基于地理位置的数据挖掘
https://zhuanlan.zhihu.com/p/24510479?utm_source=tuicool&utm_medium=referral
一般我们在做数据挖掘过程中地理位置算是一个特别重要的特征,广泛应用于O2O的很多场景。但做的事情都相对来说比较简单,LBS的网格位置推相应的内容。原来我们基于地理位置拿了不少数据,也做了一些模型,主要是一些医院位置、商场位置、公交地铁位置等来给附近的人推服务。
——————————————————禁止转载———————————————————
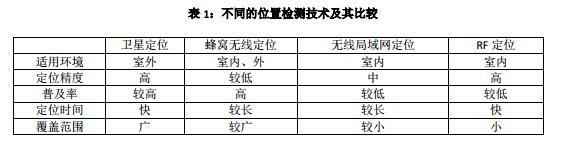
不同定位比较:
在当前众多的无线定位技术中,GPS 以其覆盖范围广、定位精度高、定位时间短和定位依赖性小等优势逐渐在人们的日常生活中变得普及起来(见表 1)。各种车载 GPS、手持GPS 和 GPS 智能手机的相继问世也为人们提供了更加便捷的位置获取和轨迹记录方式。作为用户经历的载体,这些轨迹数据在各种应用中发挥着重要的作用,并帮助人们来理解个人行为和社会规律。从数据源来看,当前的研究工作可分为基于个人轨迹数据的理解和基于多人轨迹数据的理解两个方向。
场景:
用户历史轨迹中出现的频繁模式反映了个人的生活习惯和行为规律。如果可以很好的从轨迹中理解到这些知识,服务提供商将可以为用户提供更深入、更个性化的位置服务。而要从轨迹中挖掘这些频繁模式,首先要面临的困难就是如何对个人的历史轨迹建模。
如图 1 所示,一条 GPS 轨迹通常由一系列带有时间戳的坐标点组成。每个坐标点包含了经度、纬度和海拔高度等基本信息。一个人在一段时间内的活动就可记录为这样一条连续的轨迹。在这条轨迹中,我们可以通过算法检测出一些用户停留过的地方。这个停留点并不是指速度为零的点,而是由一组实际的 GPS 点构成,如图 1 中 p3, p4, p5 和 p6构成了一个停留点 s。它表示用户在某个区域内滞留的时间超过了一定的时间范围。与其他 GPS 点相比,这些停留点含有更重要的语义信息,如用户去过的餐馆和电影院等。基于这些停留点,一个用户的历史轨迹就可以表达为一个停留点序列,如
。这个序列抓住了用户行为的重点,同时也大大减轻了数据处理量。

图 1. 一条 GPS 轨迹样例
——
由于用户多次访问同一地点所产生的停留点并不完全一致(坐标会有偏差),直接对停留点进行比较并不可行。因此,我们需要对从轨迹中提取出来的停留点进行聚类。这样相近的停留点就会被分配到同一个聚类中。此后,我们再用各个停留点所归属的聚类来替换这个停留点,将停留点序列进一步转化为聚类的序列。这样用户在不同时间段的历史轨迹就可比了。
有了用户历史轨迹的模型,我们可以用多种算法(如 FP-growth、Closet+等)来挖掘这个数据中的频繁项集。如用户 A 经常在周末早上去中关村、用户 A 经常在周五晚上去超市等。进一步,这些频繁模式,可以相互组合和连接,从而发现一些表征了用户生活、行为规律的顺序模式(sequential pattern)。比如,通常用户 A 在周末早上会去中关村看电影,然后下午去西单买东西。当然,这些学习到的模式将受到隐私保护,并只为用户个人所用。
在挖掘有意思的地点和经典旅行线路时,首先就要对不同用户的轨迹数据建模。如图2所示,我们首先从每个用户的每条线路中提取出停留点(在图中表示为绿色小点),并把它们放在一个集合中。然后,利用一种基于密度的聚类算法,我们对这个停留点集合进行层次化聚类,在不同的地理尺度上,将相近的停留点划分到同一个聚类(图中灰色节点,如 等)。这样我们可以得到一个如图右半部分所示的一个层次树。树中的节点代表不同的停留点聚类,而不同层次表示不同的地理空间尺度。层次越深,粒度越细,代表的地理空间也越小。随后,将不同用户的轨迹映射到这棵树的各个层次,就可以将不同的聚类连接起来,从而得到不同的图模型(如图 2左半部分所示)。
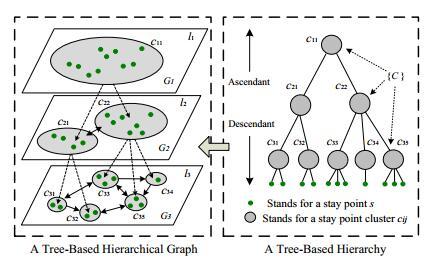 图 2. 基于层次图模型的多用户轨迹聚合
图 2. 基于层次图模型的多用户轨迹聚合
——
正如前面提到过的,轨迹隐含了人的行为和喜好。因此,人们在地理空间移动的相似性,也在一定程度上反映了不同人之间品味和爱好的相似性。这里,我们首先按照如图 3 所示的方式用不同的层次图来建模每个用户的历史轨迹,然后成对地比较图和图之间的相似性。
