SLAM学习笔记《Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Per》
《Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age》
一、引言
SLAM包含同时估计搭载传感器机器人的状态估计以及构建传感器感知的环境模型(模型)。在简单的例子中,机器人的状态可以通过它的位姿来描述(位置与方向),尽管状态还包含其它量,如机器人速度、传感器偏差(sensor biases)和校准参数。另一方面,地图作为兴趣点的表示(如路标位置、障碍物),描述的是机器人所在环境。
环境地图的使用需要是双重的。首先,地图通常用于支撑其他任务;比如,地图可以用来路径规划,或者给操作员提供直观的可视化。第二,地图可以限制机器人状态估计误差。假如没有地图,航位的推算会随时间推移而迅速漂移;另一方面,利用地图,如一系列明显的路标,机器人可以通过再一次访问已知区域(也称为回环检测)来重置定位误差。因此,在没有先验地图或需要建图的场景中得到应用。
迄今主要的SLAM综述总结在了下表
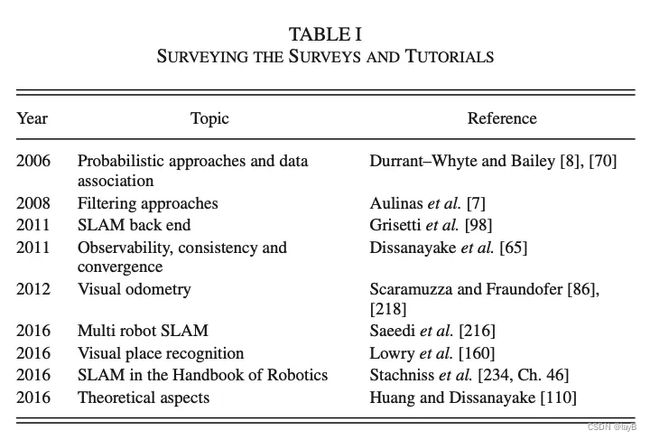
本文概述了SLAM当前发展状态,并提供部分社区SLAM研究的开放问题及未来方向的看法。我们主要关注点是度量和语义SLAM,我们建议读者参考Lowry等人最近的研究,主要提供了基于视觉的场景识别和拓扑SLAM的全面回顾。
回环检测事件告知机器人这条走廊不断与自身相交。回环检测的优势变得明了:通过回环检测,机器人知道环境的真实拓扑,并且能够找到两点间的最短路径(地图中点B和C)。然而,如果SLAM的优点之一是得到环境的真实拓扑结构,为何不丢掉度量信息,只进行简单的场景识别呢?答案很简单:度量信息可以使得场景识别简单并鲁棒,度量重构告知机器人回环检测的成功概率并允许丢弃虚假的回环检测。因此,虽然理论上SLAM可能是多余的(一个oracle场景识别模块足够用来拓扑建图),但SLAM提供一种天然防御,可以防止错误的对数据关联和感知混淆,如看似一样却不在同一地点的场景,会欺骗场景识别模块。在这种意义下,SLAM地图可以提供预测和验证未来测量的方法:我们坚信这种机制对稳健操作是至关重要的。
SLAM的成熟度评估:
- 机器人:运动类型(如:动态,最大速度),可用传感器(如,分辨率,采样率),可用计算资源。
- 环境:平面或3维,存在自然或人造路标,运动元素数量,对称的数量,感知混淆的风险。特别注意,这些方面其实依赖传感器与环境匹配对:如,2个房间可能在激光扫描器下是完全一样的,而相机却很容易从外观线索中辨别它们。
- 性能要求:期望机器人状态估计的准确率,环境的表示形式(如基于路标的,还是稠密的),成功率(检测的准确率达到标准),估计延迟,最大工作时间,建图的最大区域。
在本文中,我们认为我们正在进入 SLAM 的第三个时代,即鲁棒感知时代,其特征在于以下关键要求:
- 鲁棒的性能:SLAM系统在广泛的环境中长时间以低故障率运行;该系统包括故障安全机制并具有自调整能力,因为它可以根据场景调整系统参数的选择。
