今天给大家分享的是关于地理空间的数据分析
今天给大家分享的是关于地理空间的数据分析

数据璐
大数据分析岗位推荐师
我们做数据分析之前首先要了解业务
地理空间数据可以用来描述地球表面的任何物体或特征,举几个常见的例子来帮助大家理解
比如:一个品牌的下一家店应该开在哪里?
天气如何影响区域销售?
开车的最佳路线是什么?
哪个地区将受到飓风的严重打击?
冰盖融化与碳排放的关系如何?
哪些地区将面临最高的火灾风险?
本次案例中我们用到的是geopandas和shapely,它们是用Python进行地理空间分析的两个最有用的库
Shapely - 一个允许操作和分析平面几何对象的库。
Geopandas - 一个允许你处理代表表格数据的shapefiles的库(如pandas),其中每一行都与一个几何体相关。它提供了对许多空间函数的访问,用于应用几何图形、绘制地图和地理编码。Geopandas内部使用shapely来定义几何图形。
基本的shapely对象是点、线和多边形,但你也可以在同一个对象中定义多个对象,然后你就获得了多点、多线和多角形。这些对于由各种几何形状定义的对象很有用,比如有岛屿的国家。
出于其直接且直观的特性,我们可以用shapely库做很多很多的事情,所以一定要仔细查看文档
另一个用于处理地理空间数据的工具是geopandas
我们知道pandas 的 DataFrames 表示表格数据集,同样地,geopandas 的 DataFrames 表示的是有两个扩展功能的表格数据集。
1、geometry列定义了一个与其他列相关的点、线或多边形。这一列是一个shapely对象的集合。你能对shapley的形状对象做什么,你也能对geometry对象做什么。
2、CRS列是geometry列的坐标参考系统,它告诉我们一个点、线或多边形在地球表面的位置。Geopandas将一个几何体映射到地球表面(例如,WGS84)。
数据框架还包括一个CRS,将geometry列中定义的多边形映射到地球表面。
在我们今天的案例中,CRS是EPSG:4326。该CRS使用纬度和经度作为坐标。
在做可视化的过程中,我们可以在world_gdf上调用.plot(),就像调用pandas的dataframe一样。
当然这个图看起来比较粗糙哈,我们改进一下
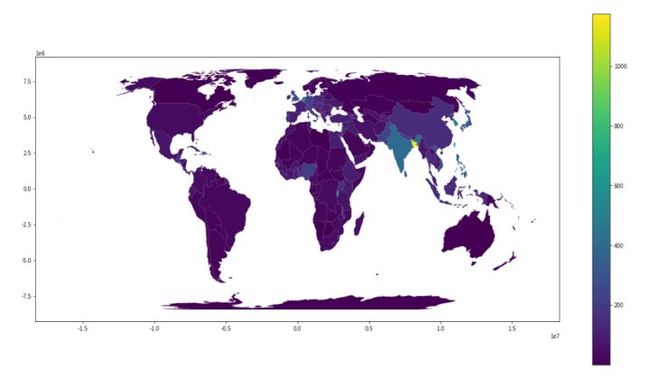
我们改为墨卡托投影,因为它更方便。使用参数to_crs('epsg:4326')可以做到这一点
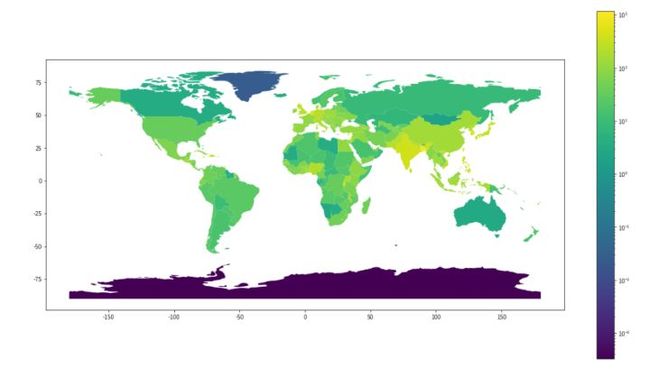
然后将色条转换为对数刻度,这可以用matplotlib.colors.LogNorm(vmin=world.pop_density.min(), vmax=world.pop_density.max())来实现
我们可以像在matplotlib上直接传递不同的参数给绘图函数。
这个图比上面那个图看起来就好多了吧~
到目前为止,我们已经简单了解了shapely和geopandas的基本知识啦,接下来就来看看今天的案例
案例研究的主题是80年代欧洲霍乱爆发的来源
我们将使用现代的Python工具重做约翰-斯诺的分析,确定80年代伦敦霍乱爆发的来源。
我们首先来看看数据文件中都包含了什么
矢量数据:
Cholera_Deaths : 某一空间坐标上的死亡人数
Pumps:水泵的位置
我们可以忽略矢量数据的其他文件,只处理'.shp'文件。.shp被称为shapefiles,是矢量对象的标准格式。
光栅数据:
OSMap_Grayscale : 光栅--来自OpenStreet Maps (OSM)的该地区的地理参照灰度地图
OSMap : 光栅--来自OpenStreet Maps (OSM)的该地区的地理参考图
SnowMap : 光栅 -- 数字化和地理参照的约翰-斯诺的原始地图
我们可以忽略栅格数据的其他文件,只处理'.tif'文件。'.tif'是存储光栅和图像数据的最常见的格式。
在导入了geopandas和matplotlib之后,我们再导入用于绘制地图的contextily就好
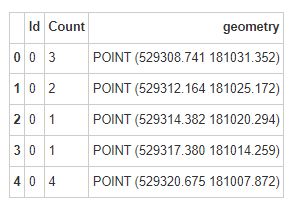
输出结果看起来和pandas数据框架完全一样,与geopandas的数据框架唯一不同的是几何列,那这个是我们矢量数据集的本质。
在本次案例中,它包括了约翰-斯诺记录的死亡点的坐标。
然后我们来看看CRS的数据是什么样子的:

有一个区别是正确定义的形状文件包括阐明其坐标参考系统的元数据
在这种情况下,它是EPSG:27700。
然后来看一下水泵的数据:
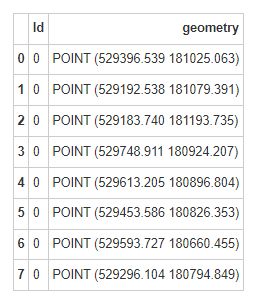
同样,pump_df保存了Broad Street附近的水泵的位置。
我们需要注意的是!!!在处理地理空间数据时,应该确保我们的所有来源都有相同的CRS。这一点需要强调强调再强调。
这可能是处理地理空间数据时所有错误的最常见来源
然后接下来,我们可以在伦敦布罗德街的地图上绘制死亡和泵的数据
首先通过绘制死亡人数来建立该图
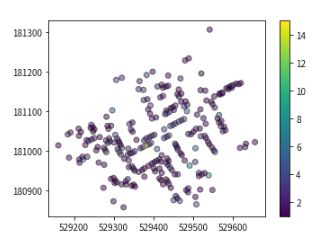
有了ax的参考,我们就可以在它们的位置上绘制水泵,用红色的X标记它们, 我们还可以把图放大。
有了ax的参考,我们就可以在它们的位置上绘制水泵,用红色的X标记它们, 我们还可以把图放大。

随后,我们现在想在数据下面显示一张伦敦布罗德街的地图。这时我们可以使用contextily来读取CRS的数据。
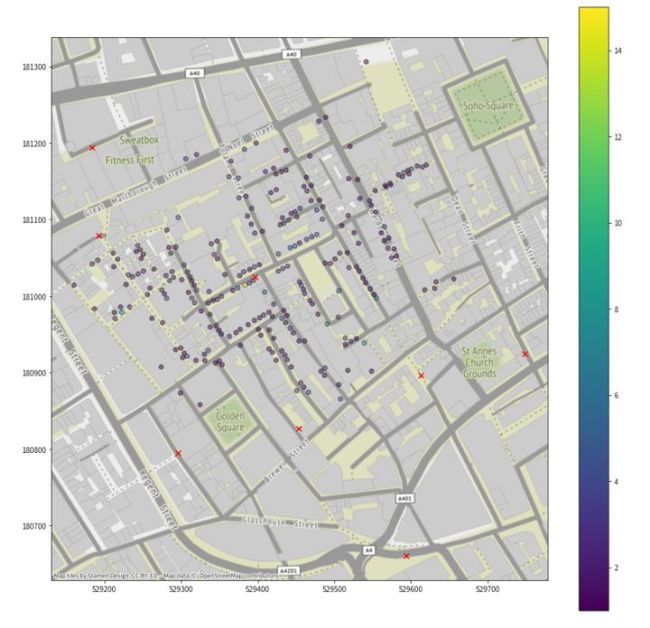
我们在约翰-斯诺的原始地图上来看看同样的数据,可以通过改变source参数为SnowMap.tif
结论:
约翰-斯诺了解到的是,大多数霍乱患者都集中在布罗德街和列克星敦街交叉口的一个特定水泵周围(地图中间附近的红色X),他将霍乱的爆发归因于该水泵的感染性供水。
通过本次案例,我们可以了解到,数据分析需要结合实际业务场景,关于地理空间数据我们需要了解其基本概念,矢量和栅格的区别、地理编码和地理参考的区别都需要有所了解,才能够处理好地理空间矢量及进行分析。
注册的案例中我们找到了受感染的水泵,它是80年代伦敦霍乱爆发的根源。但是在我们实际工作中,可不能就停留在这个阶段哈,老板找我们来是解决问题的哦,所以要给出针对性的对策和解决方案哈!