对比学习火了
目录
前言
近期的一些paper
simsce
ConSERT
SCCL
CLEA
ERICA
QuantiDCE
更多资料
应用
总结
前言
最近对比学习火起来了,其思想特别简单但有效,总结起来就是:
对一条样本x1通过数据增强得到x2,那么这就是一对正样本对,和其他样本就是负样本对。
通常的做法就是:一个batch假设大小是M(假设其中一个样本是x1),那么通过数据增强得到2M(x1数据增强得到x2),正样本就是x1和x2,负样本就是x1和batch内其他的样本。
由于是在nlp的,这里重点关注一下文本领域的对比学习【其实对比学习起源于图谱领域】,更详细的一些综述可以看看:
对 比 学 习 小 综 述
细节满满!理解对比学习和SimCSE,就看这6个知识点
一文梳理2020年大热的对比学习模型
我分析了ACL21论文列表,发现对比学习已经...
文本领域大家发paper的思路点,主要就是围绕在
(1) 数据增强的方式上:比如替换词,dropout等等
(2)一些其他思路应用上:比如多模态,x1是图片,x2是图片对应的文字等等。
近期的一些paper
截止目前【2021.6.16】,已经有很多paper,抢到了这个风口,发了一波paper,一起看看都有哪些吧。这里简单列举了几个。
simsce
其用来做无监督语义相识度的,主要创新点就是:数据增强用dropout
是不是很简单,是不是很意外,没错!只需要dropout一下就可以得到很好的效果【截止目前2021.6.16,其依然是一个可以称得上sota的模型】。
关于这方面的解读可以详细看笔者的另外一篇博客,这里不再累述:
无监督文本相识度_爱吃火锅的博客-CSDN博客
https://github.com/Mryangkaitong/unsupervised_learning/tree/main/Semantic%20similarity
其中苏神还给出了对比学习中使用梯度累积
对比学习可以使用梯度累积吗? - 科学空间|Scientific Spaces
另外drop这是数据增强对比思想还可以辅助有监督学习,也大大提高了效果:
又是Dropout两次!这次它做到了有监督任务的SOTA
ESimCSE
simsce的加强版:主要创新就是Word Repetition(单词重复)和Momentum Contrast(动量对比)解决了simsce的一些缺点。
ESimCSE:无监督语义新SOTA,引入动量对比学习扩展负样本,效果远超SimCSE
ConSERT
这是美团NLP中心知识图谱团队提出的模型,也是做无监督语义相识度的即语义表征。
论文:https://arxiv.org/abs/2105.11741
代码:GitHub - yym6472/ConSERT: Code for our ACL 2021 paper - ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
想法思路也是一样即对比学习,主要创新点就是试了一些数据增强
如对抗攻击、打乱词序、裁剪、dropout等等。
并对一些数据增强方法进行了比较得出:
Token Shuffle > Token Cutoff >> Feature Cutoff ≈ Dropout >> None
还对怎么组合这些数据增强进行了实验得到:
Token Shuffle和Feature Cutoff的组合取得了最优性能。
更详细的可以解读可以看:
ACL 2021|美团提出基于对比学习的文本表示模型,效果提升8%
SCCL
这一篇是将对比学习应用到无监督文本聚类领域。
论文:https://arxiv.org/abs/2103.12953
代码:GitHub - amazon-research/sccl: Pytorch implementation of Supporting Clustering with Contrastive Learning, NAACL 2021
该论文其实在对比学习上没有多大创新,还是前言中所学的思想,研究使用了三种数据增强:
1)Augmenter WordNet (https://github.com/QData/TextAttack)
2)Augmenter Contextual(https://github.com/makcedward/nlpaug)
