深度学习-神经网络基础
1.机器学习的流程:数据获取 -> 特征工程 -> 建立模型 -> 评估与应用。
2.深度学习(神经网络 像一个大黑盒子)的核心(核心问题)就在于特征工程,在于对特征的提取,拿到数据后,让机器真正的学习一下什么样的特征是比较合适的,怎么组合是合适的。
3.特征工程的作用:数据特征决定了模型的上限,预处理和特征提取是最核心的,算法与参数的选择决定了怎么去逼近这个上限。
4.深度学习的应用:主要应用与计算机视觉(自动驾驶、人脸识别)和自然语言处理中。
5.深度学习最大的问题:由于参数量极大,导致其对设备要求高,运行速度也会更慢,对于移动设备的部署较难。
6.深度学习与传统人工智能算法相比:在数据量不大时,深度学习与传统人工智能算法差距不大,甚至传统人工智能算法的速度更快,但是当数据量很大时,参数超多时,深度学习的优势就非常明显了。
7.机器学习/深度学习常规套路:①收集数据并给定标签②训练一个分类器③测试,评估
8.视觉任务中遇到的问题:比如用k近邻算法做图像分类,此时由于图片中的主体只占图片的部分,而其它部分会对图像的分类产生很大的影响,导致k近邻不能做图像分类。主要原因是k近邻算法没有学习的过程,不知道什么是主体什么是背景。
9.神经网络基础
①线性函数/得分函数:
如 猫的图片(32×32×3) -> f(image,weight) 图片与权重(为了区分图片中不同像素点的重要程度,比如背景不重要) -> 得到这个图片在所有分类中每个类的得分(f计算的结果)。
每个分类对应的权重不一样,所以有十组不同的weight,对于照片image,那么f(image,weight) = weight * x,为了一次性计算出来,可以对x与weight进行拉长,x变为3072 * 1的矩阵,weight变为1 * 3072的矩阵,又有10个类别,所以可以将weight矩阵写为10 * 3072的矩阵,那么最终f计算出来的结果就是一个10 * 1的向量,也就是这张图片对应每个分类的得分。当然也可以将f写成f(image,weight,b) = weight * x + b,b(10 * 1)就是一个微调量。
通常把weight(决定性)叫权重参数,b(微调)叫偏置参数。
②损失函数(衡量一个事情有多差,损失越多就越差):
神经网络整个的任务就是在找什么样(不停的调整)的weight矩阵能更适合于这个任务,weight中的值对结果能产生决定性的影响。

公式解析:如果给定一个图片进行预测其所属种类,那么根据得分函数计算,我们可以计算出它对应的每个分类的得分,此时我们要用它其它分类的得分与它本就属于该分类的得分,进行按上述公式进行计算损失。这个公式里的1,相当于一个容忍程度,至少要保证正确的类别比其高1,才认为它是好的。
如给出一张猫的图片,预测为猫的得分是3.2,预测为车的得分为5.1,预测为青蛙的得分为-1.7,那么最终L=max(0,5.1-3.2+1)+max(0,-1.7-3.2+1)=2.0。若损失值为0,说明就是做得好。
损失函数的改进:
有时不同的模型预测的最终得分是一致的,但是有些模型(权值weight)的权重分布不好,可能导致其过拟合,所以此时要加上正则化惩罚项对损失函数进行改进。
损失函数=数据损失+正则化惩罚项。

公式解析:公式其中的主体部分就和上面的公式一致,对于该模型的损失函数计算,就是给定一组图片来计算损失L。其中后面的加和项就是正则化惩罚项,它本质上只和权重(网络模型)有关。

公式解析:正则化惩罚项中的k与l也就是权重矩阵的行数与列数。
(不希望模型太复杂,过拟合的模型无用,过拟合:在训练集效果好,但测试集不好。)
③Softmax分类器
通过上述的过程,我们可以得到一个输入的得分值,但是我们更要的是属于这个分类的概率。
可以使用Sigmoid函数(给定一个数能将其映射到0与1之间),将得分值转化为一个概率值。
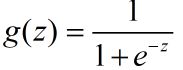
而若想得到一个概率值,也可以用Softmax分类器:
首先是归一化处理:

公式解析:本质上就是在计算模型预测某一图片时,预测该类别的得分在预测类别总得分(加和,如给定一张图,预测为猫的得分为3.2,预测为车的得分为5.1,预测为青蛙的得分为-1.7)中的中所占的概率,取e的作用是为了放大得分的效果。
再进行信息熵计算损失值(最常用的):
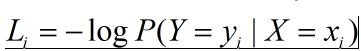
公式解析:这个计算出的结果,也很简单,如果预测属于该类别的分数很高,那么L就会越小,反而L就会越大。
④神经网络的前向传播整体流程
神经网络的前向传播就是按照流程计算损失值。
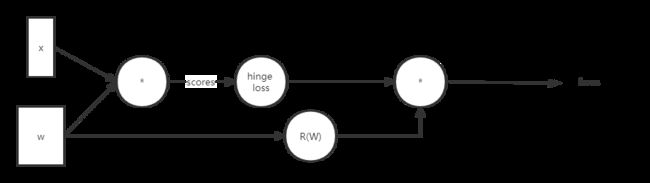
⑤神经网络最大的目标就是更新weight,对于前向传播中,未必只有一个W,进行一次变换,可能会进行很多次变换,如预测一个猫的图片,有的W可能是为了增强猫,弱化背景,有的W可能是为了增强猫的胡须,同时最后得到的得分函数,也是这几次变换一起的结果。
⑥反向传播计算方法
反向传播计算就是使用梯度下降(想想线性回归的例子)。
引入:当得到一个目标函数后如何求解?
常规套路:机器学习的套路就是交给机器一堆数据,告诉它什么样的学习方式是对的(目标函数),然后让它朝着这个方向去做。
如何优化:一步步迭代,找到最优解。
最终也就归结到给定目标函数为损失函数,如何求解损失最小的问题。
对于神经网络的反向传播:如[(xw1)w2]w3=f,经过计算得到f,这里面使用梯度下降,从w3->w1分别看他们对该结果做出了多大贡献,要从后往前,逐层的计算,这也就是链式法则,梯度是一步步传播的。
举例:一个简单的例子,如f(x,y)=1/(x+y),那么整体的神经网络就是:
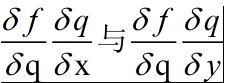
在反向传播中有一些常见的门单元(一种操作):
加法门单元:均等分配,均等分配的意思是,如果有q=x+y,那么q不论对谁求偏导,结果都是1,然后再乘以前面的偏导结果,相当于给x与y都一样。
MAX门单元:给最大的,只会把梯度传递给x与y中最大的那个。
乘法门单元:互换的感觉,呼唤的意思是,如果有q=xy,那么对谁求偏导,都是相反的,如对x,则会乘以y对应的值。
10.神经网络的整体结构
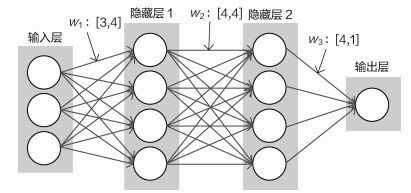
层次结构:神经网络是一个层次结构,一层一层的来变换数据。
神经元:比如上图输入层的三个神经元,就可以把它当作输入数据的特征数,如小猫的示意,32×32×3,有3072个像素点,对应输入层就有3072个神经元。
全连接:就是上一层的每个神经元都与下一层的每个神经元相连,隐层就是把数据转化为计算机更加认识的数据。补充一个batch概念,batch(批)的意思是一开始输入的数据是多少个,如我们只输入一个预测数据,这个输入数据有三个特征,那就是1×3,如果是两个预测数据,就是2×3(根据上述结构图)。
非线性:如上图的过程可以理解为是[(xw1)w2]w3的过程,但是不能用xw4(w4=w1w2w3)来代替,因为神经网络在每次进行一次变化之后,都会进行一次非线性变换,如使用sigmod函数等。
根据上述的说法,整体结构就可以如下:
基本机构:f=W2max(0,W1x),继续堆叠一层:f=W3max(0,W2max(0,W1x))
11.神经元个数对结果的影响
隐藏神经元越多,结果越精确,但是模型的过拟合可能就越高。
若增加一个神经元就相当于增加了一组参数(weight矩阵要加一组)。
12.正则化和激活函数
①正则化(lamada*R(w))的作用:惩罚力度。
通过设置lamada不同的惩罚力度,使得模型预测的结果更好,但是lamada值选多少,要在测试集上待定。

对于lamada=0.001时,存在一定的过拟合现象,即在第四个正方块中,那个红点的周围都是绿色,如果有数据出现在那儿,多半也应该时绿色点,所以调整lamada使其更好。
②激活函数
神经网络在进行×一组权重参数之后,要进行一次非线性变换(因为线性变换无法表示结果,就比如对于数据集的划分,无法用线性函数进行划分),这时就需要用到激活函数,常见的激活函数(Sigmoid,Relu,Tanh等)。

由于Sigmoid函数在数值很大时,会出现梯度为0的情况(也称为梯度消失),又由于链式法则,所以我们认为对于链乘其会导致整体为0的情况,不好。
13.神经网络过拟合的解决办法
①数据预处理
对原始数据进行-均值/均差
②参数(权值矩阵)初始化
参数的初始化很重要,通常都是使用随机策略来进行参数初始化(然后训练的时候进行更新)
w=0.01*np.random.randn(D,H),乘0.01的目的是为了让参数更加均匀(差距小,不存在有的是50,有的是1的情形)。
③DROP-OUT(训练阶段)
神经网络最大的问题就是因为这个网络太大,DROP-OUT的作用是在每层进行随机的选择部分神经元进行杀死(每次训练的过程中),让在迭代的过程中其参数不参加迭代,让其能力没那么强,减少过拟合的风险。

以上过程的所有目的都是为了去算出更适合这个任务的W1,W2等等,计算出后,这个模型就训练结束了。最终目的就是找结果,让其是最合适的。