Python pandas删除DataFrame中的重复行以及查看删除行数据总结
在处理csv文件时,我们经常会遇到重复行的出现,根据需求,可以将删除重复行分为两种情况。
第一种情况, 删除上一个重复行,保留下一个重复行
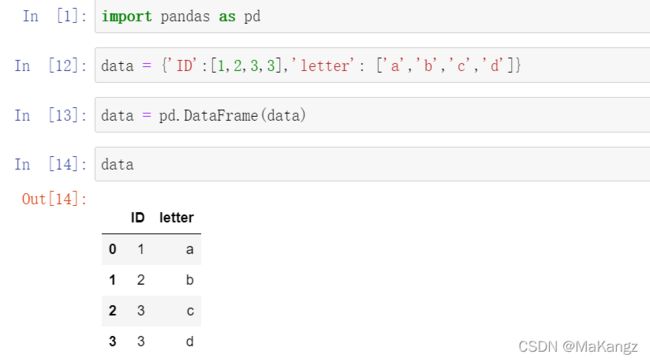
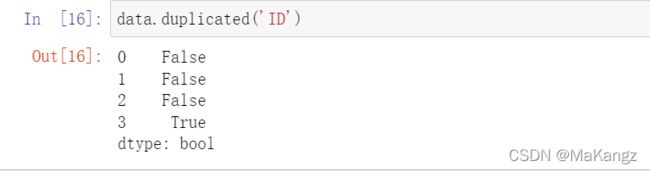
使用DataFrame来查看我们刚刚输入的表格,使用duplicated()函数来查看重复数据,如果数据重复就返回True,否则返回False,为bool类型的数据;也可以调用duplicated('你要指定的列')指定列来查看重复数据,不指定则默认为第一列,如上图的ID列;
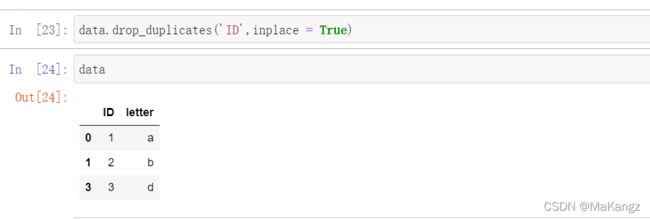
使用函数drop_duplicates('num',inplace = True)来删除指定的数据,可以指定返回的True数据也可以指定返回的False数据, num为指定删除的列;默认删除第一列重复的后面一个数据;
第二种情况 保留上一个重复行,删除下一个重复行
其实这种情况很简单就能做到,我们只需在drop_duplicates('num',inplace = True)中增加一个指定值,如drop_duplicates('num',keep = 'last', inplace = True)就可以实现保留上一个重复行,删除下一个重复行的情况;
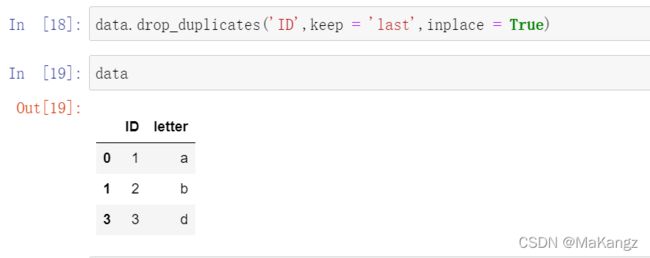
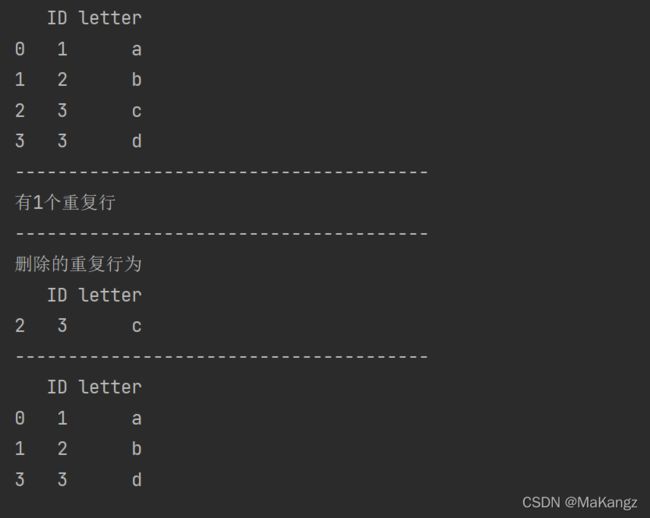
另外,你也可以用过以下代码查看重复行数和你删除的行数据
dep_data = data.duplicated('ID').sum()
print(f'有{dep_data}个重复行')
print('---------------------------------------')
dep_line = data[data.duplicated('ID',keep = 'last')] # 查看删除重复的行
print(f'删除的重复行为\n{dep_line}')综上,所有代码可以总结为:
import pandas as pd
data = {'ID':[1,2,3,3],'letter': ['a','b','c','d']}
data = pd.DataFrame(data)
print(data)
print('---------------------------------------')
data.duplicated('ID')
dep_data = data.duplicated('ID').sum()
print(f'有{dep_data}个重复行')
print('---------------------------------------')
dep_line = data[data.duplicated('ID',keep = 'last')] # 查看删除重复的行
print(f'删除的重复行为\n{dep_line}')
print('---------------------------------------')
data.drop_duplicates('ID',keep = 'last',inplace = True)
print(data)
输出结果为: