图卷积神经网络4-空域卷积:空域卷积局限性分析和过平滑解决方案
知乎主页https://www.zhihu.com/people/shuang-shou-cha-dai-53 https://www.zhihu.com/people/shuang-shou-cha-dai-53
https://www.zhihu.com/people/shuang-shou-cha-dai-53
备注:本篇博客摘自某培训机构上的图神经网络讲解的视频内容,该视频关于图神经网络入门讲解、经典算法的引入和优缺点的介绍比较详细,逻辑主线也比较清晰。因此记录分享下。
前几篇介绍了谱域图卷积及空域图卷积:
图卷积神经网络1-谱域卷积:拉普拉斯变换到谱域图卷积
图卷积神经网络2-谱域卷积:SCNN/ChebNet/GCN的引入和介绍
图卷积神经网络3-空域卷积:GNN/GraphSAGE/PGC的引入和介绍
本篇博客主要讲解空域图卷积一些局限性及过平滑问题的解决思路。
目录
1:图卷积神经网络回顾
2:空域图卷积局限性分析
3:过平滑问题的若干缓解方案
4:总结
1:图卷积神经网络回顾
图卷积神经网络分类:
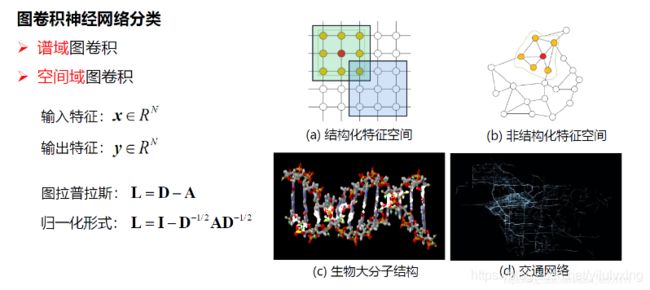
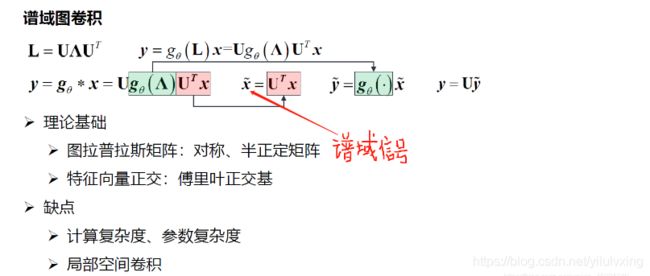
上图列出的图卷积缺点,使得谱域图卷积不能实际使用,而造成这种缺点的原因是正交基 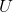 ,能不能找到另外的基来代替呢?下面来看通过切比雪夫公式来看:
,能不能找到另外的基来代替呢?下面来看通过切比雪夫公式来看:

为什么使用切比雪夫k阶多项式模拟卷积操作,这个k就代表k阶近邻呢?
原因是:因为K阶切比雪夫多项式需要对图拉普拉斯矩阵进行K次乘法计算,而图拉普拉斯矩阵表示的是图的一阶近邻关系,K次乘法下的图拉普拉斯矩阵表示图的K阶近邻关系,所以k阶可以代表邻居的阶数。
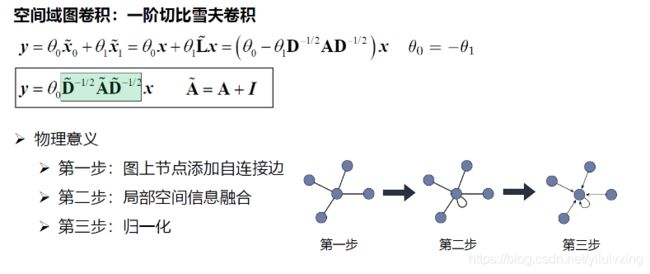
对于第一步就是![]() ,就可以做到节点添加自连接边。
,就可以做到节点添加自连接边。
对于第二步——局部空间信息融合可以这么理解:先不用管![]() ,那实际上就是
,那实际上就是![]() ,
,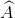 代表了图上节点的连接情况,这个就是说图卷积就是改进后的邻接矩阵乘以输入节点的特征。邻接矩阵乘以输入节点的特征为什么就特征融合呢?看下图:
代表了图上节点的连接情况,这个就是说图卷积就是改进后的邻接矩阵乘以输入节点的特征。邻接矩阵乘以输入节点的特征为什么就特征融合呢?看下图:
假设图上有三个节点,连接信息如下图所示:
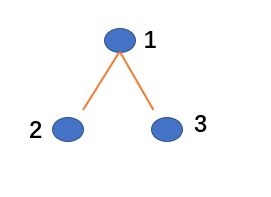
根据连接信息,进一步构造邻接矩阵A:
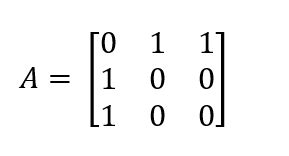
然后A与自连边融(一个单位阵)合:
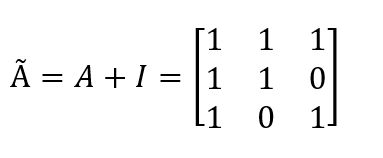
则: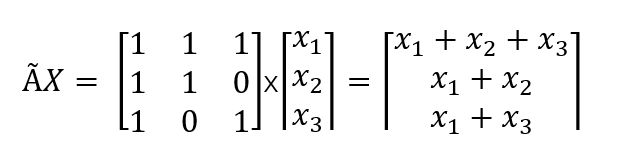
上述乘完之后每个节点可能会把其他节点的特征加进来,所以叫特征融合!
对于第三步——归一化:这里的![]() 就是对A归一化,至于为什么两边乘以一个矩阵的逆就归一化了?
就是对A归一化,至于为什么两边乘以一个矩阵的逆就归一化了?
这里就是矩阵求逆的本质了。回顾下矩阵的逆的定义,对于式子A ∗ X = B ,假如我们希望求矩阵X,那么当然是令等式两边都乘以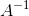 ,然后式子就变成了
,然后式子就变成了![]() 。
。
举个例子对于,单个节点运算来说,做归一化就是除以它节点的度,这样每一条邻接边信息传递的值就被规范化了,不会因为某一个节点有10条边而另一个只有1条边导致前者的影响力比后者大,因为做完归一化后者的权重只有0.1了,从单个节点上升到二维矩阵的运算,就是对矩阵求逆了,乘以矩阵的逆的本质,就是做矩阵除法完成归一化。但左右分别乘以节点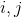 度的开方,就是考虑一条边的两边的点的度。
度的开方,就是考虑一条边的两边的点的度。
![]()
![]() 。
。
看到这里其实是很迷惑的,因为前面讲了![]() 是谱域卷积模型GCN的公式,但是怎么又成了空域图卷积?其实GCN这个模型就是从谱域到空间域的过度,是很重要的一个模型,具有奠基性的作用,既是空域又是谱域。这么说吧,谱域图卷积是空域图卷积的特例,也就是说当我们能将图卷积表达成显式的公式的时候,我们通常就叫这种模型为谱域图卷积,而没有显式地公式的图卷积一般叫空域图卷积,关于这个可以参看沈华伟老师的报告:图卷积神经网络-沈华伟: 图卷积神经网络-沈华伟_哔哩哔哩_bilibili.
是谱域卷积模型GCN的公式,但是怎么又成了空域图卷积?其实GCN这个模型就是从谱域到空间域的过度,是很重要的一个模型,具有奠基性的作用,既是空域又是谱域。这么说吧,谱域图卷积是空域图卷积的特例,也就是说当我们能将图卷积表达成显式的公式的时候,我们通常就叫这种模型为谱域图卷积,而没有显式地公式的图卷积一般叫空域图卷积,关于这个可以参看沈华伟老师的报告:图卷积神经网络-沈华伟: 图卷积神经网络-沈华伟_哔哩哔哩_bilibili.
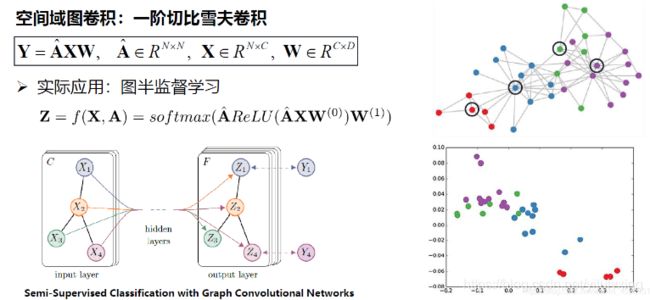
GCN用于图半监督学习论文:《Semi-Supervised Classification with Graph Convolutional Networks》
论文地址
2:空域图卷积局限性分析

