两阶经典检测器: Faster R-CNN (Regions with CNN Features)
目录
- RCNN 系列发展历程
-
- 开山之作: RCNN
- 端到端: Fast RCNN
- 走向实时: Faster RCNN
- Faster RCNN 总览
- 详解 RPN (Region Proposal Network)
-
- 生成 Anchors
- RPN 的真值与预测量
- RPN 卷积网络
- RPN 真值的求取
- 损失函数设计
- NMS 生成 Proposal
- 筛选 Proposal 得到 RoI
- RoI Pooling 层
-
- RoI Pooling
- RoI Align
- 全连接 RCNN 模块
-
- RCNN 全连接网络
- 损失函数设计
- Faster RCNN 的改进算法
-
- 审视 Faster RCNN
- 特征融合: HyperNet
- 实例分割: Mask RCNN
- 全卷积网络: R-FCN (Region-based Fully Convolutional Networks)
- 级联网络: Cascade RCNN
- 扩展: Pytorch 官方 FasterRCNN 代码
- 参考文献
RCNN 系列发展历程
开山之作: RCNN
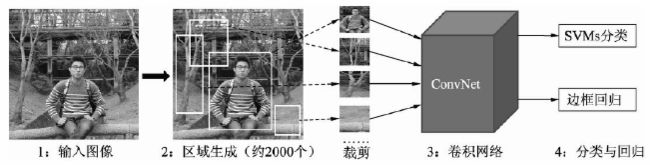
- RCNN 将 CNN 应用于特征提取,一举将 PASCAL VOC 数据集的检测率从 35.1% 提升到了 53.7%。RCNN 仍然延续传统物体检测的思想,将物体检测当做分类问题处理,即先提取一系列的候选区域 (RoI),然后对候选区域进行分类:
- (1) 候选区域生成。采用 Region Proposal 提取候选区域,例如 Selective Search 算法,先将图像分割成小区域,然后合并包含同一物体可能性高的区域,并输出,在这一步需要提取约 2000 个候选区域。在提取完后,还需要将每一个区域进行归一化处理,得到固定大小的图像
- (2) CNN 特征提取。将上述固定大小的图像,利用 CNN 网络得到固定维度的特征输出
- (3) SVM 分类器。使用线性二分类器对输出的特征进行分类,得到是否属于此类的结果,并采用难样本挖掘来平衡正负样本的不平衡
- (4) 位置精修。通过一个回归器,对特征进行边界回归以得到更为精确的目标区域
缺点
- (1) RCNN 需要多步训练,步骤烦琐且训练速度较慢
- (2) 由于涉及分类中的全连接网络,因此输入尺寸是固定的,造成了精度的降低
- (3) 候选区域需要提前提取并保存,占用空间较大
端到端: Fast RCNN
- Fast RCNN 基于 VGG16 网络,可以实现端到端训练,在训练速度上比 RCNN 快了近 9 倍,在测试速度上快了 213 倍,并在 VOC 2012 数据集上达到了 68.4% 的检测率。相比起 RCNN,Fast RCNN 主要有 3 点改进:
- (1) 共享卷积:将整幅图送到卷积网络中进行特征提取,然后在特征图上进行区域生成。虽然区域生成仍采用 Selective Search 方法,但共享卷积的优点使得计算量大大减少
- (2) RoI Pooling:利用特征池化 (RoI Pooling) 的方法进行特征尺度变换,这种方法可以有任意大小图片的输入,使得训练过程更加灵活、准确
- (3) 多任务损失:将分类与回归网络放到一起训练,并且为了避免 SVM 分类器带来的单独训练与速度慢的缺点,使用了 Softmax 函数进行分类

缺点
- 在 Fast RCNN 算法中,Selective Search 需要消耗 2~3 秒,而特征提取仅需要 0.2 秒,因此这种区域生成方法限制了 Fast RCNN 算法的发挥空间
走向实时: Faster RCNN
- Faster RCNN 最大的创新点在于提出了 RPN (Region Proposal Network),利用Anchor 机制将区域生成与卷积网络联系到一起,将检测速度一举提升到了 17 FPS (Frames Per Second),并在 VOC 2012 测试集上实现了 70.4% 的检测结果
Faster RCNN 总览
从功能模块来讲,Faster RCNN 主要包括 4 部分:
- (1) 特征提取网络 Backbone:输入图像首先经过 Backbone 得到特征图。以 VGGNet 为例,假设输入图像的维度为 3 × 600 × 800 3\times600×800 3×600×800,由于 VGGNet 包含 4 个 Pooling 层 (物体检测使用 VGGNet 时,通常不使用第 5 个 Pooling 层),下采样率为 16,因此输出的 feature map 维度为 512 × 37 × 50 512×37×50 512×37×50
- (2) RPN 模块 (区域生成模块):利用强先验的 Anchor 生成较好的建议框,即 Proposal (使用 Anchor 机制代替了 Fast RCNN 中最耗时的 Selective Search)。RPN 包含 5 个子模块:
- Anchor 生成:feature map 上的每一个点都对应了 9 个 Anchors,这 9 个 Anchors 大小宽高不同,对应到原图基本可以覆盖所有可能出现的物体。有了数量庞大的 Anchors,RPN 接下来的工作就是从中筛选,并对筛选出的 Anchor 位置进行微调,得到 Proposal
- RPN 卷积网络:由于 feature map 上每个点对应了 9 个Anchors,因此可以利用 1 × 1 1×1 1×1 卷积在 feature map 上得到每一个 Anchor 的前景预测得分与预测偏移值
- 计算 RPN loss:这一步只在训练中进行。它将所有的 Anchors 与标签进行匹配,匹配程度较好的 Anchors 赋予正样本,较差的赋予负样本,得到分类与偏移的真值,与 RPN 卷积网络得到的预测得分与预测偏移值进行 loss 计算
