并行计算 深度学习 机器学习
深度学习系列
第一篇 局部最优点+鞍点+学习率的调节
第二篇 并行计算 深度学习 机器学习
文章目录
- 深度学习系列
- 一、基础概念
-
- 1.并行计算针对哪一部分?
- 2.怎么并行计算的?
- 3.并行的主要问题是信息的传递问题
-
- 3.1消息传递(Message passing)的类型
- 3.2如果我们有m个worker,那么时间就降到原来的1/m吗?
- 异步的Message passing模型---Parameter server
-
- Parameter server的流程
- Parameter server的不稳定地方
- 二、扩展----联邦学习
- 三、Reference
- 总结
一、基础概念
1.并行计算针对哪一部分?
并行计算主要针对模型学习中的梯度求解过程,我们知道数据越多,参数越多,求解梯度越慢。这就是我们机器学习的瓶颈,是它主要限制了我们的速度。
2.怎么并行计算的?
最简单的概念就是2个GPU,我们将一半的权重交给GPU1计算,另一半交给GPU2计算,最后再合起来。
使用并行计算,数据量并不会减少,但是实际时间减少了。这里区分一个概念,CPU/GPU时间和实际时间不一样,1个CPU/GPU用20min,10个CPU/GPU所用的CPU/GPU时间为200min,但是实际时间是20min(这个实际时间也叫wall-clock time)
3.并行的主要问题是信息的传递问题
第一种方法是内存共享(Share Memory),其实就是在同一个主机上,内存是同一个地方的,这时候可以很容易知道其他GPU计算的结果,但是这样子的缺点是没办法做到大规模的并行,因为一台机器能加入的硬件是有限的。
所以我们一般使用第二种方法是消息传递(Message passing),其实就是在同一个主机上,内存是同一个地方的,这时候可以很容易知道其他GPU计算的结果,但是这样子的缺点是没办法做到大规模的并行,因为一台机器能加入的硬件是有限的。
3.1消息传递(Message passing)的类型
有Client-server类型和peer-to-peer类型,如下图,Client-server是有一个中心处理server,它会把worker node,也就是具体的工作节点的权重参数在中心点进行聚集。而peer-to-peer没有中心节点,只有邻居节点可以通信。具体来说,不同节点之间的通信方式也多样,像用TCP/IP协议经过网络通信就是其中一种。

下面我们具体讲解常用的Client-server模型
我们用Goole开发的一直叫MapReduce的并行计算框架的流程进行讲解。
- 首先:我们的数据集会被划分到不同节点上面,一个worker节点会有数据集的一部分数据。
- 第二步:中心server会把最新的参数下发到各个worker节点,这过程称为“Broadcast”
- 第三步:worker节点训练它的对应的参数(一个worker训练一部分参数),并把参数组合成一个vectors
- 最后,server把worker传过来的vectors组合成gradient
重复以上步骤,就是client-server的原理了!
3.2如果我们有m个worker,那么时间就降到原来的1/m吗?
答案是否定的。因为不同节点间还需要考虑传递或者同步等影响因素。
传递的影响是指:有如使用网络链路传递,可能有延迟,重发等可能
同步的影响是指:我们需要等所有节点都训练完成再传递到server(这就是MapReduce,当然也有其他框架不是这样子,下面会介绍),如果一个worker出现故障,重新训练模型,那么将影响已训练好的模型的传递。
 这里给出一个图,纵坐标Speedup可以说是一个性能指标,横坐标是节点数。可以看到我们的随着节点的增加,并不是性能越来越好,是有一个极限的。这里就是考虑到了一些影响因素,节点越多,可能出现问题的可能性越大。
这里给出一个图,纵坐标Speedup可以说是一个性能指标,横坐标是节点数。可以看到我们的随着节点的增加,并不是性能越来越好,是有一个极限的。这里就是考虑到了一些影响因素,节点越多,可能出现问题的可能性越大。
异步的Message passing模型—Parameter server
Parameter server的流程
它的过程和MapReduce是大致一样的,但是唯一区别是worker节点计算完立即传递给server,server立马更新参数。这样子可能每次使用的参数都不是最新最好的,但也会收敛,而epoch的次数肯定也更多。但是时间上可能会更少。
Parameter server的不稳定地方
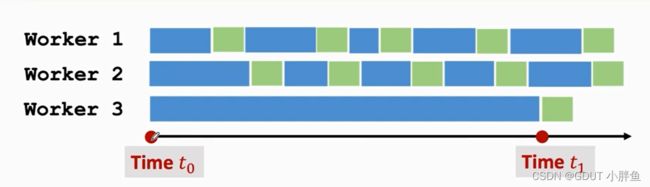
如果有一个worker很慢将会影响整个模型,如下图,加入worker1,worker2都更新了4次,worker3由于某些原因,才更新了一次,这时候它使用的参数已经是过时的了,所训练出来的梯度,可能是偏离我们要的方向的,所以会影响我们的模型。所以,worker必须比较稳定,可以快一点点,慢一点点,但是不能偏离太多。
二、扩展----联邦学习
联邦学习其实就是一种分布式学习,是为了保护用户的隐私而设计的,我们用户的隐私并不想传递到中心服务器去训练参数,那我们可能把用户的设备当作一个worker node,他们的隐私放在他们那里训练即可,无需上传到server中心,这样子就保护了他们的隐私。
但是联邦学习与分布式机器学习还是有不同点
- 用户控制他们的设备和数据,不再是server去控制。
- worker节点是不稳定的,例如手机作为节点,可能断网,没信号等。
- 他们的通信花销比分布式机器学习大,因为分布式机器学习可能就是在一个实验室中,他们使用的通信可能是高速的链路等,而联邦学习的数据都在远端,需要远程传输。
- 最后是个人数据的多样性,可能我拍的照片比较多,其他人少,或者我拍的照片偏向于自拍,而其他人偏向于风景,这种多样性就让建模的难度增加了。
三、Reference
分布式机器学习、联邦学习(Shusen Wang)
总结
以上就是我参照资料对分布式机器学习 并行计算的理解,希望配合上其他文章,能让初学者更容易理解。如果觉得有用,请大家点赞支持!!!!。