YOLO vs SSD
Yolo vs SSD
-
- 一、使用卷积操作的目标检测主要分为两个类型
-
- 1.two-stage方法
- 2.one-stage方法
- 二、SSD相比于YOLO的不同
-
- 1. SSD采用CNN来直接进行检测,而YOLO在全连接之后做检测。
- 2. SSD提取了不同尺度的特征图来做检测。
- 3. SSD采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes, 在Faster-RCNN中叫做锚, Anchors)。
-
- 训练过程中的先验框匹配原则
- 三、SSD具体训练过程
-
- 1. 损失函数
- 2. 预测过程
参考https://zhuanlan.zhihu.com/p/33544892
一、使用卷积操作的目标检测主要分为两个类型
1.two-stage方法
R-CNN等一系列算法。主要思路是首先通过启发式方法(selective search)或者CNN网络(RPN)产生一系列稀疏的候选框,然后对这些候选框进行分类与回归。特点是准确度高。
2.one-stage方法
如YOLO和SSD。主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,之后利用CNN提取特征后进行分类与回归。特点是速度快,但是均匀地密集采样的一个缺陷在于正样本(分类目标)和负样本(背景)不均衡,导致模型准确率低(参见Kaiming的Focal Loss)。
二、SSD相比于YOLO的不同
SSD的全称为Single Shot MultiBox Detector,和YOLO相比主要的不同点如下:
1. SSD采用CNN来直接进行检测,而YOLO在全连接之后做检测。
与Yolo最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为m×n×p的特征图,只需要采用3×3×p 这样比较小的卷积核得到检测值。
2. SSD提取了不同尺度的特征图来做检测。
所谓多尺度即同时采用大小不同的特征图进行检测。CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2或者pool来降低特征图的大小。大尺度特征图(较靠前的特征图)用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。这里可以理解为网络靠前位置的大尺度特征图中每个单元的感受野较小,靠后位置的小尺度特征图中每个单元的感受野较大。下图中4×4的特征图大小是8×8特征图大小的1/4,但是相同大小的先验框,后者比前者融合了更多的信息,更有利于检测大物体。

3. SSD采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes, 在Faster-RCNN中叫做锚, Anchors)。
在YOLO中,每个单元相对于本身(正方形)预测多个边界框,但是真实目标的形状是多变的,YOLO需要在训练过程中自适应目标的形状。而SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,最终预测得到的边界框(bounding boxes)以这些先验框作为基准,在一定程度上减少了训练的难度。

训练过程中的先验框匹配原则
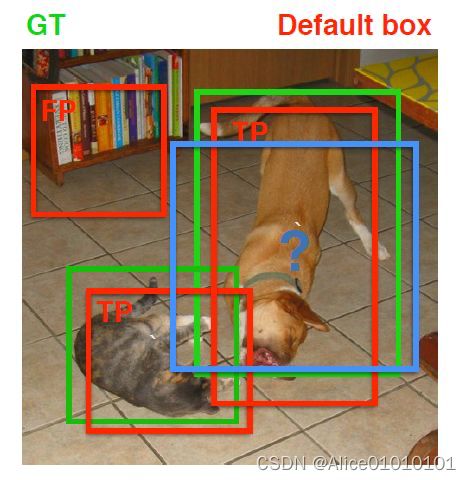
在训练过程中,首先要确定训练图片中的ground truth(真实目标)与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。在Yolo中,ground truth的中心落在哪个单元格,该单元格中与其IOU最大的边界框负责预测它。但是在SSD中却完全不一样,SSD的先验框与ground truth的匹配原则主要有两点。首先,对于图片中每个ground truth,找到与其IOU最大的先验框,该先验框与其匹配,这样,可以保证每个ground truth一定与某个先验框匹配。通常称与ground truth匹配的先验框为正样本(其实应该是先验框对应的预测box,不过由于是一一对应的就这样称呼了),反之,若一个先验框没有与任何ground truth进行匹配,那么该先验框只能与背景匹配,就是负样本。一个图片中ground truth是非常少的, 而先验框却很多,如果仅按第一个原则匹配,很多先验框会是负样本,正负样本极其不平衡,所以需要第二个原则。第二个原则是:对于剩余的未匹配先验框,若某个ground truth的 [公式] 大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。这意味着某个ground truth可能与多个先验框匹配,这是可以的。但是反过来却不可以,因为一个先验框只能匹配一个ground truth,如果多个ground truth与某个先验框 [公式] 大于阈值,那么先验框只与IOU最大的那个ground truth进行匹配。第二个原则一定在第一个原则之后进行,仔细考虑一下这种情况,如果某个ground truth所对应最大 [公式] 小于阈值,并且所匹配的先验框却与另外一个ground truth的 [公式] 大于阈值,那么该先验框应该匹配谁,答案应该是前者,首先要确保某个ground truth一定有一个先验框与之匹配。但是,这种情况我觉得基本上是不存在的。由于先验框很多,某个ground truth的最大 [公式] 肯定大于阈值,所以可能只实施第二个原则既可以了,这里的TensorFlow版本就是只实施了第二个原则,但是这里的Pytorch两个原则都实施了。图8为一个匹配示意图,其中绿色的GT是ground truth,红色为先验框,FP表示负样本,TP表示正样本。
尽管一个ground truth可以与多个先验框匹配,但是ground truth相对先验框还是太少了,所以负样本相对正样本会很多。为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
三、SSD具体训练过程
1. 损失函数
训练样本确定了,然后就是损失函数了。损失函数定义为位置误差(locatization loss, loc)与置信度误差(confidence loss, conf)的加权和:
L ( x , c , l , g ) = 1 N ( L c o n f ( x , c ) + α L l o c ( x , l , g ) ) L(x,c,l,g)=\frac{1}{N}(L_{conf}(x,c)+\alpha L_{loc}(x,l,g)) L(x,c,l,g)=N1(Lconf(x,c)+αLloc(x,l,g))
对于置信度误差,采用softmax loss:

2. 预测过程
2.1 对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度值,并过滤掉属于背景的预测框。
2.2 根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据先验框得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。
2.3 解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。
2.4 最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了。