PyTorch深度学习 学习记录7_1
文章目录
- 循环神经网络(RNN)
- Pytorch中的RNN
- 一个栗子
循环神经网络(RNN)
CNN处理图而RNN则用于处理序列,它会记录上一时刻的结果并影响这一时刻的计算,这样说起来其实与马尔科夫链有些相似
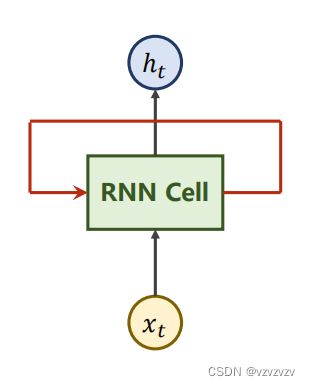
RNN的结构相当简单,而RNN层本质上就是一个线性网络不过为了更加直观通常会把他拉直: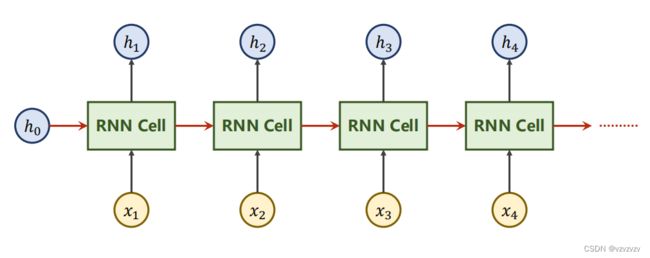
这样子就有“序列”的感觉了,这里可能会有人会有误区(比如我)误认为这里有多个层而 x t x_t xt则对应多个输入, x t x_t xt实际对应于同一序列不同时刻的输入。除此之外每一个RNN层输出的 h t h_t ht也会传递到下一层,其中 h 0 h_0 h0是我们的先验知识或是零向量
 RNN内部的模样就张这样,虽然看上去有两个线性层,但通常我们会把通过如下运算把 x t x_t xt和 h t h_t ht拼起来
RNN内部的模样就张这样,虽然看上去有两个线性层,但通常我们会把通过如下运算把 x t x_t xt和 h t h_t ht拼起来 当然RNN也可以构造多层,同时我们也需要多个 h 0 h_0 h0
当然RNN也可以构造多层,同时我们也需要多个 h 0 h_0 h0

Pytorch中的RNN
CLASS torch.nn.RNN(*args, **kwargs):
将具有非线性tanh或ReLU的多层Elman RNN应用于输入序列。
对输入序列中的每个元素做如下运算
h t = t a n h ( x t W i h T + b i h + h t − 1 W h h T + b h h ) h_t=tanh(x_tW_{ih}^T+b_{ih}+h_{t−1}W_{hh}^T+b_{hh}) ht=tanh(xtWihT+bih+ht−1WhhT+bhh)参数:
input_size: 输入x的特征数
hidden_size: 隐层的特征数
num_layers: 循环层的层数
nonlinearity: 使用的非线性函数,‘tanh’ 或 ‘relu’。默认为‘tanh’
bias: 是否使用bias。默认是True。
batch_first: 如果是True,那么输入和输出张量使用格式(batch, seq, feature)而不是(seq, batch, feature)。这不会影响RNN中的计算
dropout: 非0值则表示,除了最后一层外,给每一层都添加一个Dropout层,默认是0。
bidirectional: 如果为Ture,则表示建立的是双向RNN。默认是False。
输入:input, h 0 h_0 h0
input:
不使用batch,则输入的tensor是(seq_len, input_size)
使用batch,则输入的tensor是(seq_len, batch_size, input_size)
如果batch_first为True,则输入的tensor是(batch_size, seq_len, input_size)
h 0 h_0 h0:
不使用batch,则初始隐层 h 0 h_0 h0就是(D * num_layers, hidden_size)
使用batch,则初始隐层 h 0 h_0 h0就是(D * num_layers, batch_size, hidden_size)
其中当为双向RNN时D=2否则D=1
注意:batch_first为True时 h 0 h_0 h0不会变
输出:output, h n h_n hn
output:
不使用batch,则输出就是(seq_len, D * hidden_size)
使用batch,则输出就是(seq_len, batch_size, D * hidden_size)
如果batch_first为True,则输入的tensor是(seq_len, batch_size, input_size)
h n h_n hn:
不使用batch,则输出就是(D* num_layers, hidden_size)
使用batch,则输出就是(D * num_layers, batch_size, hidden_size)
一个栗子
字符级的自然语言处理会先为字符构造一个词典,为每个字符分配一个索引,然后用独热编码将各字符转换为一个向量 然后处理一个简单的问题:
然后处理一个简单的问题:
 既然都出现了独热编码,这个问题也就自然而然地转换成了多分类问题:
既然都出现了独热编码,这个问题也就自然而然地转换成了多分类问题:
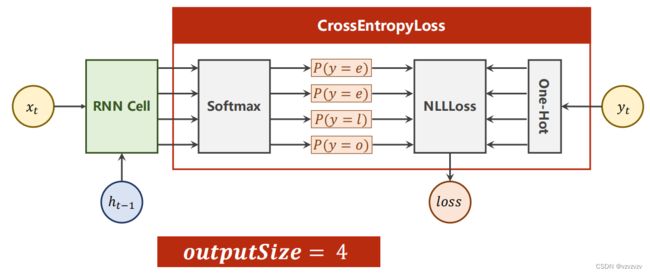 代码(使用RNNCell):
代码(使用RNNCell):
import torch
input_size=4
hidden_size=4
batch_size=1
idx2char=['e','h','l','o']
x_data=[1,0,2,2,3]
y_data=[3,1,2,3,2]
one_hot_lookup=[[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,10]]
x_one_hot=[one_hot_lookup[x] for x in x_data]
inputs=torch.Tensor(x_one_hot).view(-1,batch_size,input_size)
labels=torch.LongTensor(y_data).view(-1,1)
class Model(torch.nn.Module):
def __init__(self,input_size,hidden_size,batch_size):
super().__init__()
self.batch_size=batch_size
self.input_size=input_size
self.hidden_size=hidden_size
self.rnncell=torch.nn.RNNCell(input_size=self.input_size,hidden_size=self.hidden_size)#这里用的是Cell,序列长度会在循环中体现
#相当于做了RNN中的单步
def forward(self,input,hidden):
hidden=self.rnncell(input,hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size,self.hidden_size)
net=Model(input_size,hidden_size,batch_size)
critrion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(net.parameters(),lr=0.1)
