部分常见数据集整理与使用(MNIST,CIFAR,Pascal VOC...)
声明:笔者整理了过去用过的部分数据集,部分文字和图片来源已遗忘,如有侵权请联系作者删除博文,谢谢~!
1. MNIST
1.1 数据集介绍
MNIST是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。
2.2 官网及下载
下载官方网站: http://yann.lecun.com/exdb/mnist/
一共4个文件,训练集、训练集标签、测试集、测试集标签

2.3 导入MNIST数据集
读入MNIST数据集:直接下载下来的数据是无法通过解压或者应用程序打开的,因为这些文件不是任何标准的图像格式而是以字节的形式进行存储的,所以必须编写程序来打开它。
我们使用TensorFlow进行解压,使用TensorFlow中input_data.py脚本来读取数据及标签,使用这种方式时,也可以不用事先下载好数据集,它会自动下载并存放到你指定的位置。
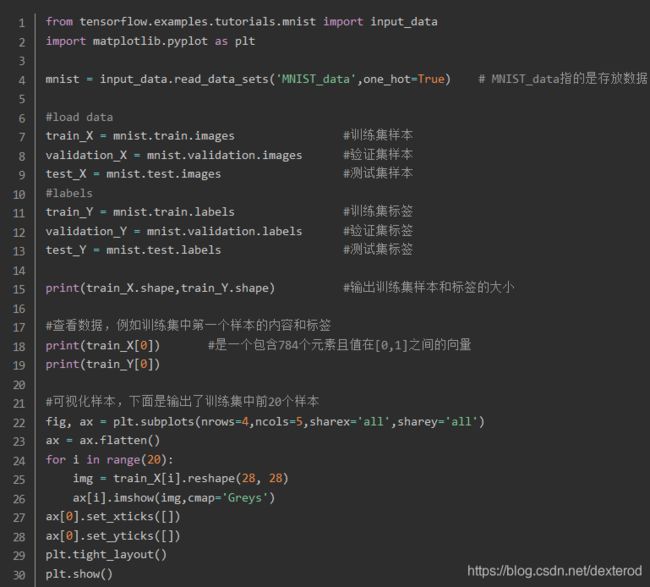
输出为:

mnist.train.images.shape是一个形状为【55000,784】的张量,其中第一维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0~255之间。
相对应的,MNIST数据集的标签是介于0~9之间的数字,用来描述给定图片里表示的数字。标签数据是“one-hot vectors”:一个one-hot向量,除了某一位的数字是1外,其余各维度数字都是0。例如,标签0将表示为([1,0,0,0,0,0,0,0,0,0,0])。因此,mnist.train.labels是一个[55000,10]的数字矩阵。
2. CIFAR
2.1 数据集介绍
CIFAR由 Alex Krizhevsky、Vinod Nair和Geoffrey Hinton收集而来,起初的数据集共分为10类,分别为飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车,所以CIFAR数据集常以CIFAR-10命名。CIFAR共包含 60000 张 32×32 的彩色图像(包含50000张训练图片,10000张测试图片),其中没有任何类型重叠的情况。因为是彩色图像,所以这个数据集是三通道的,分别是R,G,B 3个通道。
后来CIFAR又出了一个分类更多的版本叫CIFAR-100,从名字也可以看出共有100类,将图片分得更细,当然对神经网络图像识别是更大的挑战了。有了这些数据,我们可以把精力全部投在网络优化上。
2.2 官网及下载
CIFAR的官网为 http://www.cs.toronto.edu/~kriz/cifar.html ,不同于MNIST数据集,它的数据集是已经打包好的文件,分别为Python、MATLIB、二进制bin文件包,以方便不同的程序读取。
本文作者使用的是Python3,Tensorflow架构,以下下载和使用以此为环境。
与MNIST类似,TensorFlow中同样有一个下载和导入CIFAR数据集的代码文件,不同的是,自从TensorFlow1.0之后,将里面的models模块分离了出来。下载和导入CIFAR数据集的代码在models里面,所以要先去TensorFlow的GitHub网站将其下载下来。
git clone https://github.com/tensorflow/models.git
代码下载后,将其解压,将里面models/tutorials/image/路径下的CIFAR10复制到本地的Python工作区即可。
现在可以在CIFAR10文件夹下新建Python文件,用来下载和导入CIFAR10图片了。与MNIST不同的是,CIFAR数据集代码不是很方便,下载和导入时都需要单独调用。
将如下代码文件放到cifar10文件夹下(确保import cifar10能找到对应文件),引入CIFAR10,使用函数 maybe_download_and_extract 即可完成数据的下载和解压。
import cifar10
cifar10.maybe_download_and_extract()
上面的代码会自动将 CIFAR10 的 bin 文件 ZIP 包下载到 \tmp\cifar10_data路径下(如果是Windows就是本地磁盘下的这个路径,如 D:\tmp\cifar10_data),然后自动解压到\tmp\cifar10_data\cifar-10-batches-bin路径下。
在两行代码之后,会看到对应路径下生成的相关文件,如下图所示。其中:
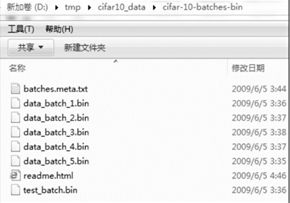
- batches.meta.txt: 标签说明文件。
- data_batch_x.bin:是训练文件,一共有5个,每个10000条。
- test.batch.bin: 10000条测试文件。
2.3 导入并显示CIFAR数据集(乱图)
这里通过 import cifar10_input 来导入CIFAR数据集,cifar10_input.py 里定义了获取数据的函数,具体调用见代码。
import cifar10_input
import tensorflow as tf
import pylab
batch_size = 128
data_dir = 'D:\Python_pictures\cifar-10-batches-py'
image_test, labels_test = cifar10_input.inputs(eval_data=True, data_dir=data_dir, batch_size=batch_size)
cifar10_input.inputs是专门获取数据的函数,返回数据集和对应的标签,但是cifar10_input.inputs函数会将图片裁剪好,由原来的32×32×3,变成了24×24×3。该函数默认是使用测试数据集,如果使用训练数据集,可以将第一个参数传入eval_data=False。另外,再将batch_size和dir传入,就可以得到dir下面的batch_size个数据了。
注意: 这里所获得的图片并不是原始图片,是经过了两次变换,首先将32×32尺寸裁剪成了24尺寸,然后又进行了一次图片标准化(减去均值像素,并除以像素方差)。这样做的好处是,使所有的输入都在一个有效的数据分布之内,便于特征的分类处理,会使梯度下降算法的收敛更快。
cifar10_input.py中除了对图像进行了一些预处理,还提供了一个读取大数据的方法示例,即使用queue的方法示例。queue是TesonFlow里常用的方法,尤其是在使用大数据样本做训练时。
sess = tf.Session()
tf.global_variables_initializer().run(session=sess)
tf.train.start_queue_runners(sess=sess)
image_batch, label_batch = sess.run([images_test, labels_test])
print('__\n', image_batch[0])
print('__\n', label_batch[0])
pylab.imshow(image_batch[0])
pylab.show()

