负载均衡浅析
前言
负载均衡这个概念在我们工作中经常被提及到,因为纵观我们系统的整个链路层,每层都会用到负载均衡,从接入层,服务层,到最后的数据层,当然还有MQ,分布式缓存等等都会存在一些负载均衡的思路在里面;给负载均衡做一个简短的定义:就是将请求分摊到多个操作单元上进行执行;其实就是一种分而治之的思想,面对高并发的情况下,这是一种非常行之有效的方法。
核心功能
上面简短的定义中我们大致可以看到两个内容:将请求分发,操作单元;其实就是控制器+执行器模式、Master+Worker模式等等,是不是很熟悉;当然一个成熟的负载均衡器不光有这两个核心功能,还有一些其他的功能,下面看看都有哪些核心功能:
-
操作单元配置
这里的操作单元其实就是上游的服务器,是真正来处理业务的执行者,这个需要可配置的(最好能支持动态配置),方便用户添加和删除操作单元;这些操作单元就是负载均衡器分发消息的对象; -
负载均衡算法
既然需要分发,那具体通过何种方式把消息分给配置的执行器,这就需要有相关的分发算法了,比如我们常见的轮询、随机、一致性哈希等等; -
失败重试
既然配置了多个执行单元,所以某台服务器宕机是大概率事件,这样我们在分发请求给某台已经宕机的服务器时,需要有失败重试功能,将请求重新分发给正常的执行器; -
健康检查
上面的失败重试是只有真正转发的时候才知道服务器宕机了,是一种惰性策略,健康检查就是提前将宕机的机器排除掉,比如常见的通过心跳的方式去检查执行器是否还存活;
有了以上几个核心的功能,一个负载均衡器大致就形成了,可以把这几个原则用在很多地方,形成不同的中间件或者说内嵌在各种中间件中,比如接入层的LVS,F5,Nginx等,服务层各种RPC框架,消息队列RocketMQ、Kafka,分布式缓存Redis、memcached,数据库中间件shardingsphere、mycat等等,这种分而治之的思路在各种中间件中广泛使用,下面对一些常见的中间件是如何做负载均衡的进行分析,大体上可以分为有状态和无状态两种类型;
无状态
执行单元本身没有状态,其实是更加容易去做负载均衡,每个执行单元都是一样的,常见的无状态的中间件有Nginx,RPC框架,分布式调度等;
接入层
Nginx可以说是我们最常见的接入层中间件了,提供四层到七层的负载均衡功能,提供了高性能的转发,对以上的几个核心功能提供了支持;
- 操作单元配置
Nginx提供了简单的静态的操作单元配置,如下:
upstream tomcatTest {
server 127.0.0.1:8081; #tomcat-8081
server 127.0.0.1:8082; #tomcat-8082
}
location / {
proxy_pass http://tomcatTest;
}
以上配置是静态的,如果需要添加或者删除,需要对Nginx重启,很不方便,当然也提供了动态的单元配置,需要借助第三方的服务注册中心比如Consul,etcd等;原理大致如下:
操作单元启动就会注册到Consul中,同样宕机会从Consul中移除;Nginx侧会启动一个Consul-template监听程序,监听Consul上操作单元的变更,然后更新Nginx的upstream,最好重加载upstream;
- 负载均衡算法
常见的比如:ip_hash,round-robin,hash;配置也很简单:
upstream tomcatTest {
ip_hash //根据ip负载均衡,也就是常说的ip绑定
server 127.0.0.1:8081; #tomcat-8081
server 127.0.0.1:8082; #tomcat-8082
}
- 失败重试
upstream tomcatTest {
server 127.0.0.1:8081 max_fails=2 fail_timeout=20s;
}
location / {
proxy_pass http://tomcatTest;