这里的![]()
![]() ,FCN 就是全连接网络。
,FCN 就是全连接网络。
进一步解释上述三个公式:
- 标准形式:
 表示第
表示第  个节点的输出特征,
个节点的输出特征, 表示第 个节点的输入特征,
表示第 个节点的输入特征, 是一个可调节的标量参数,在0-1之间,
是一个可调节的标量参数,在0-1之间,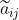 表示前面我们讲过的邻接矩阵
表示前面我们讲过的邻接矩阵  的第 行第
的第 行第 列的一个元素,
列的一个元素,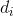 表示邻接矩阵 的度矩阵(行相加得到对角线上的元素)对角线上的一个元素,这个就是标准形式的拉普拉斯平滑
表示邻接矩阵 的度矩阵(行相加得到对角线上的元素)对角线上的一个元素,这个就是标准形式的拉普拉斯平滑 - 矩阵形式:
 表示节点的输出特征,
表示节点的输出特征, 表示节点的输入特征, 还是一个可调节的标量参数,在0-1之间,
表示节点的输入特征, 还是一个可调节的标量参数,在0-1之间, 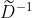 就是度矩阵的-1次方,
就是度矩阵的-1次方, 是拉普拉斯矩阵。
是拉普拉斯矩阵。 - 特殊形式:就假设=1。最后得到了
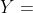 ,这个就是我们前面所讲的一阶切比雪夫多项式推导出来的公式,注意,由于
,这个就是我们前面所讲的一阶切比雪夫多项式推导出来的公式,注意,由于  是对角矩阵,所以
是对角矩阵,所以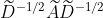 =,物理意义就是前面的三个
=,物理意义就是前面的三个

拉普拉斯平滑可以将特征进行一个低频的滤波,让中心节点的特征传播到空间近邻去,让周围节点的特征和中心节点的特征是相似的,这对于图半监督学习是很有利的性质,因为类别相同的一些节点本身就可能会连接在一起。

其中,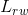 是基于随机游走的拉普拉斯矩阵,
是基于随机游走的拉普拉斯矩阵,![]() 是对称形式的,看第一个公式(第二个同理),其实定理1就是在表达:只要是节点之间有边相连,那么当经过m层(m趋于无穷大)的图卷积之后,这些节点的特征都会趋于
是对称形式的,看第一个公式(第二个同理),其实定理1就是在表达:只要是节点之间有边相连,那么当经过m层(m趋于无穷大)的图卷积之后,这些节点的特征都会趋于 。
。

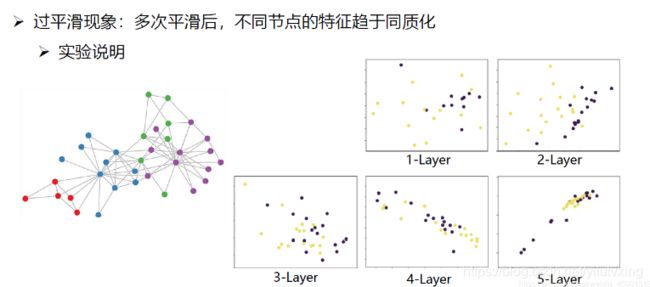
既然深层的GCN会使模型过平滑,那么浅层的GCN呢
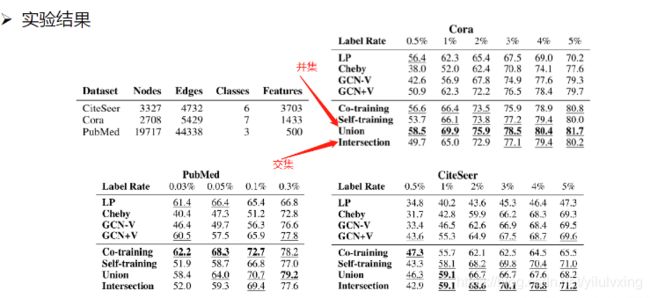
论文:Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning,讲述浅层的比较结果:
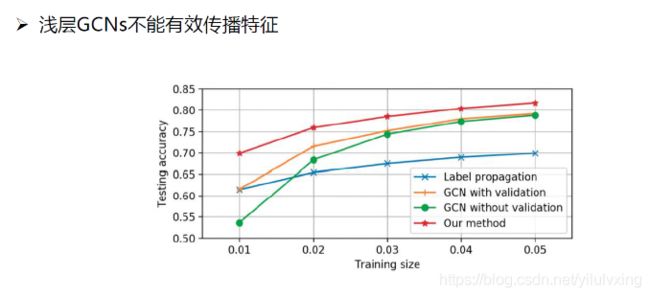

