无监督对比学习之左脚踩右脚的BYOL《Bootstrap your own latent A new approach to self-supervised Learning》
背景
在表示学习中,我们现在采用的框架本质是通过一个view的表示去预测相同图像其他view,能预测对说明抓住了图像的本质特征。但在做这样的预测时会有坍缩(collapse)的风险,意思是全都变成一个表示,那也可以做到预测自己。对比学习为了解决这个问题,将表示预测问题转换为了正负例判别问题,这样就迫使模型的输出是多样的,避免坍缩。
灵感
如何不用负例,也能学到好的表示呢?如果共用encoder,用MSE作为损失,缩小相同图像不同view的距离,肯定会坍缩。
那就把其中一个encoder变成随机初始化且固定下来(stop gradient)!!!
一个左脚踩右脚也能上天的实验诞生了:
- 首先有一个网络参数随机初始化且固定的target network,target network的top1准确率只有1.4%,
- target network输出feature作为另一个叫online network的训练目标,等这个online network训练好之后,online network的top1准确率可以达到18.8%。
- 假如将target network替换为效果更好的网络参数(比如此时的online network),然后再迭代一次,也就是再训练一轮online network,去学习新的target network输出的feature,那效果应该是不断上升的,类似左右脚踩楼梯不断上升一样。
为什么呢?
下面是简单的猜想与解释
首先解释有负例的无监督对比学习为啥work
该方法能够work的内在原理是实际应当归属于同一类的数据具有着潜在的相似特征分布。
具体解释https://blog.csdn.net/weixin_42764932/article/details/112927959

上图近似的模拟contrastive learning的训练过程,红色代表同一个类别,蓝色代表其他类别,圆圈和方块分别是不同的数据扩展方法。
整个网络训练要做的就是拉大两个圆之间的距离,同时减少左面圆的半径。
但是同一个类别的数据具有着潜在相近分布,所以在不断地训练过程中,负样本中的正样本会渐渐的向分隔线靠近,其他真正的负样本会继续远离,最终的结果便是相同类别的数据聚集在一起。
如何评价Deepmind自监督新作BYOL? - 江山如画的回答 - 知乎
https://www.zhihu.com/question/402452508/answer/1352959115
回到BYOL
BYOL没有追求打开样本之间的距离,而是随机将样本丢散开,然后通过另外一个网络将该样本的另外一种分布去匹配之前的样本特征分布。
这个操作能够提升特征网络的表达能力,这一点是很重要的一个现象,没有该现象,BYOL是无法实现的。画图解释如下
可以说是,通过对数据集的augmentation,并且迭代的去学习样本通过网络在特征空间的分布。该方法能够work的内在原理是,网络并非严格的学习样本自身的特性,而是学习了该样本所在分布的特性。

上图便是BYOL的模拟过程,颜色代表类别,形状代表不同aug
(分别是初始化的圆圈;圆圈不动,方块去接近圆圈;方块不动,圆圈去接近方块。。。)
初始时刻,一种augmentation对应的分布是随机的,训练另外一种augmentation的网络去拟合该随机分布,除了loss约束上使得同一种颜色的方块接近圆圈之外,由于内在特征的相似性还会使得同一颜色的方块的分布相对接近,
如此往复,同一类别的分布会渐渐的接近,因为网络并非严格的学习样本自身的特性,而是学习了该样本所在分布的特性,这种方法本质上来讲是一种特征的聚类方法,contrastive learning也是利用了特征聚类的原理。
这里是引用
如何评价Deepmind自监督新作BYOL? - 江山如画的回答 - 知乎
https://www.zhihu.com/question/402452508/answer/1352959115
BYOL流程
BYOL特点在于没有负样本对,这是一个非常新奇的想法,通过增加prediction和stop-gradient避免训练退化。
整体上分为online network和target network两部分,如图所示,通过约束这2个网络输出特征的均方误差(MSE)来训练online network,而target network的参数更新取决于当前更新后的online network和当前的target network参数,这也就是论文中提到的slow-moving average做法,灵感来源于强化学习。