proxy_next_upstream error timeout http_500;
}
当在fail_timeout内出现了max_fails次失败,表示此执行单元不可用;通过proxy_next_upstream配置,当出现配置的错误时,会重试下一台执行单元;
- 健康检查
Nginx通过集成nginx_upstream_check_module模块来进行健康检查;支持TCP心跳和Http心跳检测;
upstream tomcatTest {
server 127.0.0.1:8081;
check interval=3000 rise=2 fall=5 timeout=5000 type=tcp;
}
interval:检测间隔时间;
rise:检测成功多少次后,操作单元标识为可用;
fall:检测失败多少次后,操作单元标识为不可用;
timeout:检测请求超时时间;
type:检测类型包括tcp,http;
服务层
服务层主要的就是微服务框架比如Dubbo,Spring Cloud等,内部都集成了负载均衡策略,使用起来也是非常方便;
-
操作单元配置
RPC框架一般都依赖注册中心组件,其实和Nginx通过注册中心来动态改变操作单元是一样的,RPC框架默认就已经依赖注册中心了,服务启动就注册到中心,服务不可用就移除,并且会自动同步到消费端,用户完全无感知,消费端要做的就是根据注册中心提供的服务列表,然后使用分发算法进行负载均衡; -
负载均衡算法
Spring Cloud提供了Ribbon组件来实现负载均衡,而Dubbo直接内置均衡策略,常见的算法包括:轮询,随机,最少活跃调用数,一致性 Hash等等;比如dubbo配置轮询算法:
Ribbon配置随机规则:
@Bean
public IRule loadBalancer(){
return new RandomRule();
}
- 失败重试
对于RPC框架来说其实就是容错机制,比如Dubbo内置了多种容错机制包括:Failover、Failfast、Failsafe、Failback、Forking、Broadcast;默认的容错机制就是Failover失败自动切换,当出现失败重试其它服务器;配置容错机制也很简单:
- 健康检查
注册中心一般都有健康检查功能,会实时检测服务器是否可用,如果不可用会移除,同时将更新推送给消费端;对用户来说完全无感知;
分布式调度将调度器和执行器分离,执行器也是通过注册中心的方式提供给调度器,然后由调度器进行负载均衡操作,流程已基本相似,此处不再一一介绍;
可以发现无状态的负载均衡其实更多情况以来注册中心,通过注册中心来动态的增减执行单元,从而很方便的达到扩容缩容;
有状态
有状态的执行单元相对于无状态来说更加有难度,因为每个节点的状态是整个系统的一部分,不是能随意增减的节点的;常见的有状态中间件有:消息队列,分布式缓存,数据库中间件等;
消息队列
现在高吞吐量,高性能的消息队列越来越成为主流,比如RocketMQ,Kafka等,有强大的水平扩展能力;RocketMQ中引入Message Queue机制,Kafka引入分区(Partition),一个Topic对应多个分区,采用分而治之的思路来提高吞吐量,性能;可以看一个RocketMQ的简易图:
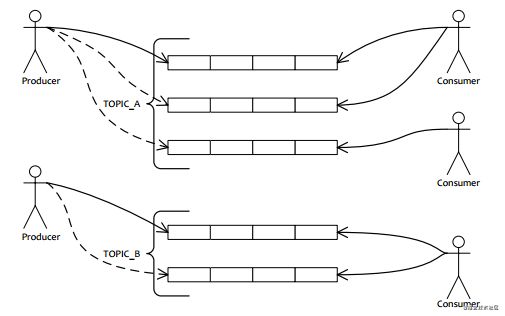
-
操作单元配置
消息队列里面的操作单元其实就是这里的分区或者说Message Queue,比如RocketMQ是可以动态去修改读写队列的数量;RocketMQ还提供了rocketmq-console控制台,可以直接修改; -
负载均衡算法
消息队列一般都有生产端和消费端,生产端默认是轮流给每个Message Queue发送消息,当然也可以自定义发送策略可以通过MessageQueueSelector来实现;消费端分配策略包括:分页模式(随机分配模式)、手动配置模式、指定机房模式、就近机房模式、统一哈希模式、环型模式; -