for epoch in range(30):
loss=0.0
optimizer.zero_grad()
hidden=net.init_hidden()
print('Predicted string:',end='')
for input,label in zip(inputs,labels):
hidden=net(input,hidden)
loss+=critrion(hidden,label)#每次只计算了一个时刻,所以要将每个时刻的损失相加
_,idx=hidden.max(dim=1)
print(idx2char[idx.item()],end='')
loss.backward()
optimizer.step()
print(',Epoch[%d/30] loss=%.4f'%(epoch+1,loss.item()))
使用RNN:
import torch
input_size=4
hidden_size=4
batch_size=1
seq_len=5
num_layers=1
idx2char=['e','h','l','o']
x_data=[1,0,2,2,3]
y_data=[3,1,2,3,2]
one_hot_lookup=[[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,10]]
x_one_hot=[one_hot_lookup[x] for x in x_data]
inputs=torch.Tensor(x_one_hot).view(seq_len,batch_size,input_size)
labels=torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self,input_size,hidden_size,batch_size,num_layers):
super().__init__()
self.batch_size=batch_size
self.input_size=input_size
self.hidden_size=hidden_size
self.num_layers=num_layers
self.rnn=torch.nn.RNN(input_size=self.input_size,
hidden_size=self.hidden_size,
num_layers=self.num_layers)
def forward(self,input,h0):
out,hidden=self.rnn(input,h0)
return out.view(-1,self.hidden_size)#(seqlen*batchsize,hiddensize)
#方便做交叉熵
def init_hidden(self):
return torch.zeros(self.num_layers,self.batch_size,self.hidden_size)
net=Model(input_size,hidden_size,batch_size,num_layers)
critrion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(net.parameters(),lr=0.1)
for epoch in range(30):
optimizer.zero_grad()
h0=net.init_hidden()
outputs=net(inputs,h0)
loss=critrion(outputs,labels)
loss.backward()
optimizer.step()
_,idx=outputs.max(dim=1)
idx=idx.data.numpy()
print('Predicted:',''.join([idx2char[x] for x in idx]),end='')
print(',Epoch[%d/30] loss=%.4f'%(epoch+1,loss.item()))
虽然独热编码简单有效,但还是有着诸多缺点:1.矩阵稀疏,2.维度高,3.硬编码(即人为指定不可学习)。
为了解决这个问题于是就有了词嵌入,词嵌入实际与卷积核相当类似,通过这种方式也能够表征序列中各个状态间的关联,具体一点可以看这里 这样我们的模型能够变得稍微复杂一点:
这样我们的模型能够变得稍微复杂一点:
 代码:
代码:
import torch
input_size=4
hidden_size=8
batch_size=1
seq_len=5
num_layers=2
num_class=4
embedding_size=10
idx2char=['e','h','l','o']
x_data=[[1,0,2,2,3]]
y_data=[3,1,2,3,2]
inputs=torch.LongTensor(x_data)
labels=torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.emb=torch.nn.Embedding(input_size,embedding_size)
self.rnn=torch.nn.RNN(input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)
self.fc=torch.nn.Linear(hidden_size,num_class)
def forward(self,x):
h0=torch.zeros(num_layers,x.size(0),hidden_size)
x=self.emb(x)#(batch,seqlen,embeddingSize)
x,_=self.rnn(x,h0)
x=self.fc(x)
return x.view(-1,num_class)
net=Model()
critrion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(net.parameters(),lr=0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs=net(inputs)
loss=critrion(outputs,labels)
loss.backward()
optimizer.step()
_,idx=outputs.max(dim=1)
idx=idx.data.numpy()
print('Predicted:',''.join([idx2char[x] for x in idx]),end='')
print(',Epoch[%d/15] loss=%.4f'%(epoch+1,loss.item()))