- 高级理解:SLAM系统超越了基本的几何重建,以获得对环境的高级理解(例如,高级几何、语义、物理、可供性[affordances])。
- 资源感知:SLAM系统针对可用的传感和计算资源进行定制,并提供了根据可用的资源调整计算负载的方法。
- 任务驱动感知:SLAM系统能够提取相关的感知信息并过滤掉无关的传感器数据,为了支持任务,机器人必须执行;此外,SLAM系统产生自适应地图表示,其复杂性可能因当前的任务而异。
2 现代SLAM系统剖析
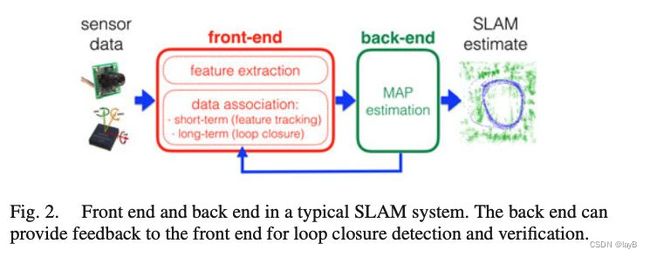
SLAM系统的架构包括两个主要组件:前端和后端。前端将传感器数据抽象为可用于估计的模型,而后端则对前端生成的抽象数据进行推理。该架构总结在图 2中。我们从后端开始研究这两个组件。
A、最大后验估计与SLAM后端
SLAM 的当前的标准公式起源于Lu和Milios的开创性论文,随后是 Gutmann 和 Konolige 的工作。从那时起,很多方法都在致力于改进这一优化问题的效率和鲁棒性。所有这些方法都将SLAM问题归结于最大后验估计问题,通常用因子图来解析变量之间的依赖关系。
假设我们要估计一个未知变量X,正如前面提到的,在SLAM中变量代表机器人的轨迹(即位姿的离散集合)和环境中路标的位置。



(最大后验概率:看不懂)
这是由贝叶斯公式得到的。在上式中,为给定变量测量值得似然函数,为变量的先验概率分布。当不知道先验服从何种分布时,可以假设为一个常量(均一分布),可以从优化中直接去掉,这样最大后验估计就退化成最大似然估计。值得一提的是,不同于卡尔曼滤波,最大后验估计不需要明确区分运动和观测模型,两个模型都被看做因子,不做任何区分直接加入到估计过程。更进一步的,值得一提的是卡尔曼滤波和最大后验估计在线性高斯情况下估计结果是一致的,但在通常情况下线性高斯假设是不成立的。
假设测量值是相互独立的(即噪声不相关的),上式可以分解为:
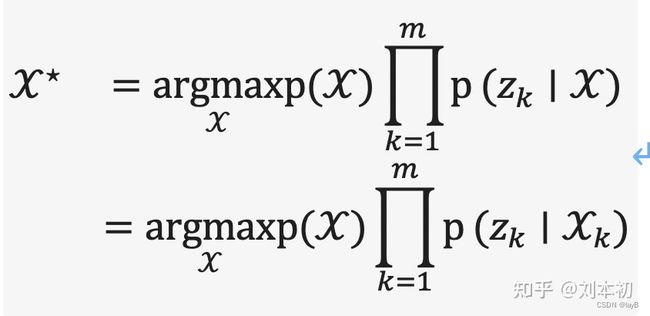
其中,在公式后边,我们注意到只依赖变量的子集。
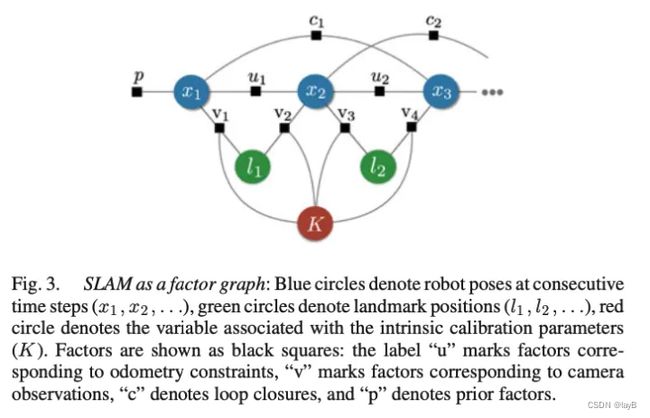
上式可以用因子图推断来理解。变量对应因子图的节点。似然值与先验称为因子,它们对节点子集的概率约束进行编码。一个概率图是一个图模型,对第k个因子(即测量值)和对应的变量之间的依赖性进行编码。因子图解释的第一个优点在于它可以对问题进行一个最直接的可视化表示。下图展示了一个简单SLAM问题的因子图表示形式。该图显示了变量,即机器人位姿、地标位置和相机校准参数,以及这些变量之间施加约束的因素。第二个优点是通用性:因子图可以对具有异构变量和因子以及任意互连的复杂推理问题进行建模。此外,因子图的连通性反过来会影响所产生的 SLAM 问题的稀疏性,如下所述。
为了以更明确的形式写出式(2)的具体形式,假设测量噪声是具有信息矩阵(协方差矩阵的逆)的零均值高斯噪声。接下来,式(2)中的测量似然变为
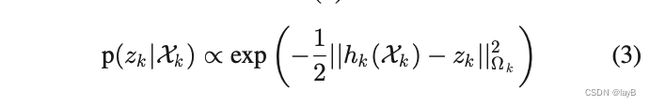
这里我们定义。同样地,我们假设先验分布可以表示为。因为最大化后验等价与最小化负对数后验,因此最大化后验式(2)可以转化为下式:
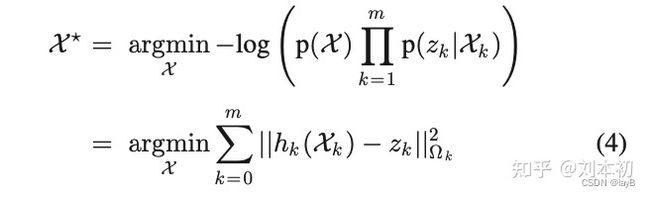
上式是一个非线性最小二乘问题,这是在机器人领域中经常遇到的有意思的问题,为一个非线性函数。注意上式是在正态分布噪声的假设下得到的。其他噪声分布会导致不同的代价函数。比如假设噪声分布为拉布拉斯分布时,上式中的l2范数将会变成l1范数。为了更好的抑制奇异值,我们通常将平方l2范数用一些更鲁棒的损失函数代替(比如Huber 或 Tukey 损失)。
计算机视觉专家可能会注意到问题(4)与运动中恢复结构(SFM)中的捆集调整(BA)之间的相似之处。问题(4)和BA确实都是从最大后验公式中推导出来的。但是,有两点特殊特征使得SLAM很特殊。第一,式(4)中的因子不限于像BA中那样对射影几何建模,而是包括各种传感器模型,例如惯性传感器、车轮编码器、GPS等等。例如,在激光建图中,这些因子通常会限制相对位姿对应于不同视角,而在视觉SLAM的直接法中,这些因子会惩罚场景同一部分在不同视图中像素强度的差异。与BA相关的第二个区别是,在 SLAM 场景中,问题(4)通常需要增量解决:随着机器人的移动,每个时间步都会提供新的测量值。
最小化问题(4)通常通过连续线性化来解决,例如Gauss-Newton或Levenberg-Marquardt方法(基于凸松弛和拉格朗日对偶的替代方法会面将介绍)。连续线性化方法进行迭代处理,首先给定一个初始值,将代价函数在处进行二次近似,可以通过求解线性方程组以封闭形式进行优化。这些方法可以无缝推广到属于平滑流形(例如旋转)的变量,这些变量在机器人技术中很重要。
现代SLAM求解器背后的关键核心是,出现在正规方程中的矩阵是稀疏的,其稀疏结构由底层因子图的拓扑结构决定。一些快速线性求解器将会被采用。更重要的是,可以设计出增量(在线)求解器,可以当观测值到来时实时更新变量的估计值。当前的SLAM库(如GTSAM、Ceres、iSAM、SLAM++)可以在秒级处理万级别变量问题。实操指南教程[62]、[98]很好地介绍了两个最流行的SLAM 库;每个库还包含一组展示真实SLAM 问题的示例。
到目前为止描述的SLAM方法通常被称为最大后验估计、因子图优化、图SLAM、完全平滑或平滑和映射(SAM)。该框架的一个流行变体是位姿图优化,其中要估计的变量是沿机器人轨迹采样的位姿,每个因子对一对位姿施加约束。
最大后验估计已被证明比基于非线性滤波的SLAM的原始方法更准确和更有效。我们建议读者参阅文献[8]、[70]以了解有关过滤方法的概述,并参阅 [236] 以了解过滤和平滑之间的比较。我们注意到一些基于EKF的SLAM系统也被证明可以达到最先进的性能。基于EKF的SLAM系统的优秀代表包括Mourikis和Roumeliotis[175]的多状态约束卡尔曼滤波器,以及 Kottas 等人的VIN系统。 [139]和Hesch等人。毫不奇怪,当EKF的线性化点准确时(就像在视觉惯性导航问题中发生的那样),滤波和MAP估计之间的性能不匹配会变得很小。当使用滑动窗口滤波器以及潜在的不一致源时,将尽量慎用EKF。
正如下一节所讨论的,MAP估计通常在传感器数据的预处理版本上执行。因此,它通常被称为SLAM后端。