- NMS 生成 Proposal:利用 RPN 卷积网络得到的每一个 Anchor 预测的得分与偏移量,可以进一步得到一组较好的 Proposal,送到后续网络中
- 筛选 Proposal 得到 RoI:在训练时,由于 Proposal 数量还是太多 (默认是 2000),需要进一步筛选 Proposal 得到 RoI (默认数量是 256)。在测试阶段,则不需要此模块,Proposal 可以直接作为 RoI,默认数量为 300
- (3) RoI Pooling (Region of Interest) 模块:RoI Pooling 模块承上启下,接受 backbone 提取的 feature map 和 RPN 生成的 RoI,输出送到 RCNN 网络中来预测 RoI 的所属类别与偏移量。由于 RCNN 模块使用了全连接网络,要求特征的维度固定,而 RoI 是由各种不同大小的 Anchor 经过位置微调后生成的,对应的特征大小各不相同,无法送入到全连接网络,因此 RoI Pooling 将 RoI 的特征池化到固定的维度,方便送到全连接网络中
- (4) RCNN 模块 (RoI 分类):将 RoI Pooling 得到的特征送入全连接网络,预测每一个 RoI 的分类,并预测偏移量以精修边框位置,并计算损失。主要包含 3 部分:
- RCNN 全连接网络:将得到的固定维度的 RoI 特征接到全连接网络中,输出为 RCNN 部分的预测得分与预测回归偏移量
- 计算 RCNN 的真值:对于筛选出的 RoI,需要确定是正样本还是负样本,同时计算与对应真实物体的偏移量。在实际实现时,为实现方便,这一步往往与 RPN 最后筛选 RoI 那一步放到一起
- RCNN loss:通过 RCNN 的预测值与 RoI 部分的真值,计算分类与回归 loss
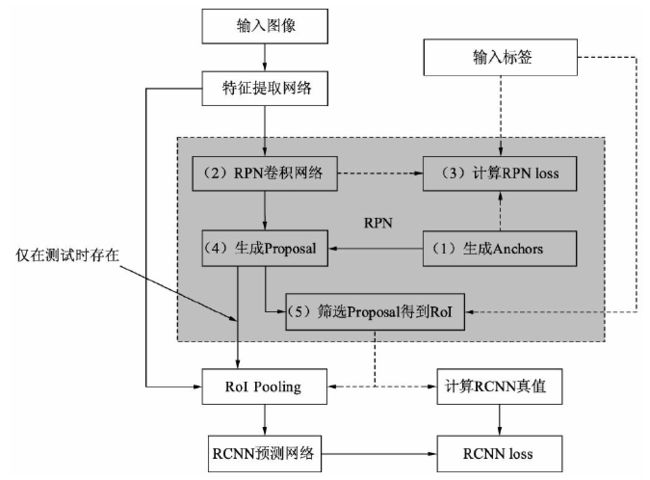
虚线表示仅仅在训练时有的步骤
- 从整个过程可以看出,Faster RCNN 是一个两阶的算法,即 RPN 与 RCNN,这两步都需要计算损失,只不过前者还要为后者提供较好的 RoI
详解 RPN (Region Proposal Network)
RPN 部分的输入、输出如下:
- 输入:feature map、物体标签,即训练集中所有物体的类别与边框位置
- 输出:RoI、RPN loss (分类 loss + 回归 loss)
生成 Anchors
- Faster RCNN 先提供一些先验的 Anchors,然后再去筛选与修正,这相当于将 Anchor 当做强先验的知识,相比起没有 Anchor 的物体检测算法,这样的先验无疑降低了网络收敛的难度
- Anchor 生成方法:Faster RCNN 默认在 feature map 的每一个点上抽取 9 种 Anchors (如果 backbone 的下采样率为默认的 16,则每一个点的坐标乘以 16 即可得到对应的原图坐标),具体 Scale 为 { 8 , 16 , 32 } \{8,16,32\} {8,16,32},Ratio (宽高比) 为 { 0.5 , 1 , 2 } \{0.5,1,2\} {0.5,1,2}。由于 feature map 大小为 37 × 50 37×50 37×50,因此一共有 37 × 50 × 9 = 16650 37×50×9=16650 37×50×9=16650 个 Anchors

利用 Scale 和 Ratio 生成同一个点对应的 9 个 Anchors
- 首先生成一个 16 × 16 16\times16 16×16 的 base anchor (base anchor 的大小是可以根据输入图像大小更改的, 16 × 16 16\times16 16×16 对应的输入图像大小为 800 × 600 800\times 600 800×600),然后对 base anchor 进行宽高变化,生成 3 种宽高比的 Anchors,然后将上面 3 个 anchors 再进行尺度变化,即宽高乘上 scale,得到最终的 9 种 Anchors
- 下面具体计算一下 800 × 600 800\times 600 800×600 的输入图像所对应的 Anchors 的宽高:
a r e a = w ⋅ h = h ⋅ r a t i o ⋅ h = r a t i o n ⋅ h 2 ∴ h = a r e a / r a t i o area=w\cdot h=h\cdot ratio\cdot h=ration\cdot h^2\\ \therefore h=\sqrt{area/ratio} area=w⋅h=h⋅ratio⋅h=ration⋅h2∴h=area/ratiobase anchor 的面积为 256,由 h = a r e a / r a t i o , w = h ⋅ r a t i o h=\sqrt{area/ratio},w=h\cdot ratio h=area/ratio,w=h⋅ratio 可知,3 种宽高比的 Anchors 对应的 h h h 分别为 23 , 16 , 11 23,16,11 23,16,11, w w w 分别为 12 , 16 , 22 12,16,22 12,16,22。接着对它们进行尺度变化即可。其中长宽比为 2 : 1 2:1 2:1 时,最大的 Anchor 为 736 × 384 736\times384 736×384,最小的 Anchor 为 184 × 96 184\times 96 184×96
RPN 的真值与预测量
- 对于物体检测任务来讲,模型需要预测每一个物体的类别及其出现的位置,即类别、中心点坐标 x x x 与 y y y、宽 w w w 与高 h h h 这 5 个量。由于有了 Anchor 这个先验框,RPN 可以预测 Anchor 的类别作为预测边框的类别,并且可以预测真实的边框相对于 Anchor 的偏移量,而不是直接预测边框的中心点坐标 x x x 与 y y y、宽高 w w w 与 h h h
RPN 的真值
