Pytorch Tutorial学习笔记(3)
NEURAL NETWORKS
神经网络可以通过torch.nn包进行构建。
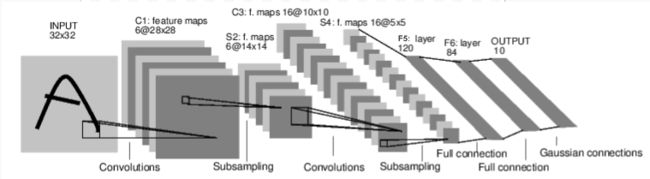
官网一个图像分类的案例神经网络模型如下图:
训练神经网络的典型步骤:
- 定义神经网络结构(即模型中可以学习的参数)
- 在输入数据集上进行迭代
- 通过神经网络处理输入
- 计算损失函数(输出的预测值与正确值之间的差异)
- 通过神经网络的参数反向传递梯度值
- 更新神经网络的参数(通常为梯度下降法)
一、定义神经网络
关于搭建神经网络的模块和损失函数参考官方网址:神经网络模块和损失函数
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module): # 类定义 nn.module是父类
def __init__(self): # 初始化:定义一些需要用到的神经层
super(Net, self).__init__() # super(type[, object-or-type])函数调用父类,然后__init__()表示父类中的初始化
# 一个图片的输入通道,6个输出通过,5x5的filter的卷积层
self.conv1 = nn.Conv2d(1, 6, 5)
# 6个输入通道,16个输出通道,5x5的filter的卷积层
self.conv2 = nn.Conv2d(6, 16, 5)
# 需要的线性层y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x): # 定义前向传递的顺序
# 先通过conv1卷积,再通过2x2的窗口进行最大值池化
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 接着通过conv2卷积,再通过2x2窗口进行最大值池化(窗口是正方形的可以只写一个2)
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
# 扁平化
x = torch.flatten(x, 1)
# 经过fc1线性全连接层,再通过relu激活函数
x = F.relu(self.fc1(x))
# 经过fc2线性全连接层,再通过relu
x = F.relu(self.fc2(x))
# 通过fc3线性全连接层最终得到输出
x = self.fc3(x)
return x
net = Net()
print(net)
print输出的该神经网络结构为:
Net(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
网络中的参数可以通过net.parameters()获得:
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1的权重参数
10
torch.Size([6, 1, 5, 5])
尝试给一个输入:
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)
tensor([[ 0.0452, 0.0800, 0.0802, 0.0782, -0.0723, -0.1265, -0.0180, -0.0210,-0.0678, 0.0310]], grad_fn=
)
注意:input应该是一个batch,即使是一个sample,也应该写成4维(nSamples, nChannels, Height, Width)。如果需要输入一个sample,使用input.unsqueeze(0),再输入到net里面。
将所有参数的梯度缓存归零,并使用随机梯度反向传递:
net.zero_grad()
out.backward(torch.randn(1, 10)) #?为什么需要随机梯度,这里只是给个实例吗?
二、计算损失函数
例如使用均方误差作为损失函数:
output = net(input)
target = torch.randn(10) # 这里先随便给一个目标
target = target.view(1, -1) # view用来改变形状,这里是让target变成1行,使target跟输出的大小对应
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)
tensor(1.0392, grad_fn=
)
使用loss.grad_fn属性将会看到类似这样的计算图:
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> flatten -> linear -> relu -> linear -> relu -> linear
-> MSELoss
-> loss
例如:(下面的next其实顺序是从后往前看,因为grad反向传递)
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU
三、Backprop反向传递
net.zero_grad() # 梯度归零
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
conv1.bias.grad before backward
tensor([0., 0., 0., 0., 0., 0.])
conv1.bias.grad after backward
tensor([-0.0202, -0.0049, 0.0267, -0.0009, 0.0126, 0.0261])
四、更新参数
手动使用SGD方法更新:
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
或者使用优化模块更新:
import torch.optim as optim
# 创建优化器
optimizer = optim.SGD(net.parameters(), lr=0.01)
# in your training loop: 在一个batch的训练循环中:
optimizer.zero_grad() # 梯度归零
output = net(input) # 计算输出
loss = criterion(output, target) # 计算损失函数(这里用的criterion)
loss.backward() # 反向传递计算梯度
optimizer.step() # 参数更新
参考网址:神经网络pytorch官方示例