上面的两种方法都是在说,通过上面的方法(具体看上面)给没有标签的数据给一个标签,然后将它们加入到训练集中,来扩展训练集。同时指出这两种方法可同时使用,比如取它们的并集,也可取交集。
3:过平滑问题的若干缓解方案
前面我们说的图卷积会过平滑都是类似于 ![]() ,其中
,其中![]()
![]() ,X 为节点特征,W 为可学习的参数。那么是不是对于其他的图卷积也具有过平滑问题呢,答案是否定的,或者说至少现在还没发现。如GraphSAGE和GATs在实现的时候其实都有一定程度的缓解过平滑现象
,X 为节点特征,W 为可学习的参数。那么是不是对于其他的图卷积也具有过平滑问题呢,答案是否定的,或者说至少现在还没发现。如GraphSAGE和GATs在实现的时候其实都有一定程度的缓解过平滑现象


论文:《Semi-supervised Classification with Graph Convolutional Networks Representation Learning on Graphs with Jumping Knowledge Networks Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks》
深度拓展就是将底层特征与高层特征进行融合,比如残差连接、稠密连接等。看着上面公式来解释。
残差连接:比如第 层的输入特征是
层的输入特征是![]() ,经过一个图卷积之后,那么图卷积的结果就是
,经过一个图卷积之后,那么图卷积的结果就是![]() ,这个仅仅是图卷积的输出特征;然后对输出进行一个非线性激活之后再将第 层的输入特征作为一个残差单元,将它连接起来,那么第 层的输出就是
,这个仅仅是图卷积的输出特征;然后对输出进行一个非线性激活之后再将第 层的输入特征作为一个残差单元,将它连接起来,那么第 层的输出就是![]() ,这就是残差连接。
,这就是残差连接。
稠密连接:和上面残差连接一样,第 层的输入特征是![]() ,经过一个图卷积的结果就是
,经过一个图卷积的结果就是![]() ,然后对输出进行一个非线性激活;最后经过一个特征串联
,然后对输出进行一个非线性激活;最后经过一个特征串联  ,就得到了第 层的输出
,就得到了第 层的输出![]() ,这就是稠密连接。
,这就是稠密连接。
残差连接就是直接相加,而稠密连接就是串联。
还有一种特殊的深度拓展——强化自连接:就是说对普通的图卷积而言,在得到邻接矩阵![]()
![]() 之后,再给它加一个单位矩阵
之后,再给它加一个单位矩阵  ,使得邻接矩阵对角线上的元素被加强了。其实这个操作就是说在进行图卷积的时候更多的保留自身的特征而不被近邻节点特征进行干扰。
,使得邻接矩阵对角线上的元素被加强了。其实这个操作就是说在进行图卷积的时候更多的保留自身的特征而不被近邻节点特征进行干扰。

论文:《N-GCN: Multi-Scale Graph Convolution for Semi-Supervised Node Classification Residual or Gate? Towards Deeper Graph Neural Networks for Inductive Graph Representation Learning》
宽度拓展就是全局特征融合局部特征,具体做法是采用多阶近邻连接和序列化连接。
多阶近邻连接:就是说GCN是可以对多阶的邻居可以操作的。具体来说(看上述公式),GCN是一个普通的图卷积,输入为邻接矩阵![]() ,节点特征 ,可学习参数 θ 。多阶近邻连接到GCN里面就是调节
,节点特征 ,可学习参数 θ 。多阶近邻连接到GCN里面就是调节![]() 的形式,比如说
的形式,比如说![]() 就代表0阶的近邻关系,也就是单位矩阵 ,
就代表0阶的近邻关系,也就是单位矩阵 , ![]() 就是一阶近邻关系,直到n阶近邻,这样图卷积的感受野就扩大了。然后将这些不同卷积的结果进行一个 操作,也就是串联操作,最后加一个softmax,这就是多阶近邻连接,它在宽度上进行了拓展。
就是一阶近邻关系,直到n阶近邻,这样图卷积的感受野就扩大了。然后将这些不同卷积的结果进行一个 操作,也就是串联操作,最后加一个softmax,这就是多阶近邻连接,它在宽度上进行了拓展。
序列化连接:所谓序列化就是模型的第 层先用一个普通的GCN进行卷积,假设输出为![]()
![]() ,将这个输出
,将这个输出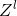 作为循环神经网络RNN的输入单元的一个隐藏层的状态,当前层的RNN的输入还是
作为循环神经网络RNN的输入单元的一个隐藏层的状态,当前层的RNN的输入还是![]() ,这样既保持了当前节点的信息,也融合了近邻节点的信息。
,这样既保持了当前节点的信息,也融合了近邻节点的信息。
下面来看看具体是怎么做的。
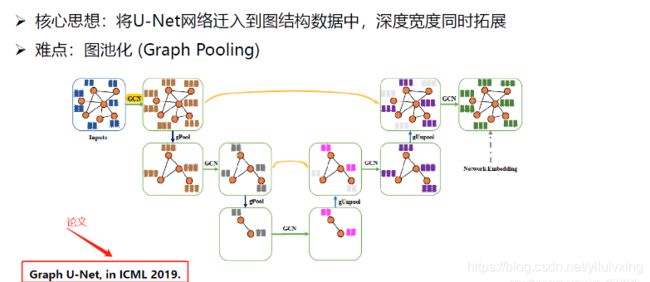

