NNDL 作业10:第六章课后题(LSTM | GRU)
文章目录
- 习题6-3 当使用公式(6.50)作为循环神经网络得状态更新公式时,分析其可能存在梯度爆炸的原因并给出解决办法.
- 习题6-4 推导LSTM网络中参数的梯度,并分析其避免梯度消失的效果
- 习题6-5 推导GRU网络中参数的梯度,并分析其避免梯度消失的效果
- 附加题 6-1P 什么时候应该用GRU? 什么时候用LSTM?
- 附加题 6-2P LSTM BP推导,并用Numpy实现
- 总结
- 参考文章

习题6-3 当使用公式(6.50)作为循环神经网络得状态更新公式时,分析其可能存在梯度爆炸的原因并给出解决办法.
公式6.50: h t = h t − 1 + g ( x t , h t − 1 ; Θ ) h_{t}=h_{t-1}+g(x_{t},h_{t-1};\Theta ) ht=ht−1+g(xt,ht−1;Θ)
令 z k = U h k − 1 + W x k + b z_{k}=Uh_{k-1}+Wx_{k}+b zk=Uhk−1+Wxk+b为在第k时刻函数g(·)的输入,在计算公式6.34中的误差项 δ t , k = ∂ L t ∂ z k \delta _{t,k}=\frac{\partial L_{t}}{\partial z_{k}} δt,k=∂zk∂Lt时,梯度可能过大,从而导致梯度过大问题。
解决方法:使用长短期记忆神经网络。
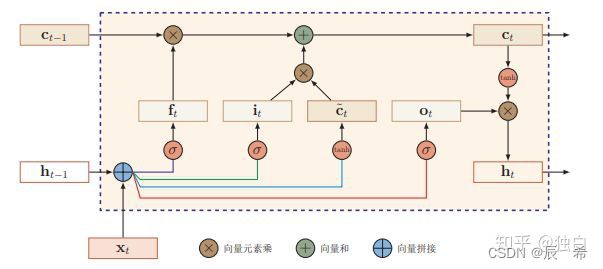
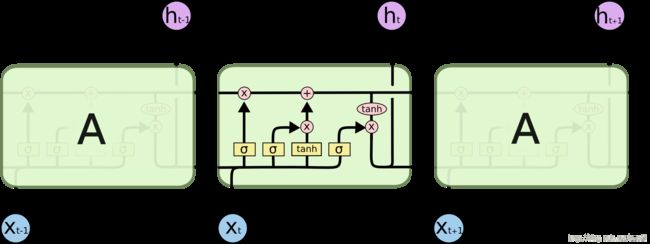
习题6-4 推导LSTM网络中参数的梯度,并分析其避免梯度消失的效果
LSTM结构图:


习题6-5 推导GRU网络中参数的梯度,并分析其避免梯度消失的效果
GRU结构图:

它只有两个门,对应输出更新门(update gate)向量:和重置门(reset gate)向量:,更新门负责控制上一时刻状态信息对当前时刻状态的影响,更新门的值越大说明上一时刻的状态信息带入越多。而重置门负责控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略的越多。注意前两个,更新门和重置门的表达式,表示两个向量连接,表示矩阵相乘,表示sigmoid函数。
接下来,“重置”之后的重置门向量 与前一时刻状态卷积 ,再将与输入进行拼接,再通过激活函数tanh来将数据放缩到-1~1的范围内。这里包含了输入数据,并且将上一时刻状态的卷积结果添加到当前的隐藏状态,通过此方法来记忆当前时刻的状态。
最后一个步骤是更新记忆阶段,此阶段同时进遗忘和记忆两个步骤,使用同一个门控同时进行遗忘和选择记忆(LSTM是多个门控制)
![]() 对隐藏的原状态,选择性地遗忘。
对隐藏的原状态,选择性地遗忘。
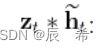 对当前节点信息,进行选择性的记忆。
对当前节点信息,进行选择性的记忆。

GRU它引⼊了重置⻔(reset gate)和更新⻔(update gate) 的概念,从而修改了循环神经⽹络中隐藏状态的计算⽅式。GRU的优点是这是个更加简单的模型,所以更容易创建一个更大的网络,而且它只有两个门,在计算性上也运行得更快,它可以扩大模型的规模。
附加题 6-1P 什么时候应该用GRU? 什么时候用LSTM?
