活体检测 Face Anti-Spoofing Using TransformersWith Relation-Aware Mechanism 学习笔记
论文链接:Face Anti-Spoofing Using Transformers With Relation-Aware Mechanism | IEEE Journals & Magazine | IEEE Xplore
同一图像不同 patch 之间的信息为区分真假人脸提供了重要信息,如下图所示,与真实人脸相比,从假体人脸提取的 patch 之间的相关性很强,不论这两个 patch 是否处在相邻位置。有两个原因导致这样的结果:(1)打印和重放攻击的假体人脸通常仅携带二维平面信息。相比之下,真实人脸具有丰富的 3D 结构信息;(2)大部分假体人脸的材质具有相同的材料属性,例如纸张和玻璃屏幕。而真实人脸呈则包含更细微的细粒度细节。考虑到以上两个因素,可以利用不同局部块之间的差异来判断真假人脸。

文章创新点
(1) 基于 learning-based 的方法,提出了跨层关系感知注意(cross-layer relation-aware attentions,CRA)来权衡来自不同层的局部 patch
(2)为了减少浅层的纹理信息丢失并充分利用深层的语义信息,深入探索了最佳跨层特征融合(hierarchical feature fusion,HFF)方法
(3)模型采用二元和深度监督联合优化
方法论
TransFAS 的整体网络结构如下图所示。算法首先将人脸图像划分成不同的块,并通过线性投影提取特征。接着,将 patch embedding、分类 embedding 和位置 embedding 融合为 transformers 层的输入。最后,使用解码器生成深度图,同时使用深度损失(![]() +
+ ![]() )和二元损失(
)和二元损失(![]() )来监督模型。
)来监督模型。

1)Transformers for FAS
为了研究真实人脸和假体人脸中 patch 之间的关系,作者使用 transformers 来进行特征提取。具体来说,首先将图片划分成 N × N 个非重叠图像块。经过一些线性变换后,将这些 patch 嵌入到 1D 的 embedding 空间 ![]() 中,并将它们合并为
中,并将它们合并为 ![]() ,
, 为 patch 的数量,数值上等于
为 patch 的数量,数值上等于 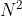 ,
, 为 embedding 空间的维度。接着随机初始化分类 embedding
为 embedding 空间的维度。接着随机初始化分类 embedding ![]() 和位置 embedding
和位置 embedding ![]() 并将它们与
并将它们与 ![]() 绑定在一起作为可学习的 embedding。再把上述特征 embedding 输入到编码器中,公式如下:
绑定在一起作为可学习的 embedding。再把上述特征 embedding 输入到编码器中,公式如下:

编码器层由多头自注意力 (multi-head selfattention,MSA) 和多层感知机 (multi-layer perceptron,MLP) 组成。 各层编码器逐层计算 patch 和分类 embedding 之间的关系。 因此,相邻层的特征embedding 可以表示为:

其中,![]() 是第 l 层编码器的输入,
是第 l 层编码器的输入,![]() 是中间变量。
是中间变量。
2)CRA
区分真假人脸的关键线索存在于不同的 patch 中。捕获不同的局部 patch 之间的关系有助于模型对真假人脸的判别。然而,这些局部 patch 可能来自不同尺寸的特征图。因此,我们需要去推断来自不同层的 patch 之间的关系。基于这层考虑,作者提出了 CRA,它使模型在学习同层 patch 之间相关性的同时,还能学习不同层的 patch 之间的相关性。
假设每层的 patch 数为 。为了更好地探索不同层的 patch 之间的关系,作者使用了 GCN 来提取不同 patch 之间的信息 (具体操作如整体网络结构中的 CRA 部分所示,将两个 patch 拼接后再进行特征提取)。定义一个图 ![]() ,它包含 2L 个节点
,它包含 2L 个节点 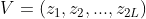 以及对应的边缘
以及对应的边缘  ,作用是推理不同 patch 之间的关系。邻接矩阵
,作用是推理不同 patch 之间的关系。邻接矩阵  用于表示局部 patch 之间的关系。公式如下:
用于表示局部 patch 之间的关系。公式如下:

其中,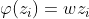 ,
,![]() 。具体来说,
。具体来说, 和
和 ![]() 为
为 ![]() 结构。
结构。
为了结合空间顺序信息,将第 i 个 patch 和所有 patch 之间的关系堆叠在一起,获得:
![]()
为了学习重要性分数 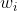 (对应 patch
(对应 patch  ),作者首先对局部特征 和全局关系信息
),作者首先对局部特征 和全局关系信息  进行拼接,随后利用一个 embedding 函数来进行推理,公式如下:
进行拼接,随后利用一个 embedding 函数来进行推理,公式如下:
![]()
其中, 和
和 ![]() 表示
表示 ![]() ,分别对 和 进行映射。
,分别对 和 进行映射。 为卷积层,用于学习重要性分数 。
为卷积层,用于学习重要性分数 。
对于来自不同层的两个 patch,可以得到重要性分数列表:
![]()
随后利用 sigmoid 激活函数来标准化重要性分数:

最后,得到加权后的 patch embedding,公式如下:
![]()
3)HFF
与 CNN 不同,Transformer 编码器层采用自注意力来分层计算每个 patch 之间的相关性。在低层特征图中,patch 与周围区域的相关性更强,有利于提取纹理细节。在深层特征图中,patch 可以与整个区域相关联,有利于提取语义信息。但随着网络深度的增加,低级特征的信息也在不断丢失,而许多重要的区分信息以低级特征表示。因此,为了减少低层特征的丢失并充分利用不同层特征之间的互补性,作者提出了 HFF 融合来自不同层的特征,如下图所示。

图中从左到右为 HFF 不同的特征融合方案,分别为 bottom-up fusion, bidirectional fusion 和 top-down fusion。
作者通过消融实验证明方案 (c) 的特征融合效果最优,这表明从高到低进行特征融合更适合 FAS。 具体来说,更深的信息引导下层关注具有语义相关性的区域,而低层相应地提取更重要的纹理细节。
4)损失函数
为了充分利用全局和局部信息, TransFAS 网络中同时采用了二元和深度监督。 整体损失 ![]() 定义如下:
定义如下:
![]()
其中,![]() 表示二元交叉熵损失,
表示二元交叉熵损失,![]() 由 MSE 和 CDL 组成,用于度量真实值 (
由 MSE 和 CDL 组成,用于度量真实值 (![]() ) 与预测值 (
) 与预测值 (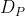 ) 之间的差异,深度监督真实值由 PRNet 生成,PRNet 算法的环境配置在我之前的一篇博客中有提到,感兴趣的可以去看看:
) 之间的差异,深度监督真实值由 PRNet 生成,PRNet 算法的环境配置在我之前的一篇博客中有提到,感兴趣的可以去看看:
PRNet 论文学习、Windows系统代码环境配置及demo展示_Cassiel_cx的博客-CSDN博客
回归正题,上式中的  是一个比例系数,用于平衡两个损失函数;
是一个比例系数,用于平衡两个损失函数; 表示用于调整绝对值的尺度系数。
表示用于调整绝对值的尺度系数。
5)训练及测试细节
训练设置
batch size 为256;优化器为 Adam;lr 和 weight decay 均为 5e-5,lr 每隔 50 epoches 下降一半;epoch 为 150; 为 0.4; 为 1;patch 的大小为 16×16;特征 embedding 的通道数为 192。
测试设置
在测试期间,区分真假人脸的分数定义如下:
![]()
其中, 的值与训练时的一致;![]() 表示二分类真人概率值;
表示二分类真人概率值;![]() 表示 中所有像素点的均值, 为 28×28 的特征图。
表示 中所有像素点的均值, 为 28×28 的特征图。
实验结果
在 OULU-NPU 测试集上的实验结果如下:


在 SIW 测试集上的实验结果如下:

在 OULU-NPU、CASIA-MFSD、REPLAY-ATTACK 和 MSU-MFSD 的跨数据集测试结果如下:

在已知和未知场景中的测试结果如下:

来自 OULUNPU 数据集的一些示例的图像注意力可视化如下图所示,

其中,(a) 原图;(b) w/o CRA;(c) w/o HFF;(d) TransFAS
结论
TransFAS 可以跨不同层学习全面的关系感知局部表示,CRA 可以提供 patch 之间的信息以提高性能,HFF 探索了融合跨层特征的最佳方法。大量实验也证明了 TransFAS 模型在已知和未知场景中的鲁棒性。