- 类别的真值:由于 RPN 只负责区域生成,保证 recall,而没必要细分每一个区域属于哪一个类别,因此只需要前景与背景两个类别,前景即有物体,背景则没有物体。RPN 通过计算 Anchor 与标签的 IoU (Intersection over Union, 重合比例) 来判断一个 Anchor 是属于前景还是背景。IoU 超过一定阈值时就设定该 Anchor 的类别真值为前景

- 偏移量的真值:假设 Anchor A A A 的中心坐标为 x a x_a xa 与 y a y_a ya,宽高分别为 w a w_a wa 与 h a h_a ha,标签 M M M 的中心坐标为 x x x 与 y y y,宽高分别为 w w w 与 h h h,则对应的偏移真值为
 从上式可以看出,位置偏移 t x t_x tx 与 t y t_y ty 利用宽与高进行了归一化,而宽高偏移 t w t_w tw 与 t h t_h th 进行了对数处理,这样的好处是进一步限制了偏移量的范围,便于预测
从上式可以看出,位置偏移 t x t_x tx 与 t y t_y ty 利用宽与高进行了归一化,而宽高偏移 t w t_w tw 与 t h t_h th 进行了对数处理,这样的好处是进一步限制了偏移量的范围,便于预测
RPN 的预测量
- RPN 通过卷积网络来预测每一个 Anchor 属于前景与背景的概率以及真实物体相对于 Anchor 的偏移量,记为 t x ∗ , t y ∗ , t w ∗ , t h ∗ t_x^*,t_y^*,t_w^*,t_h^* tx∗,ty∗,tw∗,th∗
- 在得到预测偏移量后,可以使用下面的公式将预测偏移量作用到对应的 Anchor 上,得到预测框的实际位置 x ∗ x^* x∗、 y ∗ y^* y∗、 w ∗ w^* w∗ 和 h ∗ h^* h∗
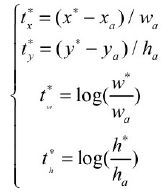
RPN 卷积网络

- RPN 卷积网络在 feature map 上首先用 3 × 3 3×3 3×3 的卷积进行更深的特征提取,然后利用 1 × 1 1×1 1×1 的卷积分别实现分类网络 (左分支) 和回归网络 (右分支)。分类网络用于判断 Anchor 是前景的概率,回归网络则是用于得到预测偏移量
分类网络
- 首先使用 1 × 1 1×1 1×1 卷积输出 18 × 37 × 50 18×37×50 18×37×50 的特征,由于每个点默认有 9 个 Anchors,并且每个 Anchor 只预测其属于前景还是背景,因此通道数为 18。随后利用
torch.view()函数将特征映射到 2 × 333 × 50 2×333×50 2×333×50,这样第一维仅仅是一个 Anchor 的前景背景得分,并利用nn,Softmax(dim=0)函数进行概率计算,得到的特征再变换到 18 × 37 × 50 18×37×50 18×37×50 的维度,最终输出的是每个 Anchor 属于前景与背景的概率
回归网络
- 回归网络利用 1 × 1 1×1 1×1 卷积输出 36 × 37 × 50 36×37×50 36×37×50 的特征,第一维的 36 包含 9 个 Anchors 的预测,每一个 Anchor 有 4 个数据,分别代表了每一个 Anchor 的中心点横纵坐标及宽高这 4 个量相对于真值的偏移量
RPN 真值的求取

(1) Anchor 生成
- 这部分与前面 Anchor 的生成过程一样,可以得到 37 × 50 × 9 = 16650 37×50×9=16650 37×50×9=16650 个 Anchors。由于按照这种方式生成的 Anchor 会有一些边界在图像边框外,因此还需要把超过图像边框的 Anchors 过滤掉
(2) Anchor 与标签的匹配
- 前面已经介绍了通过计算 Anchor 与标签的 IoU 来判断是正样本还是负样本。在具体实现时,需要计算每一个 Anchor 与每一个标签的 IoU,因此会得到一个 IoU 矩阵,具体的判断标准如下:
- 对于任何一个 Anchor,与所有标签的最大 IoU 小于 0.3,则视为负样本
- 过滤掉与所有 Anchors 的最大 IoU 为 0 的标签。对于任何剩余标签,与其有最大 IoU 的 Anchor 视为正样本
- 对于任何一个 Anchor,与所有标签的最大 IoU 大于 0.7,则视为正样本
- 需要注意的是,上述三者的顺序不能随意变动 (对于上面三条规则,对 Anchors 的标签赋值从上往下进行,第三条规则具有最高优先级),要保证一个 Anchor 既符合正样本,也符合负样本时,赋予正样本 (这是为了保证这一阶段的召回率) (没有打标签的 Anchor 不做考虑,相当于直接筛选掉了)
(3) Anchor 的筛选
- 由于 Anchor 的总数量接近 2 万,并且大部分 Anchor 的标签都是背景,如果都计算损失的话则正、负样本失去了均衡,不利于网络的收敛。在此,RPN 默认选择 256 个 Anchors 进行损失的计算,其中最多不超过 128 个正样本。如果正样本数量超过了限定值,则随机选取 128 个正样本。当然,这里的 256 与 128 都可以根据实际情况进行调整,而不是固定死的
(4) 求解回归偏移真值
- 回归部分的偏移量真值需要利用 Anchor 与它对应最大 IoU 的标签求解得到,公式为:
损失函数设计
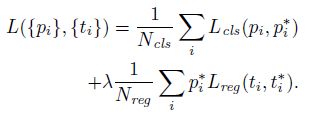
- 分类损失:
∑ i L c l s ( p i , p i ∗ ) \sum_iL_{cls}(p_i,p_i^*) i∑Lcls(pi,pi∗)其中, ∑ i L c l s ( p i , p i ∗ ) \sum_iL_{cls}(p_i,p_i^*) ∑iLcls(pi,pi∗) 代表了 256 个筛选出的 Anchors 的分类损失, p i p_i pi 为每一个 Anchor 的类别真值, p i ∗ p^*_i pi∗ 为每一个 Anchor 的预测类别, L c l s L_{cls} Lcls 使用的是对数损失 (二分类) - 回归损失:
