Stable Diffusion模型运算量分析
准备
模型的参数量和计算量参考: ThanatosShinji/onnx-tool: ONNX model's shape inference and MACs(FLOPs) counting. (github.com)这四个模型就是Stable Diffusion 1.4 最主要的4个onnx模型:

github中的百度网盘可以下载带中间tensor shape的模型. 比如:

TextEncoder
这个模型很像BERT, 12 layers的Bert Base. 运算量6.7GMACs.
和 BertBase一样, 运算量98%都集中在MatMul上面.

这个token生成了1x77x768的hidden state需要送给UNetCondition.
UNet2DCondition
这个就是UNet+Transformer. 是整个StableDiffusion中主要负责图像生成的部分, 参数量高达859M, 模型文件超过3G. 可以理解这个模型参数记住了很多的图像纹理信息,能够根据输入的文字描述动态去调整图像的各个部分的纹理.
模型输入的分辨率是64x64, 按照UNet的方式用stride==2的conv2d来进行2倍下采样到32x32, 16x16, 8x8:
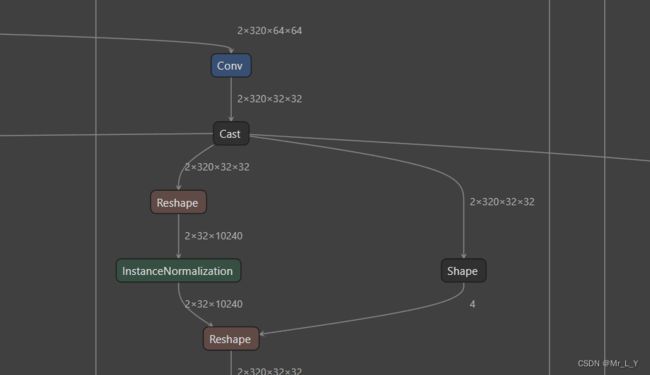
不同于UNet的持续做卷积, 它用下面的结构把hw转成矩阵结构, 拿去做MHA(multi-head attention):
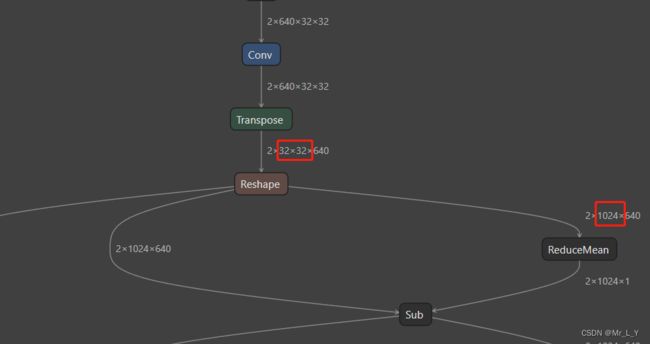
输入从2x640x32x32(UNet的常见结构) reshape到 2x1024x640(BERT的常见结构.
之后就拿这个BERT-like的tensor去做transformer encoder:
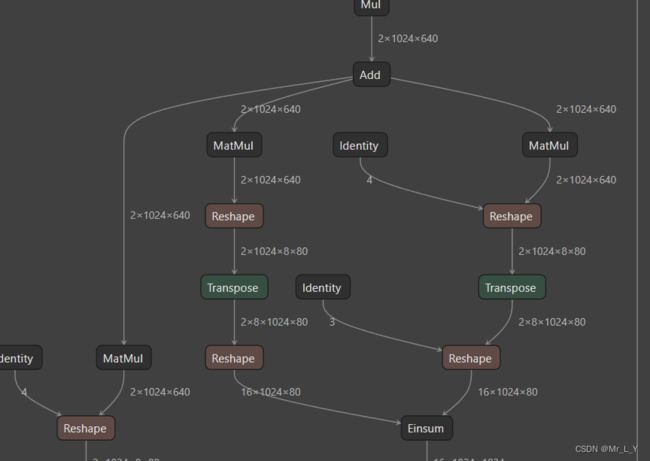
它这里把QKV的MatMul改成了Einsum.
所以UNet2DCondition就是把UNet降采样后的CNN结构部分替换成了Transformer结构.
总的来说: 卷积占总运算量的49%, 矩阵计算占31%(加上Einsum 总共45%)
VAE Encoder+Decoder
这两个模型是成对使用的所以放在一起. 这两个也是比较妙都是CV+transformer的结构.
Encoder把输入tensor从3x512x512通过CNN下采样到512x64x64, 马上又做了一次MHA:

做了后又经过几层卷积输出8x64x64的压缩特征.
Decoder拿到4x64x64的压缩特征后, 先卷积到512x64x64, 然后又是一个transformer MHA结构:
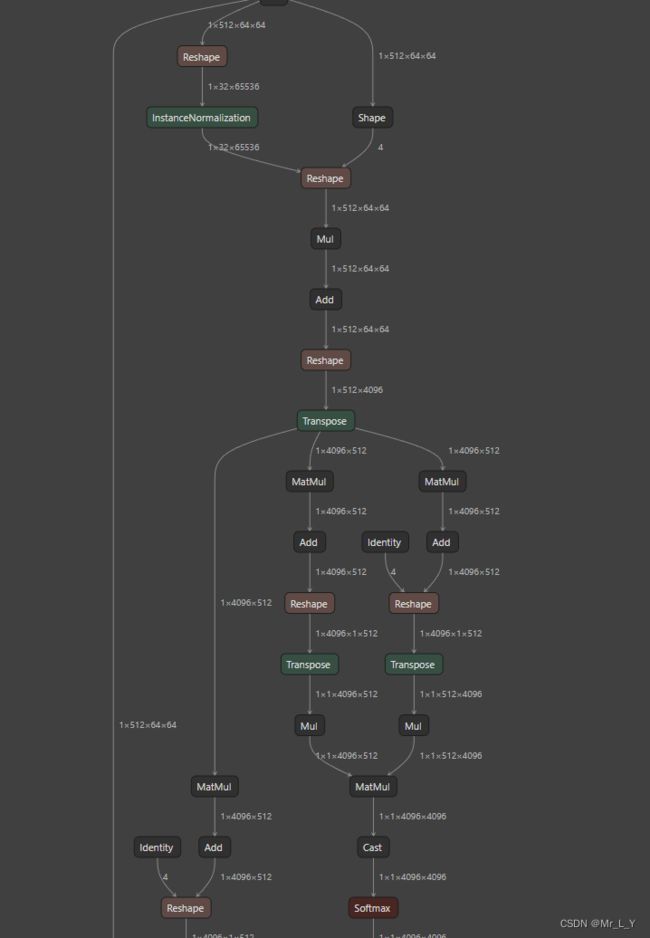
在这个MHA之后又通过Conv+Resize把tensor 还原到3x512x512.
大概就是这样的:
Encoder:
Conv 3x512x512
....
Conv 512x64x64
MHA 4096x512
Conv 8x64x64
Decoder:
Conv 4x64x64
Conv 512x64x64
MHA 4096x512
....
Conv 3x512x512
其中这两个运算量是最大的因为最大分辨率512x512的处理都在这里. Encoder: 566G MACs Decoder: 1271G MACs. Conv分别占了95%和97%的运算量. Transformer的MatMul基本可以忽略不记.
总结
transformer真是个提供模型解释性的好结构.
建议不要考虑增大模型的64x64的分辨率来增加生成的图像分辨率. 分辨率对模型整体运算量的影响系数很高. 可以考虑输出更低的分辨率, 比如32x32输出到256x256, 再用别的超分辨率网络来增加输出分辨率.
运算量的分析报告, 可以自己用命令行生成csv文件:
python -m onnx_tool -i .\vae_encoder.onnx -f vae_encoder.csv