与之前提到过的大众数据建模方法一致,我们仍然利用层次化聚类的思想将所有用户的停留点转化为一个公共的层次树(图3 中间的部分),树中的各个节点(停留点聚类)表示不同尺度和粒度的地点。此后,将每个用户的线路分别导入这个公共的框架,便可得到用户各自的层次图(图3 的左右两个部分分别表示用户 1 和 2 的层次图)。
在通过匹配两个层次图来计算用户相似性的时候,我们考虑以下两点因素:
1) 层次。两个人的相似性,可表示为两个层次图中各个对应层次上的图的相似性的加权和。这里的权重就是由层次的深度来决定。由于较深的层次具有较细的空间粒度和尺度,两个用户在越深的层次上的图越相似,则表明他们的活动轨迹越相似。因此,深层次的匹配结果应被赋予较大的权重。比如,两个人都在中国就不如两个人都在北京市相似。如果能发现两个人在代表学校和景点这种更细粒度的层次上仍有重叠,则说明这两个人更相似。
2) 相似序列的长度。同一图层上两幅图的相似性,可表示为这两个图共享序列的相似性的和。而序列的相似性,又取决于序列的长度。因此,用户共享的序列越多,序列的长度越长,则这两个图的相似性越大。如 A、B 和 C 三个用户,A 和 B 共同走过了一个长度为 2 的序列 ,而 A 和 C 两个共同走过一个长度为 3 的序列 。显然,与 B 相比,用户 C 更加跟 A 相似。
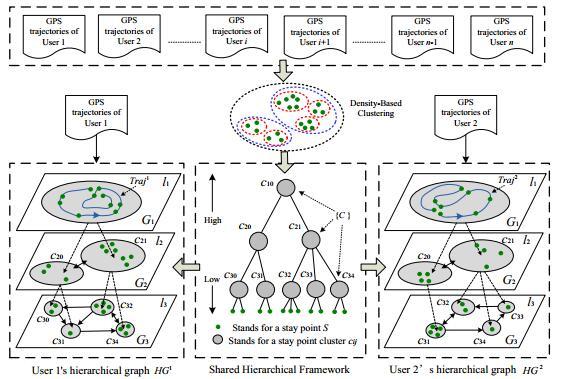 图 3. 利用层次图来比较用户的相似性
图 3. 利用层次图来比较用户的相似性
前面介绍的利用大规模轨迹数据实现大众化旅行推荐可找出一些公认的热门景点和经典旅行线路。但实际上不同的用户有不同的喜好,在每个人的心幕中各种景点的排名也不一样。比如,喜欢自然风景的用户可能对故宫这样的历史古迹并不是特别感兴趣;喜欢美食的游客也可能会更加关注哪些小吃聚集的街道。因此,针对个人的喜好来做个性化的推荐才是更人性化、更有效的位置服务。
我们设计的基于轨迹的个性化朋友和地点推荐包含以下三步:
1) 利用用户的历史轨迹计算出用户之间的相似性(参见上一节描述的方法),为某个用户找出最相似的 n 个人作为潜在的朋友,完成个性化朋友推荐。也许他们在现实生活中多次插肩而过,却从来没有认识的机会。由于他们具有相同的兴趣爱好,因此,当在论坛中发起一些活动的时候(如自驾游和登山等),用户能更加精准地找到一些兴趣相投的人。
2) 从这些潜在朋友的历史轨迹中查找出一些该用户没有去过的地点,并利用协同过滤的方法来估计该用户对这些地点的兴趣度。如图 4 所示,如果把用户和他们去过的地点用一个矩阵来表示,矩阵中的每个值表示用户曾去过这个地方的次数。那么我们就可以像 Amazon 根据用户的买书记录来推荐图书那样使用协同过滤来计算用户对未曾去过的地方的兴趣度。这里有个很重要的思想,即相似的人通常会做出类似的决定,所以越相似的人的经历越具有参考价值。
3) 按估算的兴趣度对用户未曾去过的地点排名,并把排名较高的 m 个地点推荐给用户。由于这个推荐是根据用户过去的经历分析出来的,因此是个性化的地点推荐。
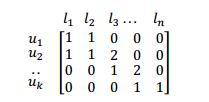
图 4. 用户和访问地点之间关系的矩阵表达方式
——————————————————禁止转载———————————————————
用途:
由于位置检测技术的迅猛发展,用户可在不干扰生活的前提下轻松地记录自己的旅行线路、运动经历、以及日常生活和工作轨迹。结合现有的地理信息数据库和电子地图,这些轨迹数据可为个人提供以下服务。
帮助用户更有效的回忆过去:个人的轨迹数据可看作是一种自动化的电子日记,从中用户可以清楚地了解自己过去的经历。比如,从这些数据中用户可以准确的知道上星期五自己的上班时间,午餐就餐地点以及在回家路上花费的时间等信息。这种功能对于外出旅行和户外运动更加有效。
更便捷的与朋友分享生活经历:互联网的普及催生了网络博客的发展。通过博客,朋友之间可以方便的分享近期的生活经历。最近在互联网上出现了一种以 GPS 轨迹数据为中心的新兴应用。在这些互联网的虚拟社区里,用户可以通过发布自己的轨迹数据来展现自己的旅行经历或运动线路。比如,自行车爱好者可以将自己的骑行线路利用 GPS 设备记录下来,然后通过互联网上载到论坛来与其他爱好者交流和分享。
理解自己的生活规律,提供个性化服务:当个人的数据积累到一定程度,该用户的生活规律已经在数据中得到了体现。因此,相当一部分的研究工作从个人的长期数据中分析出对用户具有重要意义的地点,比如家、公司和常去的商场和餐厅。进一步,根据用户过去的经历得出用户在这些地点的转移概率,从而能够对用户今后的活动作出较为准确的预测。例如,当用户被预测出将要前往某个商场,系统可将该商场的促销信息提前发送到用户的手机上。