∑ i p i ∗ L r e g ( t i , t i ∗ ) \sum_ip_i^*L_{reg}(t_i,t_i^*) i∑pi∗Lreg(ti,ti∗)其中, p i ∗ p_i^* pi∗ 用于只累积 “前景” Anchor 的回归损失, t i t_i ti 为记录一个 Anchor 的 4 个位置参数的向量, t i ∗ t_i^* ti∗ 为记录一个正例 Anchor 对应 label 的 4 个位置参数的向量, L r e g L_{reg} Lreg 为 smooth L 1 \text { smooth }_{L_1} smooth L1 损失函数,具体公式为:
L r e g ( t i , t i ∗ ) = ∑ i ∈ { x , y , w , h } smooth L 1 ( t i − t i ∗ ) smooth L 1 ( x ) = { 0.5 x 2 if ∣ x ∣ < 1 ∣ x ∣ − 0.5 otherwise \begin{aligned} &L_{r e g}\left(t_{i}, t_{i}^{*}\right)=\sum_{i \in \{x, y, w, h\}} \text { smooth }_{L_1}\left(t_{i}-t_{i}^{*}\right) \\ &\text { smooth }_{L_1}(x)=\left\{\begin{array}{cc} 0.5 x^{2} & \text { if }|x|<1 \\ |x|-0.5 & \text { otherwise } \end{array}\right. \end{aligned} Lreg(ti,ti∗)=i∈{x,y,w,h}∑ smooth L1(ti−ti∗) smooth L1(x)={0.5x2∣x∣−0.5 if ∣x∣<1 otherwise 可以看到, smooth L 1 \text { smooth }_{L_1} smooth L1 函数结合了 1 阶与 2 阶损失函数,原因在于,当预测偏移量与真值差距较大时,使用 2 阶函数时导数太大,模型容易发散而不容易收敛,因此在大于 1 时采用了导数较小的 1 阶损失函数 - 分类、回归损失的归一化与加权:
- 分类损失和回归损失分别使用 1 N c l s \frac{1}{N_{cls}} Ncls1 和 1 N r e g \frac{1}{N_{reg}} Nreg1 进行归一化,其中 N c l s N_{cls} Ncls 为 256 (i.e. 筛选出的 Anchor 数), N r e g N_{reg} Nreg 为 Anchor locations 的数量,也就是 feature map 的大小 (在 paper 中,feature map 大小为 60 × 40 60\times40 60×40,因此 N r e g N_{reg} Nreg 取 2400)
- λ \lambda λ 为一个平衡因子,在 paper 中默认取 10,使得分类损失和回归损失的权重大致相等
- 论文中也用实验证明,模型对 λ \lambda λ 的取值是不太敏感的;同时,上述的归一化过程实际上并不是必须的,可以被进一步简化
NMS 生成 Proposal
- 完成了损失的计算,RPN 的另一个功能就是区域生成,即生成较好的 Proposal,以供下一个阶段进行细分类与回归
NMS 生成 Proposal
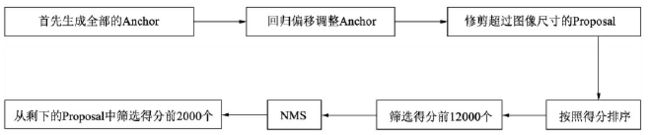
- 首先生成大小固定的全部 Anchors,然后将网络中得到的回归偏移作用到 Anchor 上使 Anchor 更加贴近于真值,并修剪超出图像尺寸的 Proposal,得到最初的建议区域。在这之后,按照分类网络输出的得分对 Anchor 排序,保留前 12000 个得分高的 Anchors。由于一个物体可能会有多个 Anchors 重叠对应,因此再应用非极大值抑制 (NMS) 将重叠的框去掉,最后在剩余的 Proposal 中再次根据 RPN 的预测得分选择前 2000 个,作为最终的 Proposal,输出到下一个阶段
筛选 Proposal 得到 RoI
- 在训练时,上一步生成的 Proposal 数量为 2000 个,其中仍然有很多背景框,真正包含物体的仍占少数,因此完全可以针对 Proposal 进行再一步筛选,过程与 RPN 中筛选 Anchor 的过程类似,首先计算 Proposal 与所有的物体标签的 IoU 矩阵,然后根据 IoU 矩阵的值来筛选出符合条件的正负样本。筛选标准如下:
- (1) 对于任何一个 Proposal,其与所有标签的最大 IoU 如果大于等于 0.5,则视为正样本
- (2) 对于任何一个 Proposal,其与所有标签的最大 IoU 如果大于等于 0 且小于 0.5,则视为负样本
- 经过上述标准的筛选,选出的正、负样本数量不一,在此设定筛选出的正、负样本的总数为 256 个,其中正样本的数量为 p p p 个。为了控制正、负样本的比例基本满足 1 : 3 1:3 1:3,在此正样本数量 p p p 不超过 64,如果超过了 64 则从正样本中随机选取 64 个。剩余的数量 256 − p 256-p 256−p 为负样本的数量,如果超过了 256 − p 256-p 256−p 则从负样本中随机选取 256 − p 256-p 256−p 个
- 这一步有 3 个作用:
- 筛选出了更贴近真实物体的 RoI,使送入到后续网络的物体正、负样本更均衡,避免了负样本过多,正样本过少的情况
- 减少了送入后续全连接网络的数量,有效减少了计算量
- 筛选 Proposal 得到 RoI 的过程中,由于使用了标签来筛选,因此也为每一个 RoI 赋予了正、负样本的标签,同时可以在此求得 RoI 变换到对应标签的偏移量,这样就求得了 RCNN 部分的真值
RoI Pooling 层
Why RoI Pooling?
