文本检测算法----TextFuseNet(IJCAI-PRICAI-20)
多种文本检测算法性能对比及算法介绍
(https://blog.csdn.net/qq_39707285/article/details/108754444)
TextFuseNet: Scene Text Detection with Richer Fused Features
- 前言
- 1. 算法简介
- 2. 算法详解
-
- 2.1 网络结构
- 2.2 Multi-level Feature Representation
- 2.3 Multi-path Fusion Architecture
- 3.4 loss函数
- 3.5 Weakly Supervised Learning
- 4. 测试结果
开源代码地址
前言
自然场景中任意形状文本检测是一项极具挑战性的任务,与现有的仅基于有限特征表示感知文本的文本检测方法不同,本文提出了一种新的框架,即 TextFuseNet ,以利用融合的更丰富的特征进行文本检测。
该算法用三个层次的特征来表示文本,字符、单词和全局级别,然后引入一种新的文本融合技术融合这些特征,来帮助实现鲁棒的任意文本检测。另外提出了一个弱监督学习机制,可以生成字符级别的标注,在缺乏字符级注释的数据集情况下也可以进行训练。
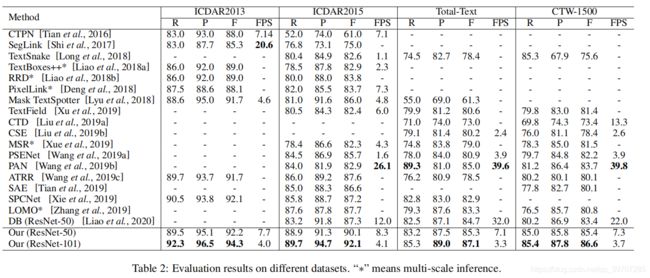
该算法在ICDAR2013上取得F1分数94.3%,在ICDAR2015上F1分数92.1%,在Total-Text上87.1%,在CTW-1500上86.6%,目前为止最佳成绩。
1. 算法简介
之前的文本检测算法大致分为两种,基于字符级别的检测和基于单词级别的检测。基于字符级别的检测算法首先提取单个字符,然后再使用字符合并算法合并这些字符成一个单词,然而这种方法因为要生成大量的字符候选框并且要合并,比较耗时。相比之下,基于单词级别的检测算法直接检测单词,会更高效和简单,但这种方法通常无法有效地检测具有任意形状的文本。为了解决这个问题,一些基于单词的方法进一步应用实例分割来进行文本检测。 在这些方法中,前景分割掩码被估计以帮助确定各种文本形状。
尽管有很好的结果,但现有的基于实例分割的方法仍然有两个主要的局限性。一是,这些方法只基于单个感兴趣区域(RoI)检测文本,而不考虑全局上下文,因此它们倾向于基于有限的视觉信息产生不准确的检测结果。二是,现有的方法没有对不同层次的单词语义进行建模,产生假阳性的可能性增大。从图一中可以看到这种方法的弊端。

本文提出的TextFuseNet能够有效的解决这些问题,并且可以高效准确的预测任意形状的文本。TextFuseNet与其他算法相比主要的区别在于,有效的利用各种层次的特征,例如字符级别的、单词级别的、全局级别的特征,而其他的文本检测算法往往只使用一种层次的特征。
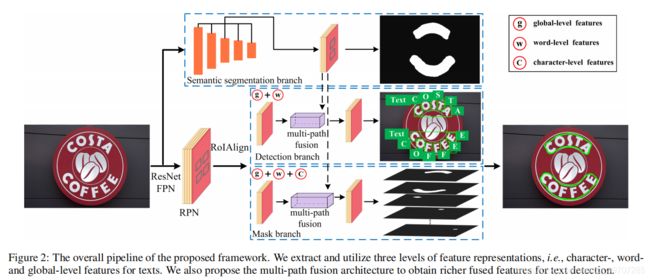
TextFuseNet网络结构主要分为三个分支:
第一个是语义分割分支( semantic segmentation branch),该分支用来提取液全局级别的特征;
另外二个是检测分支和mask分支(detection and mask branches),用来提取字符级别和单词级别的特征;
在得到三种层次的特征后,使用多路径特征融合体系结构(Multi-path Fusion Architecture),融合三者特征,生成更具代表性的特征表示,从而产生更准确的文本检测结果。