代码中,session用的是tf.InteractiveSession函数,又额外使用了一个train.start_queue_ runners函数,是运行队列的意思。上面代码的输出是图片像素数据和标签数据。可以看到,读取的数据都是进过标准化处理的(变成了均值为0,方差为1的数据分布),所以输出的图片就是乱的。
2.4 显示原始图片
如果希望看到正常的数据怎么办呢?有两种方式:
- 修改cifar10_input.py文件,先让它不去标准化。
- 手动读取数据并显示。
这里展示手动读取原始图片并显示:
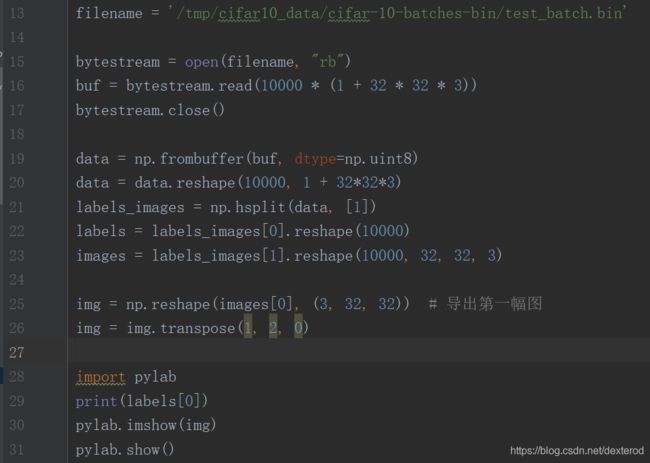
这次得到的是真实的原始图片,尺寸为32×32×3。
3. Pascal VOC
3.1 相关网址
Pascal VOC网址:http://host.robots.ox.ac.uk/pascal/VOC/
查看各位大牛算法的排名的 Leaderboards:http://host.robots.ox.ac.uk:8080/leaderboard/main_bootstrap.php
为目标检测制作PASCAL VOC2007格式的数据集:https://blog.csdn.net/hitzijiyingcai/article/details/81636455
3.2 内容介绍
数据集下载后解压得到一个名为VOCdevkit的文件夹,该文件夹结构如下:
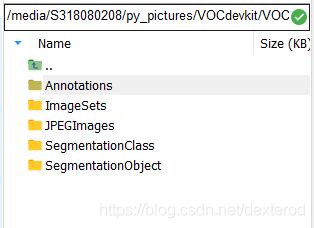 其中每个文件夹的内容和功能如下:
其中每个文件夹的内容和功能如下:



剩余两个文件夹与图片分割任务相关…
PS: 其余的部分数据集会在之后上传,未完待续哦~ ~