【transformer】|基础知识
transformer基础知识
Transformer网络结构:
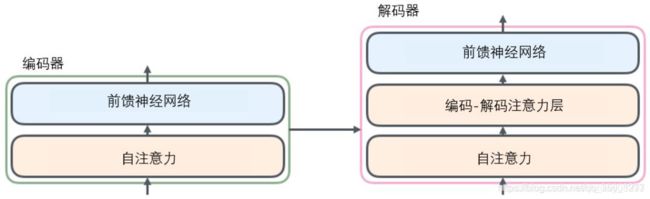
如图所示,是Transformer的整体网络结构,主要是由编码器和解码器两部分组成。如图3是编码器和解码器的详细网络结构,编码器由两部分组成自注意力和前馈神经网络层,
输入
首先通过Word2Vec等词嵌入方法将输入语料转化成特征向量。以512为例。
编码器
自注意力层
从编码器输入的句子首先会经过一个自注意力(self-attention)层,这层帮助编码器在对每个单词编码时关注输入句子的其他单词。我们将在稍后的文章中更深入地研究自注意力。
得到一个加权之后的特征向量z,![这个 z便是论文公式1中的 [公式]](http://img.e-com-net.com/image/info8/da438d918b984b3c9d8dc3bfa2dc91e4.jpg)
其核心内容是为输入向量的每个单词学习一个权重,例如在下面的例子中我们判断it代指的内容,
The animal didn't cross the street because it was too tired
通过加权之后可以得到类似下图的加权情况

在self-attention中,每个单词有3个不同的向量,它们分别是Query向量( Q ),Key向量( K )和Value向量( V ).长度dk均是64。它们是通过3个不同的权值矩阵由嵌入向量X乘以三个不同的权值矩阵 W Q W^Q WQ W K W^K WK W V W^V WV得到,其中三个矩阵的尺寸也是相同的。均是 512*64

计算过程
- 将输入单词转化成嵌入向量;
- 根据嵌入向量得到q,k,v
- 为每个向量计算一个score score=qk
- 为了梯度的稳定,Transformer使用了score归一化,即除以

- 对score施以softmax激活函数使得和为一且都大于零
- softmax点乘Value值 得到加权的每个输入向量的评分 V
- 相加之后得到最终的输出结果 z
过程如图
此处dk=64

实际计算过程中是采用基于矩阵的计算方式
1 . 首先计算QKV :将嵌入向量转为矩阵形式,乘以训练得到的(WQ, WK, WV)

X矩阵中的每一行对应输入句子中的一个单词。(512,图中维度为4)
q/k/v vectors (64, or 图中维度为3)
2. 将步骤二到步骤六压缩到一个公式中

FFN
自注意力层的输出会传递到前馈(feed-forward)神经网络中。每个位置的单词对应的前馈神经网络都完全一样(译注:另一种解读就是一层窗口为一个单词的一维卷积神经网络)。
有两层,第一层的激活函数是ReLU,第二层是一个线性激活函数,可以表示为:

解码器在编码器的基础上增加了编码-解码注意力层。用来关注输入句子的相关部分。
解码器将少量固定数量的学习的位置嵌入作为输入,我们称其为对象查询,并另外参与编码器的输出。
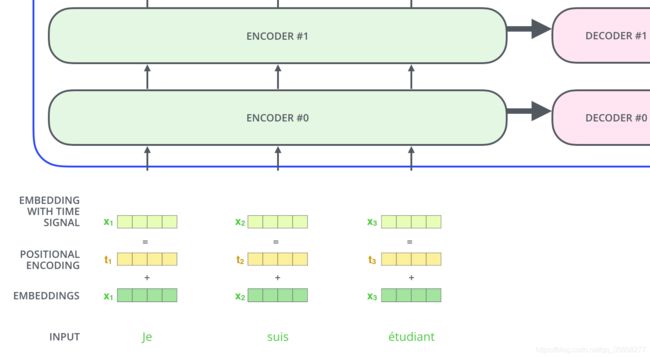
位置编码
截止目前为止,我们介绍的Transformer模型并没有捕捉顺序序列的能力,也就是说无论句子的结构怎么打乱,Transformer都会得到类似的结果。换句话说,Transformer只是一个功能更强大的词袋模型而已。
为了解决这个问题,论文中在编码词向量时引入了位置编码(Position Embedding)的特征。具体地说,位置编码会在词向量中加入了单词的位置信息,这样Transformer就能区分不同位置的单词了。
那么怎么编码这个位置信息呢?常见的模式有:a. 根据数据学习;b. 自己设计编码规则。在这里作者采用了第二种方式。那么这个位置编码该是什么样子呢?通常位置编码是一个长度为 d m o d e l d_{model} dmodel的特征向量,这样便于和词向量进行单位加的操作
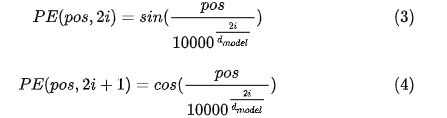
论文给出的编码公式如下
如果我们假设词嵌入的维数为4,则实际的位置编码如下:

你可以看到它从中间分裂成两半。这是因为左半部分的值由一个函数(使用正弦)生成,而右半部分由另一个函数(使用余弦)生成。然后将它们拼在一起而得到每一个位置编码向量。
解码器
编码器通过处理输入序列开启工作。顶端编码器的输出之后会变转化为一个包含向量K(键向量)和V(值向量)的注意力向量集 。这些向量将被每个解码器用于自身的“编码-解码注意力层”,而这些层可以帮助解码器关注输入序列哪些位置合适:
解码阶段的每个步骤都会输出一个输出序列(在这个例子里,是英语翻译的句子)的元素
接下来的步骤重复了这个过程,直到到达一个特殊的终止符号,它表示transformer的解码器已经完成了它的输出。每个步骤的输出在下一个时间步被提供给底端解码器,并且就像编码器之前做的那样,这些解码器会输出它们的解码结果 。另外,就像我们对编码器的输入所做的那样,我们会嵌入并添加位置编码给那些解码器,来表示每个单词的位置。
Encoder-Decoder Attention
在解码器中,Transformer block比编码器中多了个encoder-cecoder attention。在encoder-decoder attention中,Q 来自于解码器的上一个输出,K V则来自于与编码器的输出。其计算方式完全和自注意层的计算过程相同。
最终的线性变换和Softmax层
解码组件最后会输出一个实数向量。我们如何把浮点数变成一个单词?这便是线性变换层要做的工作,它之后就是Softmax层。
线性变换层是一个简单的全连接神经网络,它可以把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。
不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数。
接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。

训练过程
在训练过程中,一个未经训练的模型会通过一个完全一样的前向传播。但因为我们用有标记的训练集来训练它,所以我们可以用它的输出去与真实的输出做比较。
我们模型的输出词表在我们训练之前的预处理流程中就被设定好。
一旦我们定义了我们的输出词表,我们可以使用一个相同宽度的向量来表示我们词汇表中的每一个单词。这也被认为是一个one-hot 编码。
损失函数
比如说我们正在训练模型,现在是第一步,一个简单的例子——把“merci”翻译为“thanks”。
这意味着我们想要一个表示单词“thanks”概率分布的输出。但是因为这个模型还没被训练好,所以不太可能现在就出现这个结果。
因为模型的参数(权重)都被随机的生成,(未经训练的)模型产生的概率分布在每个单元格/单词里都赋予了随机的数值。我们可以用真实的输出来比较它,然后用反向传播算法来略微调整所有模型的权重,生成更接近结果的输出。