先假设第 层的输入是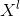 (如上图中是4个节点,每个节点有5个特征),然后给定投影向量
(如上图中是4个节点,每个节点有5个特征),然后给定投影向量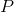 ,它是可学习的,长度和节点的特征相同。做法是:
,它是可学习的,长度和节点的特征相同。做法是:
第一步:将和做一个点乘,再除以的模![]() (这个就是归一化),得到
(这个就是归一化),得到  ;
;
第二步:选择前k大的数,将下标记下来;
第三步:再将选的前k大的数,经过sigmoid激活函数得到 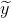 ;
;
第四步:同理,将 选择前k大的数,将下标记下来,得到 ;
;
第五步: 点乘操作, ⊙ ,意思就是说作为门控,它的数值越大,代表的输出特征表现得越强烈,然后就得到了![]() ;
;
第六步:将邻接矩阵A AA也进行同样的操作,得到![]() ;
;
可以看到节点个数变少了,这个就是最大池化的操作。
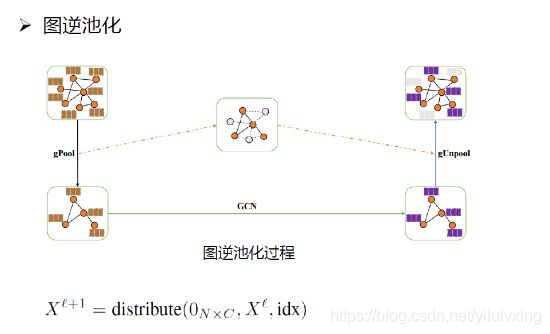
逆图池化相比图池化简便的多,具体来说计算过程如下(看上图解释):
对某一层的节点逆池化,由于在相同深度池化的时候,我们记录了被保留下来的节点的下标index,同样池化之前的图结构可以是被记录下来的。
首先、将图结构复制下来(上图最中间),令所有的节点的特征值是0,然后在逆池化的时候(上图右下角),将有特征的节点的特征填在我们刚刚复制下来的图结构中(上图最中间),所以现在有的节点有特征,而有的没有,把没有特征的节点的特征设为0就可以了,因为这些0特征值对应的节点在池化过程中被忽略了(就是说它们的特征不那么重要),图中的公式就是我们刚刚叙述的过程。
有了逆池化的结果之后还可以与原来没池化的结构进行跨层连接,所以前面说的那些特征值设为0的节点最终也会被填上。
有了图池化和图逆池化之后,我们就可以构造graph U-Net了。
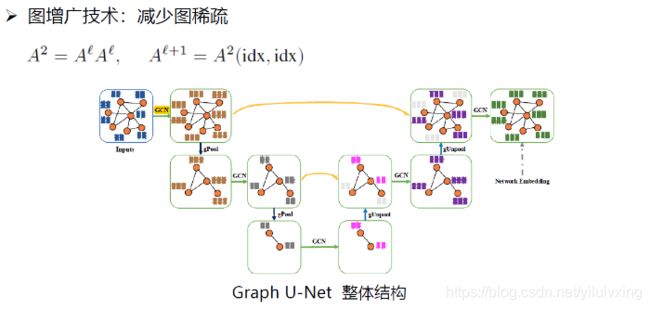
其中gPool为图池化,gUnpool为图逆池化,中间还增加了一些跨越连接,这些跨越连接就是将底层的特征和高层的特征进行一个融合,这个前面讲过,这样能提升模型的性能。
但是这其中有一个问题,就是我们在进行图池化的时候,只是选取了前k个大的数,这样当我们池化完后可能有的节点就没有边相连了,之后再进行图卷积就没啥作用了。所以这时候就采用了一种图增广技术来解决这个问题。所谓图增广技术就是说对第l ll层的邻接矩阵做一个二次幂,这个二次幂意思就是说节点不仅和一阶近邻相连,而且对二阶近邻再添加一条边,这样邻接矩阵就变得稠密了,然后从稠密的邻接矩阵进行下采样就会减少图稀疏的情况。
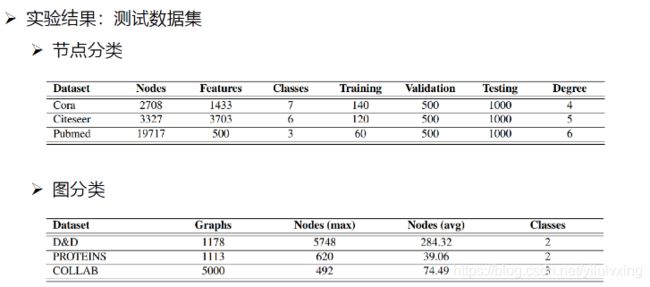
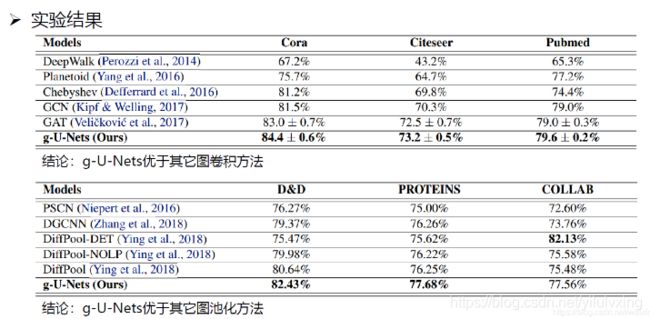

以上是graph U-Net使用深度宽度同时拓展来缓解过平滑问题,下面我们再看看其他的方法。
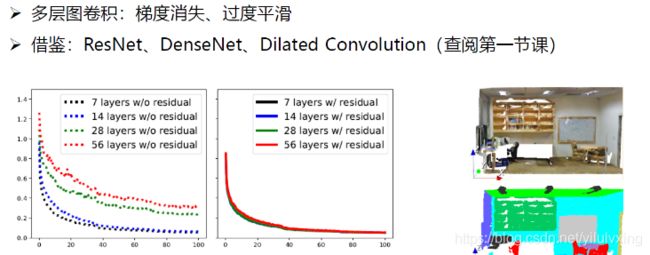
论文:《DeepGCNs: Can GCNs Go as Deep as CNNs?》ICCV 2019
上面是这篇论文的实验效果,接下来看看具体怎么做的。
需要说明的是,即使不知道三维点云分割,也能理解这个,因为下面我们要分析的是在图卷积层是如何缓解过平滑的。