- RPN 最终得到了 256 个 RoI,以及每一个 RoI 对应的类别与偏移量真值,为了计算损失,还需要计算每一个 RoI 的预测量。Backbone 网络已经提供了整张图像的 feature map,因此自然联想到可以利用此 feature map,将每一个 RoI 区域对应的特征提取出来,然后接入一个全连接网络,分别预测其 RoI 的分类与偏移量
- 然而,由于 RoI 是由各种大小宽高不同的 Anchors 经过偏移修正、筛选等过程生成的,因此其大小不一且带有浮点数,然而后续相连的全连接网络要求输入特征大小维度固定,这就需要有一个模块,能够把各种维度不同的 RoI 变换到维度相同的特征,以满足后续全连接网络的要求,于是 RoI Pooling 就产生了
假设当前 RoI 大小为 332 × 332 332×332 332×332,使用 VGGNet 的全连接层,其所需的特征向量维度为 512 × 7 × 7 512×7×7 512×7×7,由于目前的特征图通道数为 512,Pooling 的过程就是如何获得 7 × 7 7×7 7×7 大小区域的特征
RoI Pooling
- 对 RoI 进行池化的思想在 SPPNet 中就已经出现了,只不过在 Fast RCNN 中提出的 RoI Pooling 算法利用最近邻差值算法将池化过程进行了简化,而在随后的 Mask RCNN 中进一步提出了 RoI Align 的算法,利用双线性插值,进一步提升了算法精度
RoI Pooling

- (1) 利用 feature map 提取出 RoI 的特征:假设当前的 RoI 大小为 332 × 332 332×332 332×332,为了得到这个 RoI 的特征图,首先需要将该区域映射到全图的特征图上,由于下采样率为 16,因此该区域在特征图上的坐标直接除以 16 并取整,对应的大小为 332 / 16 = 20.75 332/16=20.75 332/16=20.75。在此,RoI Pooling 的做法是直接将浮点数量化为整数,取整为 20 × 20 20×20 20×20,也就得到了该 RoI 的特征
- (2) 将 RoI 特征池化为全连接层要求的输入维度:也就是将该 20 × 20 20×20 20×20 区域处理为 7 × 7 7×7 7×7 的特征,然而 20 / 7 ≈ 2.857 20/7≈2.857 20/7≈2.857,再次出现浮点数,RoI Pooling 的做法是再次量化取整,将 2.857 取整为 2,然后以 2 为步长从左上角开始选取出 7 × 7 7×7 7×7 的区域,这样每个小方格在特征图上都对应 2 × 2 2×2 2×2 的大小。最后,取每个小方格内的最大特征值,作为这个小方格的输出,最终实现了 7 × 7 7×7 7×7 的输出,也完成了池化的过程。从实现过程中可以看到,RoI 本来对应于 20.75 × 20.75 20.75×20.75 20.75×20.75 的特征图区域,最后只取了 14×14 的区域,因此 RoI Pooling 算法虽然简单,但量化取整带来的偏差势必会影响网络,尤其是回归物体位置的准确率
疑问:如果 RoI 过小,对应特征图小于 7 × 7 7\times7 7×7 怎么办?这个暂时不清楚具体是怎么做的,但肯定可以用最近邻差值 / 双线性插值 / 池化进行上采样
RoI Align

- (1) 利用 feature map 提取出 RoI 的特征 (不做量化):RoI Align 依然将 RoI 对应到特征图上,但坐标与大小都保留着浮点数,大小为 20.75 × 20.75 20.75×20.75 20.75×20.75,不做量化
- (2) 使用双线性插值最大可能地保留原始区域的特征:将特征图上的 20.75 × 20.75 20.75×20.75 20.75×20.75 大小均匀分成 7 × 7 7×7 7×7 方格的大小,中间的点依然保留浮点数。在此选择其中 2 × 2 2×2 2×2 方格为例 (见下图),在每一个小方格内的特定位置选取 4 个采样点进行特征采样,然后对这 4 个点的值选择最大值,作为这个方格最终的特征。对于黑点的位置,可以将小方格平均分成 2 × 2 2×2 2×2 的 4 份,然后这 4 份更小单元的中心点可以作为小黑点的位置。至于如何计算这 4 个小黑点的值,RoI Align 使用了双线性插值的方法。小黑点周围会有特征图上的 4 个特征点,利用这 4 个特征点双线性插值出该黑点的值

- 由于 Align 算法最大可能地保留了原始区域的特征,因此 Align 算法对检测性能有显著的提升,尤其是对于受 RoI Pooling 影响大的情形,如本身特征区域较小的小物体,改善更为明显
全连接 RCNN 模块
- 在经过 RoI Pooling 层之后,特征被池化到了固定的维度,因此接下来可以利用全连接网络进行分类与回归预测量的计算。在训练阶段,最后需要计算预测量与真值的损失并反传优化,而在前向测试阶段,可以直接将预测量加到 RoI 上,并输出预测量
RCNN 全连接网络

- 由 RPN 得到的 256 个 RoI 经过池化之后得到固定维度为 512 × 7 × 7 512×7×7 512×7×7 的特征,在此首先将这三个维度延展为一维以便输入全连接网络。接下来利用 VGGNet 的两个全连接层,得到长度为 4096 的 256 个 RoI 特征。为了输出类别与回归的预测,将上述特征分别接入分类与回归的全连接网络。在此默认为 21 类物体,因此分类网络输出维度为 21,回归网络则输出每一个类别下的 4 个位置偏移量,因此输出维度为 84
- 值得注意的是,虽然是 256 个 RoI 放到了一起计算,但相互之间是独立的,并没有使用到共享特征,因此造成了重复计算,这也是 Faster RCNN 的一个缺点
损失函数设计
- RCNN 部分的损失函数计算方法与 RPN 部分相同,只不过在此为 21 个类别的分类,而 RPN 部分则是二分类,需要注意回归时至多有 64 个正样本参与回归计算,负样本不参与回归计算