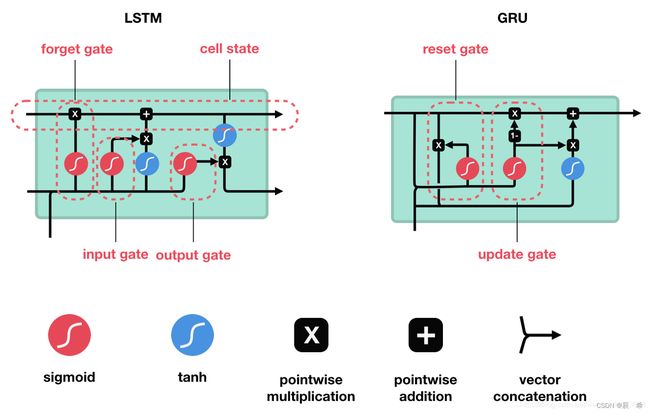
GRU和LSTM的区别在于:
①GRU通过更新门来控制上一时刻的信息传递和当前时刻计算的隐层信息传递。GRU中由于是一个参数进行控制,因而可以选择完全记住上一时刻而不需要当前计算的隐层值,或者完全选择当前计算的隐层值而忽略上一时刻的所有信息,最后一种情况就是无论是上一时刻的信息还是当前计算的隐层值都选择传递到当前时刻隐层值,只是选择的比重不同。而LSTM是由两个参数(遗忘门和输入门)来控制更新的,他们之间并不想GRU中一样只是由一个参数控制,因而在比重选择方面跟GRU有着很大的区别,例如它可以既不选择上一时刻的信息,也不选择当前计算的隐层值信息(输入门拒绝输入,遗忘门选择遗忘)。
②GRU要在上一时刻的隐层信息的基础上乘上一个重置门,而LSTM无需门来对其控制,LSTM必须考虑上一时刻的隐层信息对当前隐层的影响,而GRU则可选择是否考虑上一时刻的隐层信息对当前时刻的影响。
③ 一般来说两者效果差不多,性能在很多任务上也不分伯仲。GRU参数更少,收敛更快;数据量很大时,LSTM效果会更好一些,因为LSTM参数也比GRU参数多一些。
LSTM简单来说:
LSTM是用来解决RNN的梯度问题,起到了有效缓解作用
LSTM比RNN多出了几个门,用来控制信息的流动
LSTM的效率要比RNN低,毕竟计算上多出了更多步骤
LSTM能比RNN捕获更长的依赖关系
实际上,任何的深度学习模型均存在梯度问题,这也是需要从优化的角度解决的一个比较棘手的问题。
LSTM 和 GRU对于梯度消失或者梯度爆炸的问题处理方法主要是:
对于梯度消失: 由于它们都有特殊的方式存储”记忆”,那么以前梯度比较大的”记忆”不会像简单的RNN一样马上被抹除,因此可以一定程度上克服梯度消失问题。
对于梯度爆炸:用来克服梯度爆炸的问题就是gradient clipping,也就是当计算的梯度超过阈值或者小于阈值的时候,便把此时的梯度设置成或。
附加题 6-2P LSTM BP推导,并用Numpy实现

import numpy as np
import torch
def sigmoid(x):
return 1 / (1 + np.exp(-x))
class LSTMCell:
def __init__(self, weight_ih, weight_hh, bias_ih, bias_hh):
self.weight_ih = weight_ih
self.weight_hh = weight_hh
self.bias_ih = bias_ih
self.bias_hh = bias_hh
self.dc_prev = None
self.dh_prev = None
self.weight_ih_grad_stack = []
self.weight_hh_grad_stack = []
self.bias_ih_grad_stack = []
self.bias_hh_grad_stack = []
self.x_stack = []
self.dx_list = []
self.dh_prev_stack = []
self.h_prev_stack = []
self.c_prev_stack = []
self.h_next_stack = []
self.c_next_stack = []
self.input_gate_stack = []
self.forget_gate_stack = []
self.output_gate_stack = []
self.cell_memory_stack = []
def __call__(self, x, h_prev, c_prev):
a_vector = np.dot(x, self.weight_ih.T) + np.dot(h_prev, self.weight_hh.T)
a_vector += self.bias_ih + self.bias_hh
h_size = np.shape(h_prev)[1]
a_i = a_vector[:, h_size * 0:h_size * 1]
a_f = a_vector[:, h_size * 1:h_size * 2]
a_c = a_vector[:, h_size * 2:h_size * 3]
a_o = a_vector[:, h_size * 3:]
input_gate = sigmoid(a_i)
forget_gate = sigmoid(a_f)
cell_memory = np.tanh(a_c)
output_gate = sigmoid(a_o)
c_next = (forget_gate * c_prev) + (input_gate * cell_memory)
h_next = output_gate * np.tanh(c_next)
self.x_stack.append(x)
self.h_prev_stack.append(h_prev)
self.c_prev_stack.append(c_prev)
self.c_next_stack.append(c_next)
self.h_next_stack.append(h_next)
self.input_gate_stack.append(input_gate)
self.forget_gate_stack.append(forget_gate)
self.output_gate_stack.append(output_gate)
self.cell_memory_stack.append(cell_memory)
self.dc_prev = np.zeros_like(c_next)
self.dh_prev = np.zeros_like(h_next)
return h_next, c_next
def backward(self, dh_next):
x_stack = self.x_stack.pop()
h_prev = self.h_prev_stack.pop()
c_prev = self.c_prev_stack.pop()
c_next = self.c_next_stack.pop()
input_gate = self.input_gate_stack.pop()
forget_gate = self.forget_gate_stack.pop()
output_gate = self.output_gate_stack.pop()
cell_memory = self.cell_memory_stack.pop()
dh = dh_next + self.dh_prev
d_tanh_c = dh * output_gate * (1 - np.square(np.tanh(c_next)))
dc = d_tanh_c + self.dc_prev
dc_prev = dc * forget_gate
self.dc_prev = dc_prev
d_input_gate = dc * cell_memory
d_forget_gate = dc * c_prev
d_cell_memory = dc * input_gate
d_output_gate = dh * np.tanh(c_next)
d_ai = d_input_gate * input_gate * (1 - input_gate)
d_af = d_forget_gate * forget_gate * (1 - forget_gate)
d_ao = d_output_gate * output_gate * (1 - output_gate)
d_ac = d_cell_memory * (1 - np.square(cell_memory))
da = np.concatenate((d_ai, d_af, d_ac, d_ao), axis=1)
dx = np.dot(da, self.weight_ih)
dh_prev = np.dot(da, self.weight_hh)
self.dh_prev = dh_prev
self.dx_list.insert(0, dx)
self.dh_prev_stack.append(dh_prev)
self.weight_ih_grad_stack.append(np.dot(da.T, x_stack))
self.weight_hh_grad_stack.append(np.dot(da.T, h_prev))
db = np.sum(da, axis=0)
self.bias_ih_grad_stack.append(db)
self.bias_hh_grad_stack.append(db)
return dh_prev
np.random.seed(123)
torch.random.manual_seed(123)
np.set_printoptions(precision=6, suppress=True)
lstm_torch = torch.nn.LSTMCell(2, 3).double()
lstm_numpy = LSTMCell(lstm_torch.weight_ih.data.numpy(),
lstm_torch.weight_hh.data.numpy(),
lstm_torch.bias_ih.data.numpy(),
lstm_torch.bias_hh.data.numpy())
x_numpy = np.random.random((4, 2))
x_torch = torch.tensor(x_numpy, requires_grad=True)
h_numpy = np.random.random((4, 3))
h_torch = torch.tensor(h_numpy, requires_grad=True)
c_numpy = np.random.random((4, 3))
c_torch = torch.tensor(c_numpy, requires_grad=True)
dh_numpy = np.random.random((4, 3))
dh_torch = torch.tensor(dh_numpy, requires_grad=True)
h_numpy, c_numpy = lstm_numpy(x_numpy, h_numpy, c_numpy)
h_torch, c_torch = lstm_torch(x_torch, (h_torch, c_torch))
h_torch.backward(dh_torch)
dh_numpy = lstm_numpy.backward(dh_numpy)
print("h_numpy :\n", h_numpy)
print("h_torch :\n", h_torch.data.numpy())
print("---------------------------------")
print("c_numpy :\n", c_numpy)
print("c_torch :\n", c_torch.data.numpy())
print("---------------------------------")
print("dx_numpy :\n", np.sum(lstm_numpy.dx_list, axis=0))
print("dx_torch :\n", x_torch.grad.data.numpy())
print("---------------------------------")
print("w_ih_grad_numpy :\n",
np.sum(lstm_numpy.weight_ih_grad_stack, axis=0))
print("w_ih_grad_torch :\n",
lstm_torch.weight_ih.grad.data.numpy())
print("---------------------------------")
print("w_hh_grad_numpy :\n",
np.sum(lstm_numpy.weight_hh_grad_stack, axis=0))
print("w_hh_grad_torch :\n",
lstm_torch.weight_hh.grad.data.numpy())
print("---------------------------------")
print("b_ih_grad_numpy :\n",
np.sum(lstm_numpy.bias_ih_grad_stack, axis=0))
print("b_ih_grad_torch :\n",
lstm_torch.bias_ih.grad.data.numpy())
print("---------------------------------")
print("b_hh_grad_numpy :\n",
np.sum(lstm_numpy.bias_hh_grad_stack, axis=0))
print("b_hh_grad_torch :\n",
lstm_torch.bias_hh.grad.data.numpy())
运行结果:
h_numpy :
[[ 0.055856 0.234159 0.138457]
[ 0.094461 0.245843 0.224411]
[ 0.020396 0.086745 0.082545]
[-0.003794 0.040677 0.063094]]
h_torch :
[[ 0.055856 0.234159 0.138457]