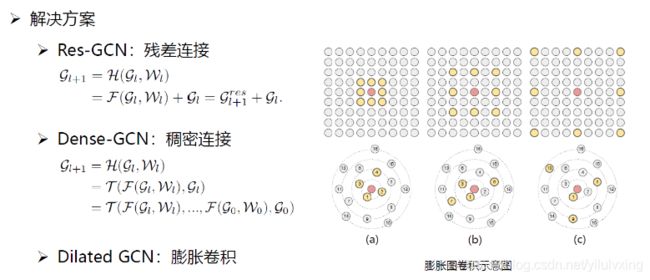
对上面的公式说明一下。
(1)Res-GCN:残差连接
第 层的输入,也就是第 层的输出
层的输入,也就是第 层的输出![]() ,是由两部分构成的,第一部分
,是由两部分构成的,第一部分![]() 是GCN的输出特征,第二部分
是GCN的输出特征,第二部分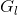 l就是输入特征本身。
l就是输入特征本身。
(2)Dense_GCN:稠密连接
第层的输入,也就是第 层的输出![]() ,进行拆分成
,进行拆分成![]() 和的串联,然后
和的串联,然后![]() 可以继续拆分,直到
可以继续拆分,直到![]() ,也就是最原始的输入特征本身。所谓稠密连接,就是第层的输出是由第0 层到第 -1层的输出进行串联得到的
,也就是最原始的输入特征本身。所谓稠密连接,就是第层的输出是由第0 层到第 -1层的输出进行串联得到的
(3)Dilated GCN:膨胀卷积
上图右边的示意图。
我们以图a看看,现在有一个中心节点和16个相邻的节点,按距离远近给出编号,如果卷积核的大小为4,也就是说有4个可学习的参数,这时候如果卷积核没有膨胀(看图b图c就知道了,卷积核变大了,但是还是那么多的卷积核参数),那么就选取距离中心节点最近的4个节点1、2、3、4作为邻近节点,然后用大小为4的卷积核对这四个节点进行卷积,这时候的膨胀率为1。
看图b,现在膨胀率为2,这时候对近邻节点采样的时候,就不能按1,2,3,4来采样了,那怎么做呢?是这样的:由于膨胀率为2,所以在采样的时候,先取1号节点,然后取3号,再5,再7,所以最后就选取1、3、5、7号这四个节点作为邻近节点,也就是感受野。
同理,看图c,现在膨胀率为4,所以采样时选1、5、9、13这四个节点作为近邻节点。
有了这三种GCN,就可以对模型做一个不一样的构造。


什么是动态K近邻?就是说在每进行一次GCN之后,都再对节点之间的距离重新做一次度量,确实能提高准确率,但是计算的代价会随之提高。
近邻大小就是让卷积核的大小。
网络深度不用说,就是增加层数。
网络宽度就是增加感受野,除了加大卷积核可以增加感受野之外,膨胀卷积核也可以增加感受野的大小。
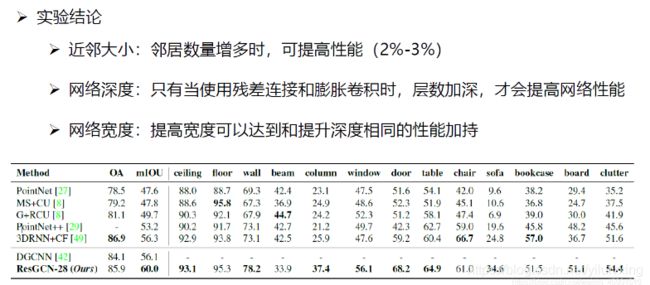
4:总结

下一篇:
图卷积神经网络5:图卷积的应用
知乎主页https://www.zhihu.com/people/shuang-shou-cha-dai-53https://www.zhihu.com/people/shuang-shou-cha-dai-53