伪代码如下

写的很清晰,不再赘述
BYOL相比SimCLR系列的一个有趣的点在于前者对batch size和数据增强更加鲁棒,论文中也针对这2个方面做了对比实验,如Figure3所示。大batch size对于训练机器要求较高,在SimCLR系列算法中主要起到提供足够的负样本对的作用,而BYOL中没有用到负样本对,因此更加鲁棒。数据增强也是同理,对对比学习的影响比较大,因此这方面BYOL还是很有优势的。
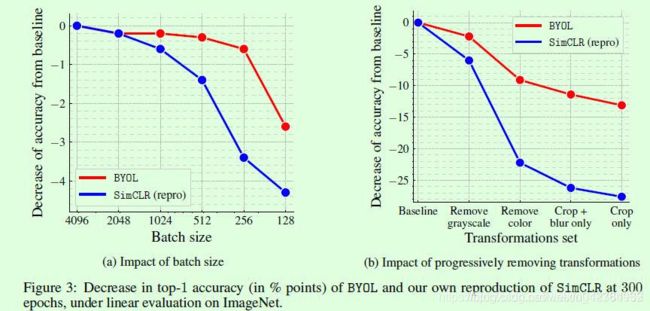
1.为什么相对contrastive learning而言,对batch size相对不敏感呢?
因为不存在负样本中的正样本,也不必刻意去拉大和负样本之间的距离。
2.为什么对augmentation的要求也降低了呢?
因为不是严格需要缩小两个正样本的augmentation之间的距离,而是统计上缩小所有的augmentation数据对之间的距离就好,简单理解就是数量多性能提升对单个要求不高,那么自然对augmentation要求也降低了。
3.target network的参数更新
target network的参数更新,采用的是Algorithm 1第11行的更新方式,即动量更新。
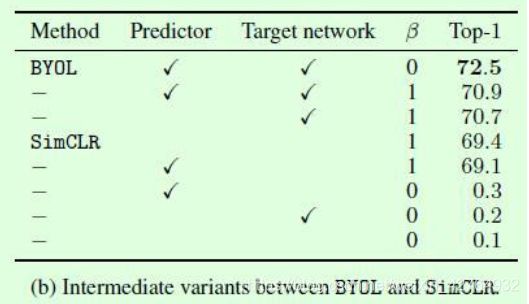
那么这就涉及到计算权重的选择问题,这里作者做了对比实验如Table5(a)所示,
T选择1的时候表示target network的参数一直都不变,就是前面motivation提到的结果18.8;
T选择0的时候表示target network的参数完全由online network的参数替换,相当于每个step都要更新一下网络参数,可以看到这个时候效果非常差(其实就是训练崩塌),此时整个网络的训练波动比较大。
因此中间3种T值的选择就是既不让更新速度过快,也不让更新速度过慢而设计的,整体上在每次更新时原target network的参数占比还是更大的。

T的更新公式,其中k表示step,K是max step。
![]()
4.关于predictor、target network和是否有负样本对的充分对比实验
在β=0时表示没有负样本对,可以看到此时的SimCLR不管是增加predictor还是target network,效果都非常差。
注意看(b)中第一行和倒数第二行的对比,差别只在于有没有predictor,此时效果差异是巨大的,这也就是论文中提到的predictor结构是避免训练崩塌的重要元素之一,个人认为predictor的存在对于BYOL这种更新target network参数的方式而言提供了更多的学习空间,虽然结构很简单,但是不能没有。
在β=1时,可以看到是否有predictor对于BYOL和SimCLR都影响不大,可以理解为此时有负样本对保证了训练过程不会崩塌。
以下内容来自知乎,作者:田永龙
如何评价Deepmind自监督新作BYOL? - 田永龙的回答 - 知乎
https://www.zhihu.com/question/402452508/answer/1294166177
假定给了 ( x , y ) (x,y) (x,y)是一对positive pair,还有很多个负样本 y i − y^{-}_i yi−
contrastive loss,具体形式如下

这个loss可以进一步分解成两个部分

可以把contrastive loss分解成两个部分,
第一部分叫做alignment,就是希望positive pair的feature接近,
第二部分叫做uniformity,就是希望所有点的feature尽量均匀的分部在unit sphere上面.
这两部分理论上是都需要的,假如只有alignment,没有uniformity,那就很容易都坍缩到0,就是退化解。
BYOL就是去掉uniformity,只保留了alignment.猜想其实BYOL在悄悄地做dispersion,默默地在分开不同样本的特征.
从文章里面可以读出两点:
(1) 对比表格5a的第三条和最后一条可以看出来EMA很重要.这点猜测,EMA可能在帮助悄悄scatter feature,初始化的随机性本身就把feature scatter开来了,它更新慢或许能保持这种分散开的特性,使得online network的不同图片在regress的时候target是不同的,进而帮助阻止模型塌陷.
(2) 对比表格5b的第一条和倒数第二条,可以看出来多的这个predictor非常重要,虽然它只是1或2层全连接.我觉得它给了online network很好的灵活性,就是online network的feature出来后不用完完全全去match那个EMA模型,只需要再经过一个predictor去match就好了.然后这个predictor的weight是不会update到EMA的,相当于一个允许online和EMA feature不同的缓冲地带.不过我第一次读到时候怀疑是个bug,不知道到底怎么回事.
文中里面我没直接读到,但是我猜测的点(可能会错):
(3) 我猜测一部分是因为骨干网络有BN,所以在一个大batch里面,BN会把不同点的特征scatter开来,就等于默默地在做dispersion.看BYOL的图3可以发现Batch Size还是有影响的,batch size越大scatter得越开,效果越好,反之越差(当然似乎比SimCLR好一点).BN应该是对online network以及EMA都有影响的.
(4) 最后这个regress的feature是L2-normalized的,可能这一步可以防止MSE把feature的scale都拉倒接近0.L2-normalized后这个MSE loss其实就变成把特征的方向对上,而scale就不在乎了.
另外关于下一步研究方向的猜测:(1)盲猜以后的研究可以考虑怎么显式地scatter能比BN更好,比如特别设计一种normalization,然后或许就连EMA模型也可以拿掉了.(2)如果对比它的表18,可以看出来显示的uniformity term还是有用的,可以从72.5提高到72.7,所以还是调得更好的SimCLR是SoTA哇。以后可以考虑怎么使得这个uniformity term更有效.
如何评价Deepmind自监督新作BYOL?
无监督对比学习之MOCO 《Momentum Contrast for Unsupervised Visual Representation Learning》
无监督对比学习之力大砖飞的SimCLR《A Simple Framework for Contrastive Learning of Visual Representations》