[ 0.094461 0.245843 0.224411]
[ 0.020396 0.086745 0.082545]
[-0.003794 0.040677 0.063094]]
---------------------------------
c_numpy :
[[ 0.092093 0.384992 0.213364]
[ 0.151362 0.424671 0.318313]
[ 0.033245 0.141979 0.120822]
[-0.0061 0.062946 0.094999]]
c_torch :
[[ 0.092093 0.384992 0.213364]
[ 0.151362 0.424671 0.318313]
[ 0.033245 0.141979 0.120822]
[-0.0061 0.062946 0.094999]]
---------------------------------
dx_numpy :
[[-0.144016 0.029775]
[-0.229789 0.140921]
[-0.246041 -0.009354]
[-0.088844 0.036652]]
dx_torch :
[[-0.144016 0.029775]
[-0.229789 0.140921]
[-0.246041 -0.009354]
[-0.088844 0.036652]]
---------------------------------
w_ih_grad_numpy :
[[-0.056788 -0.036448]
[ 0.018742 0.014428]
[ 0.007827 0.024828]
[ 0.07856 0.05437 ]
[ 0.061267 0.045952]
[ 0.083886 0.0655 ]
[ 0.229755 0.156008]
[ 0.345218 0.251984]
[ 0.430385 0.376664]
[ 0.014239 0.011767]
[ 0.054866 0.044531]
[ 0.04654 0.048565]]
w_ih_grad_torch :
[[-0.056788 -0.036448]
[ 0.018742 0.014428]
[ 0.007827 0.024828]
[ 0.07856 0.05437 ]
[ 0.061267 0.045952]
[ 0.083886 0.0655 ]
[ 0.229755 0.156008]
[ 0.345218 0.251984]
[ 0.430385 0.376664]
[ 0.014239 0.011767]
[ 0.054866 0.044531]
[ 0.04654 0.048565]]
---------------------------------
w_hh_grad_numpy :
[[-0.037698 -0.048568 -0.021069]
[ 0.016749 0.016277 0.007556]
[ 0.035743 0.02156 0.000111]
[ 0.060824 0.069505 0.029101]
[ 0.060402 0.051634 0.025643]
[ 0.068116 0.06966 0.035544]
[ 0.168965 0.217076 0.075904]
[ 0.248277 0.290927 0.138279]
[ 0.384974 0.401949 0.167006]
[ 0.015448 0.0139 0.005158]
[ 0.057147 0.048975 0.022261]
[ 0.057297 0.048308 0.017745]]
w_hh_grad_torch :
[[-0.037698 -0.048568 -0.021069]
[ 0.016749 0.016277 0.007556]
[ 0.035743 0.02156 0.000111]
[ 0.060824 0.069505 0.029101]
[ 0.060402 0.051634 0.025643]
[ 0.068116 0.06966 0.035544]
[ 0.168965 0.217076 0.075904]
[ 0.248277 0.290927 0.138279]
[ 0.384974 0.401949 0.167006]
[ 0.015448 0.0139 0.005158]
[ 0.057147 0.048975 0.022261]
[ 0.057297 0.048308 0.017745]]
---------------------------------
b_ih_grad_numpy :
[-0.084682 0.032588 0.046412 0.126449 0.111421 0.139337 0.361956
0.539519 0.761838 0.027649 0.103695 0.099405]
b_ih_grad_torch :
[-0.084682 0.032588 0.046412 0.126449 0.111421 0.139337 0.361956
0.539519 0.761838 0.027649 0.103695 0.099405]
---------------------------------
b_hh_grad_numpy :
[-0.084682 0.032588 0.046412 0.126449 0.111421 0.139337 0.361956
0.539519 0.761838 0.027649 0.103695 0.099405]
b_hh_grad_torch :
[-0.084682 0.032588 0.046412 0.126449 0.111421 0.139337 0.361956
0.539519 0.761838 0.027649 0.103695 0.099405]
Process finished with exit code 0
总结
本次实验公式推导参考了网上的推导过程,对我来说还是有难度的。对于LSTM网络和GRU网络有了更多的了解,了解到GRU 输入输出的结构与普通的 RNN 相似,其中的内部思想与 LSTM 似。GRU参数更少,收敛更快;数据量很大时,LSTM效果会更好一些,因为LSTM参数也比GRU参数多一些。
参考文章
https://blog.csdn.net/weixin_44023658
https://blog.csdn.net/kobepaul123
https://blog.csdn.net/katrina1rani/article/details/114367195
https://blog.csdn.net/weixin_39940788/article/details/110278037