Faster RCNN 的改进算法
审视 Faster RCNN
Faster RCNN 之所以生命力如此强大,应用如此广泛,离不开以下几个特点:
- (1) 性能优越:Faster RCNN 通过两阶网络与 RPN,实现了精度较高的物体检测性能
- (2) 两阶网络:相比起其他一阶网络,两阶更为精准,尤其是针对高精度、多尺度以及小物体问题上,两阶网络优势更为明显
- (3) 通用性与鲁棒性:Faster RCNN 在多个数据集及物体任务上效果都很好,对于个人的数据集,往往 Fine-tune 后就能达到较好的效果
当然,原始的 Faster RCNN 也存在一些缺点,而这些缺点也恰好成为了后续学者优化改进的方向,总体来看,可以从以下 6 个方面考虑:
- (1) 卷积提取网络:无论是 VGGNet 还是 ResNet,其特征图仅仅是单层的,分辨率通常也较小,这些都不利于小物体及多尺度的物体检测,因此多层融合的特征图、增大特征图的分辨率等都是可以优化的方向
- (2) NMS:在 RPN 产生 Proposal 时为了避免重叠的框,使用了 NMS,并以分类得分为筛选标准。但 NMS 本身的过滤对于遮挡物体不是特别友好,本身属于两个物体的 Proposal 有可能因为 NMS 而过滤为 1 个,造成漏检,因此改进优化 NMS 是可以带来检测性能提升的
- (3) RoI Pooling:Faster RCNN 的原始 RoI Pooling 两次取整带来了精度的损失,因此后续 Mask RCNN 针对此 Pooling 进行了改进,提升了定位的精度
- (4) 全连接:原始 Faster RCNN 最后使用全连接网络,这部分全连接网络占据了网络的大部分参数,并且 RoI Pooling 后每一个 RoI 都要经过一遍全连接网络,没有共享计算,而如今全卷积网络是一个发展趋势,如何取代这部分全连接网络,实现更轻量的网络是需要研究的方向
- (5) 正负样本:在 RPN 及 RCNN 部分,都是通过超参数来限制正、负样本的数量,以保证正、负样本的均衡。而对于不同任务与数据,这种正、负样本均衡方法是否都是最有效的,也是一个研究的方向
- (6) 两阶网络:Faster RCNN 的 RPN 与 RCNN 两个阶段分工明确,带来了精度的提升,但速度相对较慢,实际实现上还没有达到实时。因此,网络阶数也是一个值得探讨的问题,如单阶是否可以使网络的速度更快,更多阶的网络是否可以进一步提升网络的精度等
特征融合: HyperNet
- 卷积神经网络的特点是,深层的特征体现了强语义特征,有利于进行分类与识别,而浅层的特征分辨率高,有利于进行目标的定位。原始的 Faster RCNN 方法仅仅利用了单层的 feature map (例如 VGGNet 的 conv5-3),对于小尺度目标的检测较差,同时高 IoU 阈值时,边框定位的精度也不高
- HyperNet 认为单独一个 feature map 层的特征不足以覆盖 RoI 的全部特性,因此提出了一个精心设计的网络结构,融合了浅、中、深 3 个层次的特征,取长补短,在处理好区域生成的同时,实现了较好的物体检测效果
融合多层特征
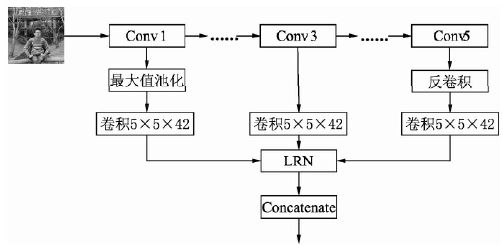
- HyperNet 以 VGGNet 作为基础网络,分别从第 1、3、5 个卷积组后提取出特征,这 3 个特征分别对应着浅层、中层与深层的信息。然后,对浅层的特征进行最大值池化 (下采样),对深层的特征进行反卷积 (上采样),使得二者的分辨率都为原图大小的 1 / 4 1/4 1/4,与中层的分辨率相同,方便进行融合。得到 3 个特征图后,再接一个 5 × 5 5×5 5×5 的卷积以减少特征通道数,得到通道数为 42 的特征
- 在三层的特征融合前,需要先经过一个 LRN (Local Response Normalization) 处理,LRN 层借鉴了神经生物学中的侧抑制概念,即激活的神经元抑制周围的神经元,在此的作用是增加泛化能力,做平滑处理 (LRN 替换为 BN 会不会更好?)
- 最后将特征沿着通道数维度拼接到一起。3 个通道数为 42 的特征拼接一起后形成通道数为 126 的特征,作为最终输出
候选区域生成: 在 RPN 网络中使用 RoI Pooling
- HyperNet 实现了一个轻量化网络来实现候选区域生成。具体方法是,首先在特征图上生成 3 万个不同大小与宽高的候选框,经过 RoI Pooling 获得候选框的特征,再接卷积及相应的分类回归网络,进而可以得到预测值,结合标签就可以筛选出合适的 Proposal。可以看出,这里的实现方法与 Faster RCNN 的 RPN 方法很相似,只不过先进行了 RoI Pooling,再选择候选区域,这种提前使用 RoI Pooling 的方法使得 HyperNet 的 Proposal 质量很高,前 100 个 Proposal 就可以实现 97% 的召回率. 但也由于提前使用了 RoI Pooling,导致众多候选框特征都要经过一遍此 Pooling 层,计算量较大,为了加速,可以在 Pooling 前使用一个 3 × 3 3×3 3×3 卷积降低通道数为 4,这种方法在大幅度降低计算量的前提下,基本没有精度的损失
- HyperNet 后续的网络与 Faster RCNN 也基本相同,接入全连接网络完成最后的分类与回归。不同的地方是,HyperNet 先使用了一个卷积降低通道数,并且 Dropout 的比例从 0.5 调整到了 0.25
HyperNet 融合了多层特征的网络有如下 3 点好处:
- (1) 深层、中层、浅层的特征融合到一起,优势互补,利于提升检测精度
- (2) 特征图分辨率为 1 / 4 1/4 1/4,特征细节更丰富,利于检测小物体,同时由于特征图分辨率较大,物体的定位也更精准
- (3) 在区域生成与后续预测前计算好了特征,没有任何的冗余计算