3)Paraphrase via back translation (https://github.com/pytorch/fairseq/tree/master/examples/paraphraser)
其比较巧妙的是将其结合到了聚类上面。
关于这方面的解读已有:
NAACL 2021 | 对比学习横扫文本聚类任务
笔者这里不在累述,这里主要想解读一下其代码,更具体直观的看一下其怎么做的。
首先我们从大的方面看一下[cluster.py]:
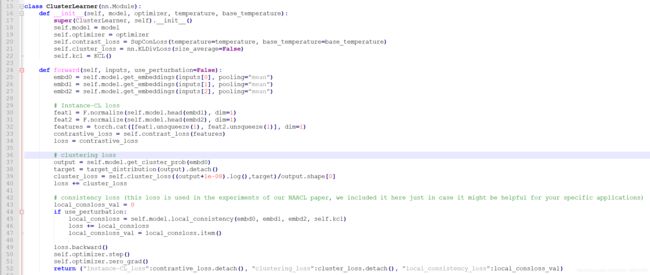
可以看到总loss主要就是Instance-CL loss和 clustering loss相加。
Instance-CL loss就是对比学习的loss【主要在contrastive_utils.py文件中】,没有什么特别的。
主要看看clustering是怎么算的loss
从37-39可以大致看到其算的是output和target的kl散度作为loss,所以重点就是看看output和target是怎么得到的。
首先是output即get_cluster_prob这个类函数【在models/Transformers.py】:
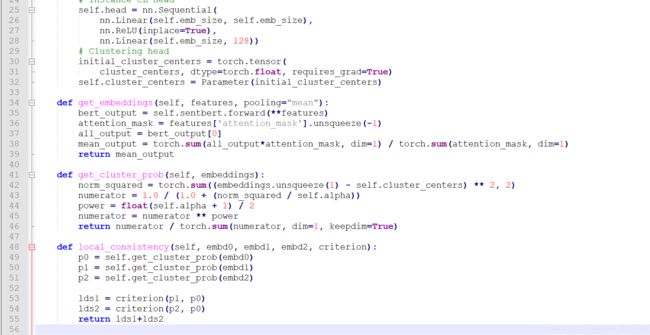
即

其中self.cluster_centers是怎么得来的呢?其实是kmeans聚类得到的结果,这个看代码就会知道了。
那么target是怎么得到的呢?即target_distribution函数【cluster_utils.py】:

即
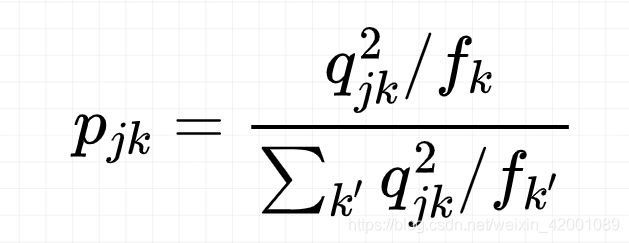
CLEA
这篇论文主要是解决没有商品相关性标签,作者也是将对比应用其中巧妙的解决了该问题
代码:https://github.com/QYQ-bot/CLEA
本质上没有太大不同,同样的思路,只不过应用到了新创建,关于详细的解读:
购物篮推荐场景太复杂?没有商品相关性标签?看作者运用对比学习统统解决
笔者不再累述。
ERICA
论文:https://arxiv.org/abs/2012.15022
代码:GitHub - thunlp/ERICA: Source code for ACL 2021 paper "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning"
这是一篇将对比学习应用到预训练(PLM)的paper。主要创新点就是提出了两个辅助性预训练任务即实体区分任务和关系判别任务,通过对比学习的方式来学习这两个任务,最后使得训练的预训练模型在关系提取、实体类别区分和问题问答上取得不错性能。
更详细的解说可以看:
ERICA: 提升预训练语言模型实体与关系理解的统一框架
笔者也看了看其源码,分享在这里
https://blog.csdn.net/weixin_42001089/article/details/118002302
QuantiDCE
论文:https://arxiv.org/abs/2106.00507
代码:https://github.com/James-Yip/QuantiDCE
这篇paper主要就是解决实现可量化的对话连贯性评估指标,主要有两个阶段即
MLR预训练(Multi-Level Ranking pre-training)
KD微调(Knowledge Distillation fine-tuning)
其中MLR阶段就是巧妙的使用了对比学习实现了三个level的loss即separation loss, compactness loss 以及 ordering loss
KD微调阶段没有什么说的,多了一个蒸馏,都比较常规,比较有看头的就是MLR预训练,更多详细的可以看博客如下,笔者这里不再累述:
对话系统答非所问?快试试这篇ACL'21的连贯性评估大法
更多资料
这里又总结和罗列了一些近期【2021年】的有关paper的论文
近期必读的5篇顶会WWW 2021【对比学习(CL)】相关论文和代码
其中,微博和其他大佬们分享了他们的一些探索,是一个pdf,难得,笔者放到网盘了,感兴趣的可以看看:
链接:https://pan.baidu.com/s/1oLt-KE1Ipi8tIFjW6OrmBw
提取码:evaj
