NeurIPS论文解读|Decision Transformer: 通过序列建模解决离线强化学习问题
今天为大家推荐一篇2021年被NeurIPS收录的一篇论文。
《Decision Transformer: reinforcement learning via sequence modeling》
推荐读者将本博客结合原论文食用。如有谬误偏颇烦请指出!
论文链接:
https://openreview.net/forum?id=a7APmM4B9d
1. 论文概览

先谈谈我的看法:在我看来,Decision Transformer与传统的RL算法最大的区别在于它训练的目标不再是为了最大化累计折扣奖励,而是学习从
,
到
的映射。为什么在训练的时候给medium级别的示例序列,而推断的时候我们调大
Decision Transformer(DT)[1]是纯监督学习,用来解决Offline Reinforcement Learning的问题。它不再将强化学习建模为马尔科夫决策过程(MDP),具体表现在网络在训练时拿到了非常long-term的信息,完全不符合马尔科夫性了。
具体而言,DT将RL当作一个自回归的序列建模问题,建模回报序列(return-to-go)、状态序列(state)与动作序列(action)之间的关系。与一般认为的行为克隆(behavior cloning)只建模状态和动作关系相比,额外考虑了回报以及过去的三元组(![]() ,
,![]() ,
,![]() )序列。最后的效果非常好,击败了一众当时顶尖的离线强化学习方法。
)序列。最后的效果非常好,击败了一众当时顶尖的离线强化学习方法。
2. 具体做法

如Figure 1所示,
网络输入是
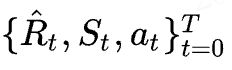
输出是
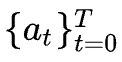
,是以自回归(autoregression)的方式生成动作。网络结构可以认为是Transformer[2] 的 Decoder 部分的修改(GPT),主要是masked multi-head self-attention。
2.1 网络输入
先从训练的时候讲起,如大家所知,基于时序差分算法的强化学习方法输入通常是四元组:![]() 来完成一次更新。
来完成一次更新。
而DT是以一条序列(trajectory)作为输入的:
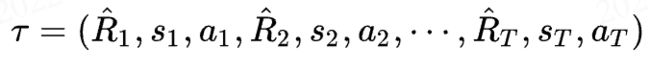
代表游戏从开始到结束的一整条序列,但是在实际训练过程中,我们往往只会截取K个时间步作为输入,这一点之后再说。
其中需要额外注意的是,和以往r代表奖励(reward)不同,这里作者采用的是 returns-to-go:
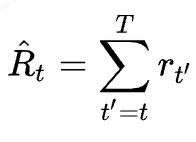
即从当前时刻开始,到这条序列结束的所有奖励 reward 的和,且没有折扣(折扣系数 )。
)。
为啥这样做呢?
这是因为,DT的目标是基于未来希望得到的回报来生成当前的动作,所以用 reward当然过于短视了,因为reward不具备未来的信息。
这里需要解释一下,作者希望DT达到一个什么地步呢?比如训练的时候,用return-to-go是90分的数据来训练,在测试的时候,如果我们输入的 return-to-go是100分,那么DT能够生成比训练时候更好的动作。事实上确实也做到了这一点,实验结果显示,在medium-expert, medium以及 medium-replay上是比行为克隆要强的。为啥能做到这一点是令人十分好奇的。
在测试的时候,我们给定希望的性能,比如设定归一化后
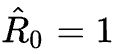
,然后输入环境的初始状态![]() ,网络就给出动作
,网络就给出动作![]() 。(事实上还可以输出r和s,但本篇文章没有利用这些,不予考虑),让智能体执行动作,环境给出奖励
。(事实上还可以输出r和s,但本篇文章没有利用这些,不予考虑),让智能体执行动作,环境给出奖励![]() 与下一个状态
与下一个状态![]() ,计算得到
,计算得到
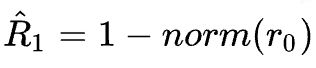
,再将![]() ,
,![]() ,
,![]() 加入到输入序列中,网络前传,得到动作
加入到输入序列中,网络前传,得到动作![]() ......以这种自回归的方式来进行推断直到游戏结束。
......以这种自回归的方式来进行推断直到游戏结束。
还有一个另外的疑问是,我们能否交换![]() 和
和 的顺序呢?
的顺序呢?
很明显a应该在这两者之后,我猜测![]() 和的顺序也是可以交换的。为此我在d4rl的hopper-medium-expert数据集上训练了DT,并每经过一段时间进行evaluation,比较两个顺序的性能,结果如下:
和的顺序也是可以交换的。为此我在d4rl的hopper-medium-expert数据集上训练了DT,并每经过一段时间进行evaluation,比较两个顺序的性能,结果如下:

经过我个人的实验,交换两者顺序之后得到的性能几乎相同,当然如果需要更确切地结论可能需要更多的实验,这里不予验证。
2.2 网络结构
和Transformer中有positional encoding来提供位置信息一样,在DT 中也需要一个timestep的信息来告知网络当前的步数。不同于位置编码的是,这里一个timestep对应了![]() 三个token。
三个token。
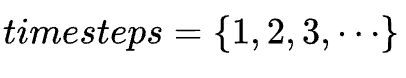
再来说说前文提到的每次只建模 个timesteps的序列:文中作者表示,在推断时,将序列
个timesteps的序列:文中作者表示,在推断时,将序列 中将最新的个timesteps送入网络。因为序列长度(一局游戏)是不确定的,可能高达 1000 个时间步,而模型是需要固定一个建模的时间步长来进行训练的,所以在这里设置一个代表建模的序列长度的超参数。在训练的过程中,将offline dataset trajectory中间的随机个连续的时间步数据送入进行训练。在我的实验中,选择的超参数=20。
中将最新的个timesteps送入网络。因为序列长度(一局游戏)是不确定的,可能高达 1000 个时间步,而模型是需要固定一个建模的时间步长来进行训练的,所以在这里设置一个代表建模的序列长度的超参数。在训练的过程中,将offline dataset trajectory中间的随机个连续的时间步数据送入进行训练。在我的实验中,选择的超参数=20。

数据处理相关代码[3]如下:
网络前传过程中,transformer模块输入的序列长度为3,即。timesteps的信息输入表现为其embedding被加到这三个模态数据的embedding上。
网络前传的代码[4]如下
B, T, _ = states.shape
time_embeddings = self.embed_timestep(timesteps) # shape: (B,context_len/T,h_dim)
# time embeddings are treated similar to positional embeddings
# shape: (B,context_len,h_dim)
state_embeddings = self.embed_state(states) + time_embeddings
action_embeddings = self.embed_action(actions) + time_embeddings
returns_embeddings = self.embed_rtg(returns_to_go) + time_embeddings
# stack rtg, states and actions and reshape sequence as
# (r1, s1, a1, r2, s2, a2 ...)
# after stack shape: (B, 3, context_len/T, h_dim)
h = torch.stack((returns_embeddings, state_embeddings, action_embeddings),
dim=1).permute(0, 2, 1, 3).reshape(B, 3 * T, self.h_dim)
h = self.embed_ln(h)
# transformer and prediction
# 这个 transformer 具体而言,是多组 attention + mlp + layernorm + resnet 结构块,
# 具体可以参照文末给出的代码仓库,或者任意一个 transformer 的实现。
h = self.transformer(h)
# get h reshaped such that its size = (B x 3 x T x h_dim) and
# h[:, 0, t] is conditioned on r_0, s_0, a_0 ... r_t
# h[:, 1, t] is conditioned on r_0, s_0, a_0 ... r_t, s_t
# h[:, 2, t] is conditioned on r_0, s_0, a_0 ... r_t, s_t, a_t
h = h.reshape(B, T, 3, self.h_dim)
# get predictions
return_preds = self.predict_rtg(h[..., 2, :]) # predict next rtg given r, s, a
state_preds = self.predict_state(h[..., 2, :]) # predict next state given r, s, a
action_preds = self.predict_action(h[..., 1, :]) # predict action given r, s
return state_preds, action_preds, return_preds
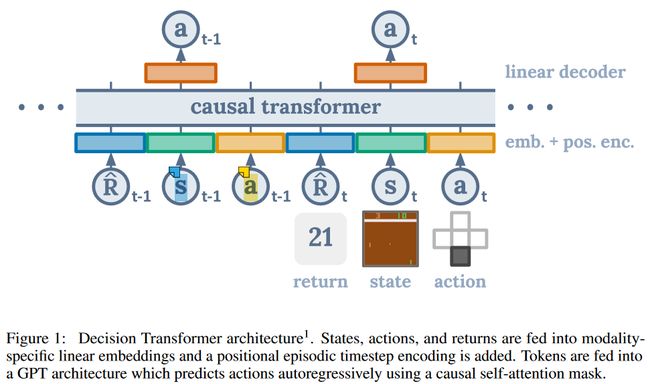
对照代码和结构图,可以发现,网络的输入和输出是一一对应的,不同模态![]() 的内容只在self-attention层进行交互。图中
的内容只在self-attention层进行交互。图中 在上方,与对应,由于mask,它的预测只利用了及
在上方,与对应,由于mask,它的预测只利用了及
2.3 损失函数
如果是连续动作,那么是 MSE,如果是离散动作,就是交叉熵:
之前的 token 的信息。
if self._cfg.model.continuous:
action_loss = F.mse_loss(action_preds, action_target)
else:
action_loss = F.cross_entropy(action_preds, action_target)
我们当然也可以预测序列下一步的![]() 和
和![]() ,但是作者在文中表示,这样的做法没有显著增加性能,所以就没管了。后来的一些文章中有考虑状态和奖励的信息,但这超出了本文的范围。
,但是作者在文中表示,这样的做法没有显著增加性能,所以就没管了。后来的一些文章中有考虑状态和奖励的信息,但这超出了本文的范围。
下图是论文中的DT的伪代码,以供参考:

需要额外注意的是,在实际推断过程中,虽然我们使用的序列模型对于任何序列长度的输入都可以处理,但是由于我们在训练时让网络学习的是建模序列长度为的序列,因此我们推断时的输入长度也应该是。具体实现上是先用占位符placeholder(0.)填充满个序列长度,这个是超参数,代表游戏最长timesteps,在我的实验中设定为1000。每次选择长度为的序列作为输入。随着自回归的进行,逐渐用真实的值来替换掉 placeholder。这部分代码[5]如下:
for t in range(self.max_eval_ep_len):
total_timestpes += 1
# 自回归,用真实的值替换掉作为占位符的0
# add state
states[0, t] = torch.from_numpy(running_state).to(device)
states[0, t] = (states[0, t] - state_mean) / state_std
# add rtg
running_rtg = running_rtg - (running_reward / rtg_scale)
rewards_to_go[0, t] = running_rtg
# 如果长度不到K,则输入前K个,最后预测的动作索引为t,保证只用了前t个timesteps的信息
if t < args.context_len:
_, act_preds = model.forward(
timesteps[:, :args.context_len], states[:, :args.context_len],
actions[:, :args.context_len], rewards_to_go[:, :context_len]
)
act = act_preds[0, t].detach()
# 如果序列长度超过了K,则输入最近K个timesteps的内容
else:
_, act_preds, _ = model.forward(
timesteps[:, t-args.context_len+1: t+1], states[:, t-args.context_len+1: t+1],
actions[:, t-args.context_len+1: t+1], rewards_to_go[:, t-args.context_len+1:t+1]
)
act = act_preds[0, -1].detach()
在![]() 时,如何保证输出的动作只用到了前
时,如何保证输出的动作只用到了前 个timesteps的信息?
个timesteps的信息?
1.attention mask:通过attention mask来保证时刻的attention score对于时刻之后的 value 赋分都是0;
2.全链接层怎么办?对于shape为 ![]() 的输入,mlp会对于个序列的向量分别做映射,每一个时间步输出的结果
的输入,mlp会对于个序列的向量分别做映射,每一个时间步输出的结果![]() 不会包含其它时间步的信息。
不会包含其它时间步的信息。
那么总结一下,Decision Transformer的策略可以表示为