实例分割: Mask RCNN
- paper: Mask R-CNN (ICCV 2017 best paper)
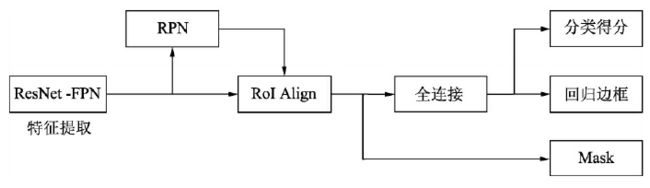
Mask RCNN 与 Faster RCNN 主要有 3 点区别:
- (1) 在基础网络中采用了较为优秀的 ResNet-FPN 结构,多层特征图有利于多尺度物体及小物体的检测。ResNet-FPN 与 FPN 类似,在 FPN 输出 P 2 P_2 P2、 P 3 P_3 P3、 P 4 P_4 P4 与 P 5 P_5 P5 4 个阶段特征图的基础上又通过对 P 5 P_5 P5 进行最大值池化得到 P 6 P_6 P6,目的是获得更大感受野的特征, P 6 P_6 P6 生成的 Proposals 仅用于 RPN 阶段的训练而不作为后续全连接层的输入。在获得 5 个不同尺度特征图之后,Mask RCNN 按照如下公式将大的 RoI 对应到高语义的特征图中,小的 RoI 对应到高分辨率的特征图中:
 其中,224 为 ImageNet 预训练图片的大小, k 0 k_0 k0 默认值为 4,表示大小为 224 × 224 224×224 224×224 的 RoI 应该对应的层级为 4
其中,224 为 ImageNet 预训练图片的大小, k 0 k_0 k0 默认值为 4,表示大小为 224 × 224 224×224 224×224 的 RoI 应该对应的层级为 4 - (2) 提出了 RoI Align 方法来替代 RoI Pooling,原因是 RoI Pooling 的取整做法损失了一些精度,而这对于分割任务来说较为致命
- (3) 得到感兴趣区域的特征后,在原来分类与回归的基础上,增加了一个 Mask 分支来进行图像分割,预测每一个像素的类别:假设物体检测任务的类别是 21 类,在具体实现时,Mask RCNN 为了不丢失空间信息,采用了 FCN (Fully Convolutional Network) 的网络结构,利用卷积与反卷积构建端到端的网络,该网络输入为 RoI Align 得到的 RoI 特征,输出为 21 × m × m 21×m×m 21×m×m 的特征图,该特征图可以看作由 21 个 m × m m\times m m×m 的 mask 组成,第 i i i 个 mask 对应了特征图上所有点属于类别 i i i 的概率。由于 RoI Align 抽取出的 RoI 特征在空间上与 RoI 对齐得比较好,因此可以将特征图上 m × m m\times m m×m 个点一一映射到原图中,进而得到整个 RoI 内所有像素点的类别概率,完成对 RoI 的实例分割。Mask 分支在计算损失函数时,是对 m × m m\times m m×m 特征图上的每一个点应用 Sigmoid 函数,送到交叉熵损失中,最后取所有像素损失的平均值,同时注意,如果当前 RoI 的标签类别是 5,则只有第 5 个 mask 参与计算,其他的类别并不参与计算,这种方法可以有效地避免类间竞争,将分割任务和分类任务解耦,把分类的任务交给更为专业的分类分支去处理,实验证明这种方法比使用 Softmax 进行多分类的方法效果更好
全卷积网络: R-FCN (Region-based Fully Convolutional Networks)
- paper: R-FCN: Object Detection via Region-based Fully Convolutional Networks
Motivation
- Faster RCNN 在 RoI Pooling 后采用了全连接网络来得到分类与回归的预测,这部分全连接网络占据了整个网络结构的大部分参数,而目前越来越多的全卷积网络证明了不使用全连接网络效果会更好,同时还可以适应各种输入尺度的图片。一个很自然的想法就是去掉 RoI Pooling 后的全连接,直接连接到分类与回归的网络中,但通过实验发现这种方法检测的效果很差,其中一个原因就是基础的卷积网络是针对分类设计的,具有平移不变性,对位置不敏感,而物体检测则对位置敏感
- 针对上述 “痛点”,R-FCN 利用位置敏感得分图 (position-sensitive score maps) 实现了对位置的敏感,并且采用了全卷积网络,大大减少了网络的参数量
R-FCN 网络结构
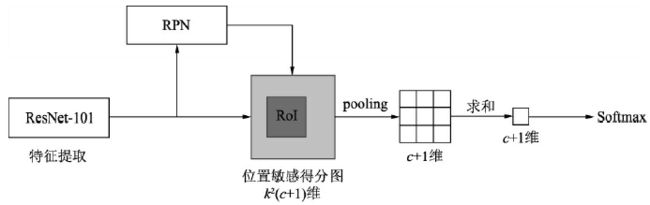
- R-FCN 采用了 ResNet-101 作为 Backbone,并在原始的 100 个卷积层后增加了一个 1 × 1 1×1 1×1 卷积将通道数降低为 1024。此外,为了增大后续特征图的尺寸,R-FCN 将 ResNet-101 的下采样率从 32 降到了 16。具体做法是,在第 5 个卷积组里将卷积的步长从 2 变为 1,同时在这个阶段的卷积使用空洞数为 2 的空洞卷积以扩大感受野 (降低步长增加空洞卷积是一种常用的方法,可以在保持特征图尺寸的同时,增大感受野)
- Position-sensitive score maps: R-FCN 对 ResNet-101 最后输出的 w × h × 1024 w\times h\times1024 w×h×1024 的特征图进行了 1 × 1 1×1 1×1 卷积来得到位置敏感得分图,其通道数为 k 2 ( c + 1 ) k^2(c+1) k2(c+1),其中 c c c 代表物体类别,一般需要再加上背景这一类别, k k k 则代表将 RoI 划分为 k 2 k^2 k2 个区域:
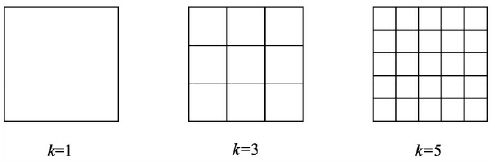 因此,位置敏感得分图按通道划分可以看作有 k 2 k^2 k2 个 w × h × ( c + 1 ) w\times h\times (c+1) w×h×(c+1) 的得分图,第 i i i 个得分图的点 ( x , y ) (x,y) (x,y) 对应的 c + 1 c+1 c+1 维向量就代表当 ( x , y ) (x,y) (x,y) 属于 RoI 的第 i i i 个区域时,该点属于各个物体类别的概率 (看到这里可能有点难理解,需要结合后面的 Position-sensitive RoI pooling 进行理解)