失败重试
对于有状态的执行单元来说,不是说宕机就可以直接移除的,需要保证数据的完整性,正常来说一般都会做主备处理,主机挂了备机接管;以RocketMQ为例,每个分区都有各自的备份,RocketMQ采取的策略是,备区仅仅是做数据的完整性保证,消费者能消息备区的数据,但是并不会重新来接收数据; -
健康检查
消息队列也有一个核心组件,可以理解为协调者,或者可以理解为注册中心,Kafka使用zookeeper,RocketMQ使用NameServer,里面其实就是保存了相关的对应信息比如Topic对应Message Queue,如果发现某台broker不可用,会将信息告知生产者,方式和注册中心类似;
分布式缓存
常见的分布式缓存有redis、memcached,为了能够容纳更多的数据一般都会做分片处理,分片的方式也是多种多样,就拿redis来说可以客户端做分片,基于代理的分片,还有官方提供的Cluster方案;
-
操作单元配置
缓存虽然也有有状态的,但是有其特殊性,其更多关注的是命中率,其实是可以容忍数据丢失的,比如基于代理的分片中间件codis,对客户端全透明不影响服务的情况下可以完成增减redis实例; -
负载均衡算法
基于保证命中率的前提下,基于代理分片的方式一般都会采用一致性哈希算法;而redis官方提供的Cluster方案,因为其内置有16384个虚拟槽,所以直接使用取模即完成分片; -
失败重试
有状态的分片一般都有会备区,在主区宕机后,备区接管实现故障迁移,比如redis的哨兵模式,或者codis这种中间件内置的功能;也无需去切换其他分区,对用户来说这种接管完全是无感知的; -
健康检查
以redis为例,哨兵模式中,sentinel通过心跳的方式实时监测节点,通过客观下线来实施故障迁移;可以发现健康检查基本都是通过心跳来检测的方式;
数据库层
数据库层做均衡处理应该说是最复杂的,首先是有状态的,其次是数据的安全性至关重要,常见的数据库中间件包括:mycat,shardingjdbc等;
-
操作单元配置
以分表为例,这里的操作单元其实就是一个个分片数据表,数据量有时候往往出乎我们的预料,一般很少说固定给它分配多少个分片,最好是通过负载算法自动生成数据表,而且最好事先就评估好某种负载算法,不然后期如果想改变是很难的; -
负载均衡算法
以mycat为例提供了多种负载算法:范围约定,取模,按日期分片,hash,一致性hash,分片枚举等等;比如下面的按天分区配置:
create_time
sharding-by-date
yyyy-MM-dd
2021-01-01
2051-01-01
10
指定了开始时间,结束时间,以及分区的天数;因为数据是随时间连续的,所以这种方式扩展性是很好的;如果是取模的方式就要考虑清楚分片的数量了,后面如果想改变分片数量就很麻烦了,不像缓存可以使用一致性hash来保证命中率就行了;
-
失败重试
有状态的节点,备库是少不了的,比如mycat提供了故障的主从切换功能,主宕机切换到从,基本都是这个套路,数据是不能丢的; -
健康检查
同样的主动检测也必不可少,一般也是基于心跳语句去定时检测,然后做故障主从切换;
以上是三种常见的有状态中间件,可以发现虽然都是有状态,但是根据数据的不同状态(临时的、最终的状态),处理的方式也很不一样;
其实还有一种有状态的中间件:注册中心,支持同时启动多个节点,但是每个节点保存的数据都是全量,因为注册中心往往保存的数据量很少,其提供的均衡策略可以像无状态一样简单。
总结
综上可以发现分而治之这种思想已经广泛的被用在各种软件中,遇到大的问题、大的数据量、大的并发量等等,其实核心思想就是拆分,至于如何拆分就要根据不同的业务需求使用不同的拆分算法或者说均衡算法,而且你需要保证上面介绍的几个基本功能。
感谢关注
可以关注微信公众号「回滚吧代码」,第一时间阅读,文章持续更新;专注Java源码、架构、算法和面试。