,其中

3. 实验
一篇论文的好坏一定要去关注它的实验,否则只看前面的方法啥的,容易被作者的故事套进去,而实验数据是不会造假的。
下文的BC方法的网络结构和DT一样,唯一不同是去除了Return-to-go这一个模态的信息(相当于输入序列变成2了)。可以理解为序列建模版本的BC。
3.1 Atari(离散动作空间)
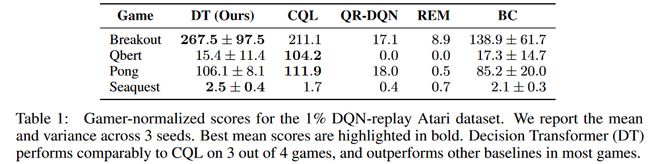
除了CQL在Qbert中取得的超模成绩之外,DT都取得了非常具有竞争力的成绩。
3.2 D4RL-Mujoco(连续动作空间)
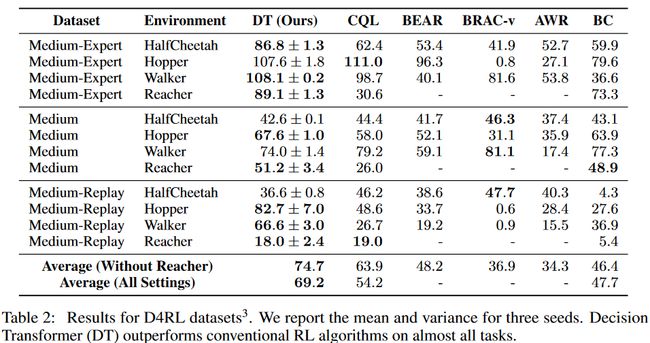
DT在绝大多数的项目中都取得了最好的成绩。
4. 消融实验
作者提出了一些问题并用设计实验进行验证:
1.DT是否比普通的行为克隆(BC)强?✅
2.DT建模return-to-go的效果好吗?✅
3.上下文长度的选取对性能的影响如何?✅
如果K=1相当于还是服从马尔可夫性,可惜实验结果表明这样效果极差。作者认为,序列建模对于上下文依赖程度很高,过去的信息对于Atari游戏是有用的(在DRQN 中,作者认为当有移动物体出现时,每一帧确实都是POMDP,因为只观测单帧的信息无法判定移动物体的速度和方向)。上下文信息使得transformer去搞清楚,生成哪些动作,能够导致更高的回报。

4. 是否DT在long-term credit assignment上表现良好?✅
作者在Key-to-Door这个变种环境上进行了验证,在这个环境中,必须在第一个房间中捡起钥匙,才能在第三个房间到达门拿到奖励,因此非常考验算法的长期置信分配能力——明白第一个房间的拿钥匙这个动作,对于很久之后的开门拿奖励的贡献巨大。
5. DT是否在稀疏奖励情况下准确预测奖励?✅
如果将输出action改为输出return-to-go,那么DT就可以由一个actor 转变为一个critic。
6. DT是否在稀疏奖励情况下也表现良好?✅
7. 为什么DT不需要像其他offline算法一样进行悲观值估计或者动作约束?原因正是因为DT不需要借助TD算法的Bootstrapping 来进行值估计或策略提升,不需要优化学习到的Q函数,避免了不准确的值函数估计,所以不需要进行悲观值估计或者动作约束。

8. 如何将DT用于online RL ?
未来的工作,实际上从现在的视角看已经有文章了,可见Online Decision Transformer[6],解决的是offline2online问题。
5. 总结
之所以DT效果这么好,作者认为是attention机制赋予了DT极佳的 long-term credit assignment的能力,能够在很长的序列中捕获动作对于奖励的作用。这一点在最后的实验部分(Key-to-Door 环境)得到了验证。但究竟为啥DT效果能这么卓越,我想至少文中是没有讲得很明白的。
In my opinion,decision transformer与传统的RL算法最大的区别在于它训练的目标不再是为了最大化累计奖励,而是学习从![]() ,
,![]() 到
到![]() 的映射。为什么在训练的时候给medium的序列,而推断的时候我们调大
的映射。为什么在训练的时候给medium的序列,而推断的时候我们调大![]() ,就能输出更好的动作?其中还是存在着“拼接”,由于是自回归的方式逐步的生成动作以及给定奖励,那么在同一个状态下,采取什么样的动作能得到什么样的奖励,是网络完全有可能学习到的。最后体现在整条序列上的就是,网络完全有可能学习到如何“拼接”出能产生给定
,就能输出更好的动作?其中还是存在着“拼接”,由于是自回归的方式逐步的生成动作以及给定奖励,那么在同一个状态下,采取什么样的动作能得到什么样的奖励,是网络完全有可能学习到的。最后体现在整条序列上的就是,网络完全有可能学习到如何“拼接”出能产生给定![]() 的动作序列。
的动作序列。
值得一提的是,同期也有一篇用transformer来做Offline RL的文章Trajectory Transformer[7]同样值得一看。
参考文献
[1]Decision Transformer https://arxiv.org/abs/2106.01345
[2]Attention is All You Need https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
[3]https://github.com/opendilab/DI-engine/blob/main/ding/utils/data/dataset.py#L332
[4]https://github.com/opendilab/DI-engine/blob/main/ding/model/template/decision_transformer.py#L88
[5]https://github.com/opendilab/DI-engine/blob/main/ding/policy/decision_transformer.py#L254
[6]Online DT https://arxiv.org/abs/2202.05607
[7]Trajectory Transformer https://trajectory-transformer.github.io/