因此,位置敏感得分图按通道划分可以看作有 k 2 k^2 k2 个 w × h × ( c + 1 ) w\times h\times (c+1) w×h×(c+1) 的得分图,第 i i i 个得分图的点 ( x , y ) (x,y) (x,y) 对应的 c + 1 c+1 c+1 维向量就代表当 ( x , y ) (x,y) (x,y) 属于 RoI 的第 i i i 个区域时,该点属于各个物体类别的概率 (看到这里可能有点难理解,需要结合后面的 Position-sensitive RoI pooling 进行理解) - Position-sensitive RoI pooling: 现在我们已经有了位置敏感得分图。给定一个 RoI,我们也将其划分为 k 2 k^2 k2 个区域,得到每个区域在特征图上的位置。然后我们根据区域位置把第 i i i 个区域映射到到第 i i i 个得分图上,得到 w / k × h / k × ( c + 1 ) w/k\times h/k\times (c+1) w/k×h/k×(c+1) 的特征图,如前所述,该特征图就是用来表示 RoI 第 i i i 个区域包含各个物体类别的概率的, w / k × h / k w/k\times h/k w/k×h/k 特征图上的每个 c + 1 c+1 c+1 维向量都代表了该点属于各个物体类别的概率,因此我们再做 Average Pooling 得到一个 1 × 1 × ( c + 1 ) 1\times 1\times (c+1) 1×1×(c+1) 的向量,该向量就表示区域 i i i 包含各个物体的概率,最终 k 2 k^2 k2 个区域总共可以得到一个 k × k × ( c + 1 ) k\times k\times (c+1) k×k×(c+1) 的特征图,表示了该 RoI 的 k 2 k^2 k2 个区域内包含各个物体的概率 (上述过程可以由下图直观地进行表示,每个区域都是在不同的得分图上进行 pooling 的)
 接下来我们再对这个 k × k × ( c + 1 ) k\times k\times (c+1) k×k×(c+1) 的特征图进行逐通道求和,即可得到 c + 1 c+1 c+1 维的向量,它表示 RoI 包含各个物体的概率,最后进行 Softmax 即可完成这个 RoI 的分类预测
接下来我们再对这个 k × k × ( c + 1 ) k\times k\times (c+1) k×k×(c+1) 的特征图进行逐通道求和,即可得到 c + 1 c+1 c+1 维的向量,它表示 RoI 包含各个物体的概率,最后进行 Softmax 即可完成这个 RoI 的分类预测
位置敏感得分图为什么有效? 假如某个 RoI 最终分类为 i i i,那么说明该 RoI 最终输出的 k × k × ( c + 1 ) k\times k\times (c+1) k×k×(c+1) 特征图中通道 i i i 对应的 k × k k\times k k×k 特征图激活值最大,进而说明 k 2 k^2 k2 个得分图上该 RoI 各个区域对应的激活值比较大。下图的实验进一步证明了这点:

- 扩展:在这之后,R-FCN 的一作又提出了可变形卷积、可变形 RoI Pooling 和可变形位置敏感 RoI Pooling,具体可见这篇文章
级联网络: Cascade RCNN
- paper: Cascade R-CNN: Delving into High Quality Object Detection
矛盾的超参:IoI 阈值
- 在得到一个 RoI 后,Faster RCNN 通过 RoI 与标签的 IoU 值来判断该 RoI 是正样本还是负样本,默认的 IoU 阈值为 0.5,这个阈值是一个超参数,对于检测的精度有较大影响。如何选择合适的阈值是一个矛盾的问题。一方面,阈值越高,选出的 RoI 会更接近真实物体,检测器的定位会更加准确,但此时符合条件的 RoI 会变少,正、负样本会更加不均衡,容易导致训练过拟合;另一方面,阈值越低,正样本会更多,有利于模型训练,但这时误检也会增多,从而增大了分类的误差
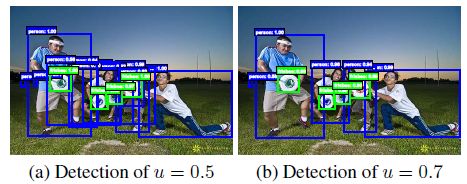
实验现象
- Cascade RCNN 的作者通过实验发现,(1) 一个检测器如果采用某个阈值界定正负样本时,那么当输入 Proposal 的 IoU 在这个阈值附近时,检测效果要比基于其他阈值时好,也就是很难让一个在指定阈值界定正、负样本的检测模型对所有 IoU 的输入 Proposal 检测效果都最佳;(2) 经过回归之后的候选框与标签之间的 IoU 会有所提升

Cascade RCNN
- 基于以上结果,Cascade RCNN 通过级联多个检测器来不断优化结果,每个检测器都基于不同的 IoU 阈值来界定正负样本。前一个检测器的输出作为后一个检测器的输入,并且检测器越靠后,IoU 的阈值越高

- 总体来看,Cascade RCNN 深入探讨了 IoU 阈值对检测器性能的影响,并且在不增加任何 tricks 的前提下,在多个数据集上都有了明显的精度提升,是一个性能优越的高精度物体检测器
扩展: Pytorch 官方 FasterRCNN 代码
- 捋一捋 pytorch 官方 FasterRCNN 代码
参考文献
- paper: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- 《深度学习之 PyTorch 物体检测实战》
- Faster-RCNN 中 Anchor 锚框生成
- 详解 R-FCN