金融风控训练营赛题概况知识学习笔记
本学习笔记为阿里云天池龙珠计划金融风控训练营的学习内容,学习链接为:https://tianchi.aliyun.com/notebook-ai/detail?spm=5176.20850282.J_3678908510.2.f2984d57wKRgrA&postId=170948
一、学习知识点概要
理解赛题数据和目标,清楚评分体系,熟悉比赛流程。
二、学习内容
首先,我了解了赛题概况,知道了竞赛采用的是AUC作为评价指标。AUC被定义为ROC曲线下与坐标轴围成的面积。并了解了常见的评估指标:
1、混淆矩阵(Confuse Matrix)
- (1)若一个实例是正类,并且被预测为正类,即为真正类TP(True Positive )
- (2)若一个实例是正类,但是被预测为负类,即为假负类FN(False Negative )
- (3)若一个实例是负类,但是被预测为正类,即为假正类FP(False Positive )
- (4)若一个实例是负类,并且被预测为负类,即为真负类TN(True Negative )
2、准确率(Accuracy) 准确率是常用的一个评价指标,但是不适合样本不均衡的情况。
Accuracy=TP+TNTP+TN+FP+FNAccuracy=TP+TNTP+TN+FP+FN
3、精确率(Precision) 又称查准率,正确预测为正样本(TP)占预测为正样本(TP+FP)的百分比。
Precision=TPTP+FPPrecision=TPTP+FP
4、召回率(Recall) 又称为查全率,正确预测为正样本(TP)占正样本(TP+FN)的百分比。
Recall=TPTP+FNRecall=TPTP+FN
5、F1 Score 精确率和召回率是相互影响的,精确率升高则召回率下降,召回率升高则精确率下降,如果需要兼顾二者,就需要精确率、召回率的结合F1 Score。F1−Score=21Precision+1RecallF1−Score=21Precision+1Recall
6、P-R曲线(Precision-Recall Curve) P-R曲线是描述精确率和召回率变化的曲线
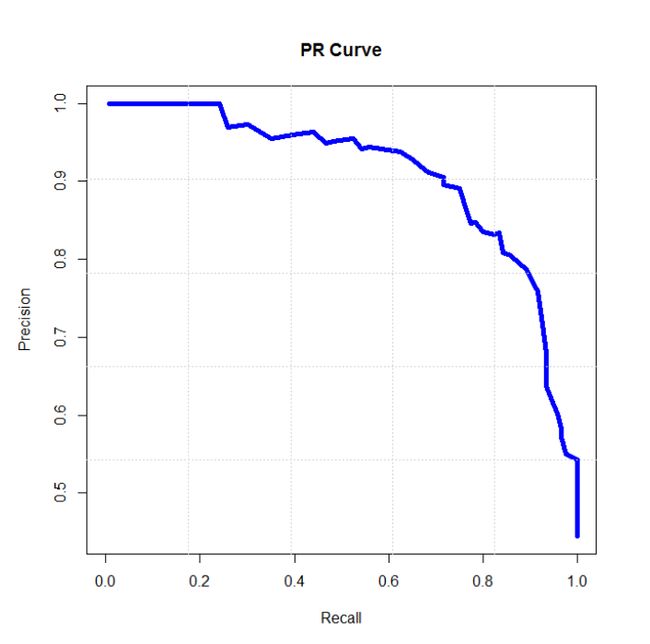
7、ROC(Receiver Operating Characteristic)
- ROC空间将假正例率(FPR)定义为 X 轴,真正例率(TPR)定义为 Y 轴。
TPR:在所有实际为正例的样本中,被正确地判断为正例之比率。TPR=TPTP+FNTPR=TPTP+FNFPR:在所有实际为负例的样本中,被错误地判断为正例之比率。FPR=FPFP+TNFPR=FPFP+TN
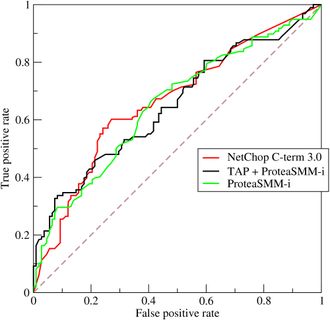
8、AUC(Area Under Curve) AUC(Area Under Curve)被定义为 ROC曲线 下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
对于金融风控预测类常见的评估指标如下:
1、KS(Kolmogorov-Smirnov) KS统计量由两位苏联数学家A.N. Kolmogorov和N.V. Smirnov提出。在风控中,KS常用于评估模型区分度。区分度越大,说明模型的风险排序能力(ranking ability)越强。 K-S曲线与ROC曲线类似,不同在于
- ROC曲线将真正例率和假正例率作为横纵轴
- K-S曲线将真正例率和假正例率都作为纵轴,横轴则由选定的阈值来充当。 公式如下:KS=max(TPR−FPR)KS=max(TPR−FPR)KS不同代表的不同情况,一般情况KS值越大,模型的区分能力越强,但是也不是越大模型效果就越好,如果KS过大,模型可能存在异常,所以当KS值过高可能需要检查模型是否过拟合。以下为KS值对应的模型情况,但此对应不是唯一的,只代表大致趋势。
| KS(%) | 好坏区分能力 |
|---|---|
| 20以下 | 不建议采用 |
| 20-40 | 较好 |
| 41-50 | 良好 |
| 51-60 | 很强 |
| 61-75 | 非常强 |
| 75以上 | 过于高,疑似存在问题 |
我还学到了读取数据的代码。第一种通过wget命令从链接直接下载数据到dsw
# 导入数据读取模块
import pandas as pd# 方法一:直接下载到dsw本地,这样的好处是后面数据读取会快点,但是直接下载到本地会占用比较多的内存
# 下载测试数据集 41.33mb
!wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/FRC/data_set/testA.csv
# 下载训练数据集 166.77mb
!wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/FRC/data_set/train.csvtrain = pd.read_csv('train.csv')
testA = pd.read_csv('testA.csv')第二种是直接利用pandas读取链接数据
# 方法二:直接读取链接数据,这样的好处是不占dsw内存,但是读取速度相对会比较慢点
train = pd.read_csv('http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/FRC/data_set/train.csv')
testA = pd.read_csv('http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/FRC/data_set/testA.csv')
print('Train data shape:',train.shape)
print('TestA data shape:',testA.shape)train.head()三、学习问题与解答
暂时没有问题
四、学习思考与总结
通过这次学习,我了解了赛题的基本状况和竞赛的评估指标。了解了关于混淆矩阵的基本知识,学到了如何写代码来读取数据。