].weight)
参考链接
2.4 其他操作
展平
将x除了第一维(batch size)其他都展平。常用在网络定义的forword函数中。
class Net(nn.Module)
...
def forward(self, x):
...
x = x.view(-1, self.num_flat_features(x))
...
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
或者可以使用以下代码代替
x.view(-1, x.size()[1:].numel())
3. 训练篇
3.1 损失函数
-
交叉熵表达式
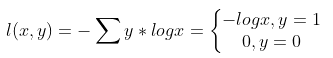
-
torch.nn.CrossEntropyLoss():交叉熵损失。常用于分类问题

或者
input:(N,C),C表示class_num
target:可以是(N,)表示N个类别,范围在[0,C);也可以是(N, C)的概率表示,
output:标量
>>> # Example of target with class indices
>>> loss = nn.CrossEntropyLoss()
>>> input = torch.randn(3, 5, requires_grad=True)
>>> target = torch.empty(3, dtype=torch.long).random_(5)
>>> output = loss(input, target)
>>> output.backward()
>>>
>>> # Example of target with class probabilities
>>> input = torch.randn(3, 5, requires_grad=True)
>>> target = torch.randn(3, 5).softmax(dim=1)
>>> output = loss(input, target)
>>> output.backward()
torch.nn.functional.log_softmax(input, dim=None, _stacklevel=3, dtype=None):log_softmax(x) = log(softmax(x))。主要是为了防止溢出,通常与nn.NLLLoss合用,此时与CrossEntropyLoss()等价。即CrossEntropyLoss() = log_softmax() + NLLLoss(),且NLLLoss()只能用于log_softmax()计算处理后的数据。torch.nn.NLLLoss():负对数损失,通常在分类问题中与log_softmax()合用

3.2 优化器
torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False, *, maximize=False):带动量的梯度优化策略
参数:
params:需要优化的参数,一般是模型的参数model.parameters()
lr:学习率
betas:梯度的均值和方差的动量衰减参数(即下方算法流程图的 β 1 β 2 \beta_1 \beta_2 β1β2)
eps:用于防止分母为0
weight_decay:参数衰减,F2正则,防止参数过大

torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=- 1, verbose=False):可以指定学习率随着epoch迭代次数而进行调整。
参数:
optimizer:优化器
milestone:递增的epoch索引列表
gamma:学习率的更新参数
last_epoch:最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
l r = l r i n i t ∗ γ i n d e x lr = lr_{init}*\gamma^{index} lr=lrinit∗γindex
这里的index表示参数milestone元素的index,每到一个节点lr就会改变
使用方法:
>>> # Assuming optimizer uses lr = 0.05 for all groups
>>> # lr = 0.05 if epoch < 30
>>> # lr = 0.005 if 30 <= epoch < 80
>>> # lr = 0.0005 if epoch >= 80
>>> scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
更多学习率衰减策略参考torch.optim.lr_scheduler:调整学习率
其他
固定模型的某些参数:若是你想固定住模型的某些参数,或者你知道某些参数的梯度不会被用到,那么就能够把它们的requires_grad 设置成False。
注意:一个Operation 若是全部的输入都不须要计算梯度(requires_grad==False),那么这个Operation 的requires_grad就是False,而只要有一个输入,那么这个Operation 就须要计算梯度。
>>> x = Variable(torch.randn(5, 5))
>>> y = Variable(torch.randn(5, 5))
>>> z = Variable(torch.randn(5, 5), requires_grad=True)
>>> a = x + y
>>> a.requires_grad
False
>>> b = a + z
>>> b.requires_grad
True
实例:细调(fine-tuing) 预先训练好的一个CNN,固定全部最后全链接层以前的卷积池化层参数
model = torchvision.models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
# 把最后一个全链接层替换成新构造的全链接层
# 默认的状况下,新构造的模块的requires_grad=True
model.fc = nn.Linear(512, 100)
# 优化器只调整新构造的全链接层的参数。
optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)
for i, data in enumerate(trainloader, 0)::返回一个枚举对象。iterable 必须是一个序列,或 iterator,或其他支持迭代的对象。 enumerate() 返回的迭代器的 next() 方法返回一个元组,里面包含一个计数值(从 start 开始,默认为 0)和通过迭代 iterable 获得的值。
其实就是将索引从0开始修改为从1开始
等价于
def enumerate(sequence, start=0):
n = start
for elem in sequence:
yield n, elem
n += 1
4. 测试篇
dataiter = iter(testloader):dataloader本质上是一个可迭代对象,可以使用iter()进行访问,采用iter(dataloader)返回的是一个迭代器,然后可以使用next()访问。也可以使用enumerate(dataloader)的形式访问。通常使用这种方式来获取dataloader中的一个batch的数据进行测试
dataiter = iter(testloader)
images, labels = dataiter.next()
5. 作图
torchvision.utils.make_grid(images):将几张图像横着拼起来。images.shape:(4,3,32,32)->(3,32,128)plt.imshow(np.transpose(npimg, (1, 2, 0))):在图片显示中,调用imshow函数需要将tensor类型转成numpy类型并将图片shape改变为(w,h,chanel)的形式
完整代码
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
imshow(torchvision.utils.make_grid(images))
参考链接