目前大部分数据集只包含单词级别的标注,很少有字符级别的标注,为解决字符级别标注数据集缺乏的问题,提出了一种弱监督学习方案,通过从单词级注释数据集学习来生成字符级注释。
总体的结构如图2所示。
2. 算法详解
2.1 网络结构
具体网络结构如图2所示,首先提取多层次的特征,然后执行多路径融合以进行文本检测。该结构主要由5部分组成,
- 使用特征金字塔(FPN)作为backbone进行多特征提取;
- 使用RPN生成文本候选框;
- 语义分割分支生成全局语义特征;
- 检测分支预测单词和字符;
- mask分支生成单词和字符的实例分割;
在TextFuseNet中,使用ResNet作为backbone,RPN生成的文本候选框作为检测和mask分支的输入,在语义分割分支来对输入图像进行语义分割,并帮助获得全局级别的特征。
mask在检测分支中,通过预测文本候选框的类别和采用边界框回归来细化文本候选框,提取和融合了单词和全局级别的特征来检测单词和字符。
mask分支,对从检测分支检测到的对象执行实例分割;
提取和融合所有字符、单词和全局级别的特征,以完成实例分割以及最后的文本检测任务。
2.2节来主要来讲解提取多层次的特征表示,在提取多特征后,多路径融合体系结构来融合不同的特征,用于检测任意形状的文本,多径融合体系结构可以有效地对多层特征进行对齐和合并,以提供健壮的文本检测,多路径融合体系结构的实现细节在2.3节中描述。
2.2 Multi-level Feature Representation
在检测器的检测和掩码分支中,通过预测文本候选框中的字符和单词,能够很容易的获得字符级别和单词级别的特征。 这里应用RoIAlign提取不同的特征,并对单词和字符进行检测。
除了字符和单词特征,还要获取全局的语义特征,如图2所示,语义分割分支是基于FPN的输出构建的。将所有特征层的特征融合到一个统一的特征表示中,并在这个统一的特征表示上执行分割,从而获得全局分段的文本检测结果。通常,使用1×1的卷积将不同特征层的特征的通道数对齐,并将特征映射调整为相同的大小,以便以后统一。
2.3 Multi-path Fusion Architecture
在获取到多级特征后,分别在检测和mask分支采用多径融合体系结构。
在检测分支中,基于从RPN获得的文本候选,提取全局和单词级特征,用于不同路径的文本检测。然后,融合这两种类型的特征,以单词和字符的形式提供文本检测。值得注意的是,在检测分支的时候,不能提取和融合字符级别的特征,因为,在执行检测之前,字符尚未被识别。在实际代码中,给定一个文本候选框,使用RoIAlign从FPN的输出特征中提取到一个大小为7×7的全局和单词特征。使用 element-wise相加融合这两个特征,然后再经过一个3×3的卷积层和一个1×1的卷积层,最终融合后的特征用于分类和坐标回归。
在mask分支,对于每个单词级实例,可以在多路径融合体系结构中融合得到相应的字符、单词和全局级别特征。图3详细说明了多路径融合结构。
在所提出的体系结构中,从不同的路径中提取多层次特征,并将它们融合起来,以获得更丰富的特征,以帮助学习更具鉴别性的特征表示。

给定一个由 r i r_i ri表示的输入单词,首先根据其与字符在字符区域上的交集的比率来识别属于这个词建议的字符结果 C i C_i Ci,这意味着如果单词框完全覆盖字符,则该比率为1,如果不覆盖字符,则为0。使用 c j c_j cj来表示字符,属于单词 r i r_i ri的字符集合 C i C_i Ci可以表示为:
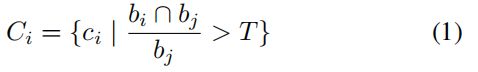
其中 b i b_i bi和 b j b_j bj分别是单词 r i r_i ri和字符实例 c j c_j cj的包围框,T是阈值,将T设为0.8。
这个公式中 c i c_i ci应该是写错了应该是 c j c_j cj,这个公式的解释的比较麻烦,根据个人理解简单画了一下,方便理解,如下图所示:

每个单词 r i r_i ri中字符的数量不是固定的,从0到数百不等,所以需要将集合 C i C_i Ci中字符的特征融合为一个统一的表示。在代码中,首先使用RoIAlign提取 C i C_i Ci中每个字符的大小为14×14的相应特征,然后通过 element-wise求和融合这些特征映射。再通过一个3×3卷积层和一个1×1卷积可以得到最终的字符级特征。
通过进一步应用RoIAlign提取单词的特征和相应的全局语义特征,通过element-wise求和将这三个层次的特征融合起来,然后通过一个3×3卷积层和一个1×1卷积层去获得更丰富的特征。最后融合的特征用于实例分割。
3.4 loss函数
TextFuseNet总体损失函数由四部分组成,其中 L r p n L_{rpn} Lrpn、 L s e g L_{seg} Lseg、 L d e t L_{det} Ldet和 L m a s k L_{mask} Lmask分别是RPN、语义分割分支、检测分支和掩码分支的loss函数。
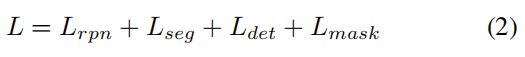
3.5 Weakly Supervised Learning
TextFuseNet需要检测单词和字符文本,所以就需要字符级别标注的数据集,但目前大部分数据集都只是单词级别的标注,去标注字符级别的文本,十分耗时。于是本文提出一种弱监督学习机制去训练模型。
首先在一个完整的包含单词级别和字符级别的数据上预训练模型 M M M,然后对于一个新的只包含单词级别的数据集 A A A,通过预训练模型 M M M去生成字符训练样本。
具体的,用模型 M M M去预测数据集 A A A,对于数据集 A A A中每张图片,可以得到一组字符候选样本:
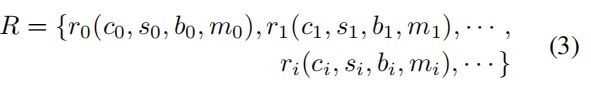
这里 c i c_i ci, s i s_i si, b i b_i bi和 m i m_i mi分别代表预测的第i个字符的类别,置信度分数,bbox和mask, r i r_i ri代表各个字符。然后通过增加置信度阈值和弱监督的词级注释,在所有生成的字符候选样本中去掉假阳样本,最后得到的正样本如下:
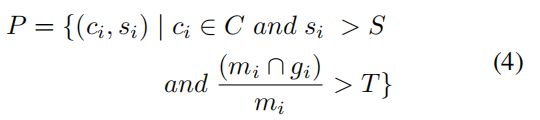
C C C代表所有检出的字符类别, S S S是区分正样本的置信度阈值, ( m i ⋂ g i ) m i \frac{(m_i\bigcap g_i)}{m_i} mi(mi⋂gi)是每个候选字符样本 r i r_i ri和它所属的单词级别的GT g i g_i gi的交并比, T T T是决定候选字符是否在单词内的阈值。由于只有单词级标注的限制,阈值 S S S设置的相对较低,有利于保持字符样本的多样性,在代码中 S S S和 T T T分别设置为0.1和0.8。最后,确定的正字符样本可以作为字符级标注,并与单词级标注相结合,以训练更鲁棒和更准确的文本检测模型。
4. 测试结果