对比学习领域近期必读的 5 篇论文 | 本周值得读 Vol.01
聊一聊大火的对比学习
从选择更高质量的正负样本角度出发:
更好的对比样本选择,更好的对比效果
应用
一些应用:
文本挖掘从小白到精通(二十六)---使用对比学习解决训练数据极少的标签甄别问题
Pairwise Supervised Contrastive Learning of Sentence Representations
论文链接:
https://arxiv.org/abs/2109.00542
EMNLP 2021 | PairSupCon:基于实例对比学习的句子表示方法
对比样本选择
再谈对比学习:更好的对比样本选择,更好的对比效果
图对比学习
顶会论文看图对比学习 (GNN+CL) 研究趋势
信息感知图对比学习
https://arxiv.org/abs/2110.15438
【NeurIPS2021】InfoGCL:信息感知图对比学习
继续!从顶会论文看对比学习的应用!
深入探讨:自监督学习的退化解是什么,到底如何避免?
从顶会论文看对比学习的应用!
图灵奖大佬 Lecun 发表对比学习新作,比 SimCLR 更好用!
EMNLP 2021 | 以对比损失为微调目标,UMass提出更强大的短语表示模型
对比+prmpt
超越SimCSE两个多点,Prompt+对比学习的文本表示新SOTA
对比表示学习必知的几种训练目标
总结
(1) 对比学习思路超级简单:同一个样本经过不同增强得到正样本对,和其他样本是负样本对,依次构建监督学习【实则整个过程是无监督】
(2) 创新点就是捣鼓数据增强
(3) 另外一个创新方向点就是正样本对可以是两种模态,比如图片和图片对应描述,负样本一样啦,其他样本是负样本
(4) 会结合具体的业务场景,将对比学习融进去作为一个提升小技术点【比如上述的聚类、对话指标量化,预训练等等】。
更新,以后在做任何任务的时候记得R-drop试一下效果:
GitHub - dropreg/R-Drop
核心代码
import torch.nn.functional as F
# define your task model, which outputs the classifier logits
model = TaskModel()
def compute_kl_loss(p, q, pad_mask=None):
p_loss = F.kl_div(F.log_softmax(p, dim=-1), F.softmax(q, dim=-1), reduction='none')
q_loss = F.kl_div(F.log_softmax(q, dim=-1), F.softmax(p, dim=-1), reduction='none')
# pad_mask is for seq-level tasks
if pad_mask is not None:
p_loss.masked_fill_(pad_mask, 0.)
q_loss.masked_fill_(pad_mask, 0.)
# You can choose whether to use function "sum" and "mean" depending on your task
p_loss = p_loss.sum()
q_loss = q_loss.sum()
loss = (p_loss + q_loss) / 2
return loss
# keep dropout and forward twice
logits = model(x)
logits2 = model(x)
# cross entropy loss for classifier
ce_loss = 0.5 * (cross_entropy_loss(logits, label) + cross_entropy_loss(logits2, label))
kl_loss = compute_kl_loss(logits, logits2)
# carefully choose hyper-parameters
loss = ce_loss + α * kl_loss
看到很多小伙伴私信和关注,为了不迷路,欢迎大家关注笔者的微信公众号,会定期发一些关于NLP的干活总结和实践心得,当然别的方向也会发,一起学习:
