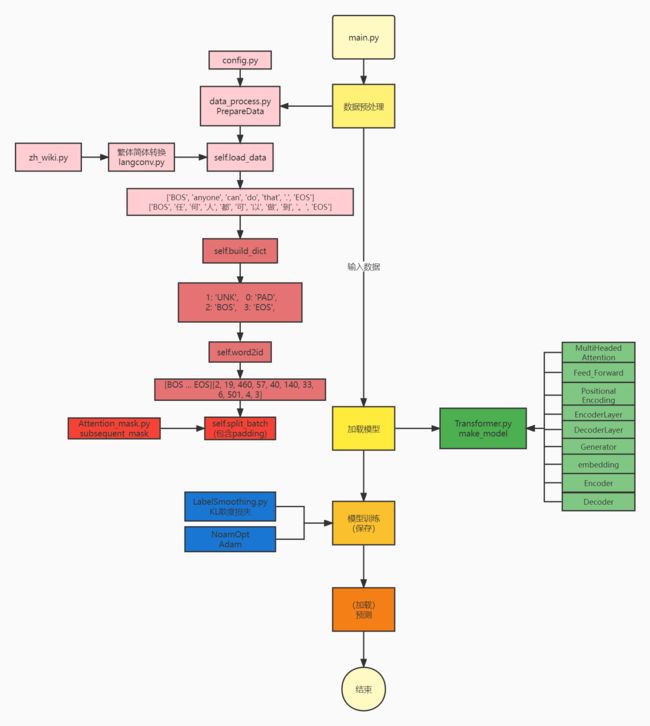
Transformer:网络架构
Transformer Attention is all you need 代码架构
标签平滑(Label smoothing)
标签平滑(Label smoothing),像L1、L2和dropout一样,是机器学习领域的一种正则化方法,通常用于分类问题,目的是防止模型在训练时过于自信地预测标签,改善泛化能力差的问题。
传统one-hot编码标签的网络学习过程中,鼓励模型预测为目标类别的概率趋近1,非目标类别的概率趋近0,即最终预测的logits向量(logits向量经过softmax后输出的就是预测的所有类别的概率分布)中目标类别 z i z_i zi的值会趋于无穷大,使得模型向预测正确与错误标签的logit差值无限增大的方向学习,而过大的logit差值会使模型缺乏适应性,对它的预测过于自信。在训练数据不足以覆盖所有情况下,这就会导致网络过拟合,泛化能力差,而且实际上有些标注数据不一定准确,这时候使用交叉熵损失函数作为目标函数也不一定是最优的了。
label smoothing结合了均匀分布,用更新的标签向量 y i y_i yi来替换传统的ont-hot编码的标签向量 y h o t y_{hot} yhot:
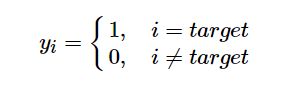
其中K为多分类的类别总个数,α是一个较小的超参数(一般取0.1),即
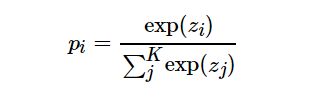
这样,标签平滑后的分布就相当于往真实分布中加入了噪声,避免模型对于正确标签过于自信,使得预测正负样本的输出值差别不那么大,从而避免过拟合,提高模型的泛化能力。
代码
class LabelSmoothing(nn.Module):
"""
标签平滑
"""
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(reduction='sum')
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
# torch.Size([2688, 2537])
true_dist = x.data.clone()
print("true_dist")
print(true_dist)
print(true_dist.shape)
# a / K
true_dist.fill_(self.smoothing / (self.size - 2))
# 1 - a
# 将true_dist中target对应的索引用置信度self.confidence替换
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
# 返回一个二维张量,其中每一行都是一个非零值的索引
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
# index_fill(dim, index, val)
# 参数分别对应了 在第几维填充、 以什么为索引去填充、 以什么为值进行填充
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, Variable(true_dist, requires_grad=False))
Adam优化器
- 实现简单,计算高效,对内存需求少
- 参数的更新不受梯度的伸缩变换影响
- 超参数具有很好的解释性,且通常无需调整或仅需很少的微调
- 更新的步长能够被限制在大致的范围内(初始学习率)
- 能自然地实现步长退火过程(自动调整学习率)
- 很适合应用于大规模的数据及参数的场景
- 适用于不稳定目标函数
- 适用于梯度稀疏或梯度存在很大噪声的问题
https://zhuanlan.zhihu.com/p/32698042
Transformer(
(encoder): Encoder(
(layers): ModuleList(
(0): EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=256, out_features=1024, bias=True)
(w_2): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1): EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=256, out_features=1024, bias=True)
(w_2): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(2): EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=256, out_features=1024, bias=True)
(w_2): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(3): EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=256, out_features=1024, bias=True)
(w_2): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(4): EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=256, out_features=1024, bias=True)
(w_2): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(5): EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=256, out_features=1024, bias=True)
(w_2): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(norm): LayerNorm()
)
(decoder): Decoder(
(layers): ModuleList(
(0): DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=256, out_features=1024, bias=True)
(w_2): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1): DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=256, out_features=1024, bias=True)
(w_2): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(2): DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=256, out_features=1024, bias=True)
(w_2): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(3): DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=256, out_features=1024, bias=True)
(w_2): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(4): DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=256, out_features=1024, bias=True)
(w_2): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(5): DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=256, out_features=1024, bias=True)
(w_2): Linear(in_features=1024, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(norm): LayerNorm()
)
(src_embed): Sequential(
(0): Embeddings(
(lut): Embedding(5493, 256)
)
(1): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(tgt_embed): Sequential(
(0): Embeddings(
(lut): Embedding(2537, 256)
)
(1): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(generator): Generator(
(proj): Linear(in_features=256, out_features=2537, bias=True)
)
)