<<视觉Transformer>>2020:Visual Transformers: Token-based Image Representation and Processing for CV

本专栏只研究vision Transformer的原理,对实验不做过多研究。
目录
摘要:
一、介绍
二、相关工作
三、Visual Transformer
3.1. Tokenizer
3.1.1 Filter-based Tokenizer
3.1.2 Recurrent Tokenizer
3.2. Transformer
3.3. Projector
四、Using Visual Transformers in vision models
五、实验
六、结论
摘要:
计算机视觉通过将图像表示为均匀排列的像素阵列和卷积高度局部化的特性取得了显著的成功,然而,卷积是同等地对待所有图像像素,而不考虑其重要性;建模所有图像的所有概念,而不管图像内容如何,况且很难把空间上遥远的概念联系起来。在这项工作中,我们通过将图像表示为语义视觉tokens和使用transformers密集建模tokens关系,我们的visual transformer在语义tokens空间中操作,根据上下文处理不同的图像部分。这与需要数量级计算量的像素空间transformers形成了鲜明对比。使用一种先进的训练方法,我们的VTs显著优于其他的卷积的方法,在使用更少的FLOPs和参数的情况下,提高了ResNet在ImageNet上的top-1精度4.6到7分。在LIP和COCO-stuff上进行语义分割,基于VT的特征金字塔网络(FPN)可以提高0.35个mIoU,同时将FPN模块的FLOPs降低6.5倍。
一、介绍
在计算机视觉中,视觉信息以像素阵列的形式被捕获,然后对这些像素阵列进行卷积处理,卷积是计算机视觉的深度学习算子,存在一些关键的挑战:
1)Not all pixels are created equal 图像分类模型应该优先考虑前景对象而不是背景,分割模型应该优先考虑行人,而不是不成比例的大片天空、道路、植被等。然而,卷积是统一处理所有的图像块,而不考虑其重要性,这导致了计算和表示的空间效率低下。
2)Not all images have all concepts 所有自然图像中都存在像角落和边缘这样的低阶特征,因此对所有图像应用低阶卷积滤波器是合适的。然而,由于特定图像中存在耳朵形状等高级特征,因此对所有图像应用高级滤波器的计算效率较低。例如,狗的特征可能不会出现在花卉、车辆、水生动物等图像中,这将导致很少使用的、不适用的过滤器花费大量的计算。
3)Convolutions struggle to relate spatially-distant concepts 每个卷积过滤器都被限制在一个小区域上操作,但语义概念之间的长期交互至关重要。为了将空间距离概念联系起来,以前的方法增加了卷积核大小,增加了模型深度,或者采用了新的操作,如扩展卷积、全局池化和非局部注意层。然而,通过在像素卷积范式中工作,这些方法最多只能缓解问题,通过增加模型和计算复杂性来弥补卷积的缺点。
为了克服上述挑战,我们解决了根本原因,即像素卷积范式,并引入了visual Transformer(VT)(图1),这是一种表示和处理图像中的高级概念的新范式。我们的直觉是,一个带有几个单词(或视觉tokens)的句子就足以描述图像中的高级概念。我们使用空间注意力将特征映射转换为一组紧凑的语义tokens,然后,我们将这些tokens提供给Transformer,用于捕获tokens交互。计算得到的视觉tokens可以直接用于图像级预测任务(如分类),或者在像素级预测任务(如分割)中重新映射到特征图,与卷积不同,VT可以更好地处理以上三个挑战:1)通过关注重要区域来明智地分配计算,而不是平等地对待所有像素;2)将语义概念编码到与图像相关的几个视觉符号中,而不是对所有图像中的所有概念进行建模:3)通过token空间的自我注意将空间距离概念联系起来。
二、相关工作
Transformers in vision models 最近一个值得关注的相关趋势是在视觉模型中采用Transformer。例如ViT,它将图像按照16×16的patch分割,并将这些patch(即token)输入到一个标准Transformer中,虽然很简单,但这需要Transformer学习密集的、可重复的模式(如纹理),而卷积网络学习这种信息效率要高得多。Transformer这种简单性带来了极高的计算成本:ViT需要长达7个GPU年和3亿个JFT数据集图像才能超越卷积版本。相比之下,我们利用了每个操作各自的优势,使用卷积来提取低级特征,使用Transformer来关联高级概念。我们进一步利用空间注意力来关注重要的区域,而不是平等地对待每个图像块。尽管数据和训练时间少了几个数量级,但这仍然产生了强大的性能。另一项相关工作DETR采用Transformer简化了目标检测训练中手工制作的锚点匹配程序。
Graph convolutions in vision models 我们的VT只使用了16个视觉token,并获得了更高的准确性。此外,虽然[26,6,47]中的模块只能添加到一个经过预训练的网络中,以增强卷积,但VTs可以替换卷积层来保存FLOPs和参数,并支持从头开始训练。
Attention in vision models 除了用于Transformers外,attention还以不同的形式广泛应用于计算机视觉模型中。注意力首先被用来调制特征映射:从输入中计算出注意力权重,然后乘以特征映射,后来的研究将这种“调制”解释为一种使卷积具有空间适应性和内容感知的方式。然而,自注意力的计算复杂度随像素数的增加呈二次型增长,利用自注意力增强卷积,通过使用较小的通道大小进行注意力来降低计算成本。还有工作限制自注意的感受野,并以卷积的方式使用它。我们的工作与上述所有工作不同,因为我们提出了一种新的token-transformer范式,以取代低效率的像素卷积范式,并实现卓越的性能。
Efficient vision models 近年来,许多研究工作都集中在构建视觉模型,以以更低的计算成本实现更好的性能。最近,人们使用神经结构搜索来优化由现有卷积算子组成的搜索空间内的网络性能。所有的努力都是为了使通用的卷积神经网络的计算效率更高,相比之下,我们提出了一种新的构建模块,它自然地消除了像素卷积范式中的冗余计算。
三、Visual Transformer
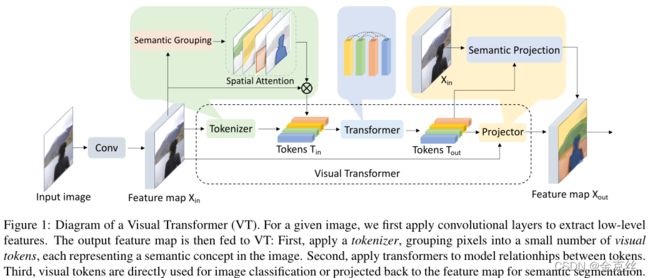
我们在图1中说明了基于visual Transformer (VT)模型的总体示意图。首先用几个卷积块对输入图像进行处理,然后将输出的特征图提供给vt。我们的见解是利用卷积和VTs的优势:(1)在网络早期,使用卷积学习密集分布的、低层次的模式;(2)在网络后期,使用VTs学习和关联稀疏分布的、高阶语义概念。在网络的最后,对图像级预测任务使用视觉tokens,对像素级预测任务使用增强的特征图。
VT模块包括三个步骤:首先,将像素分组成语义概念,生成一组紧凑的视觉tokens。其次,为了建模语义概念之间的关系,将transformer应用于这些视觉tokens。第三,将这些视觉tokens投射回像素空间以获得增强特征图。以前的方法使用数百个语义概念(称为“节点”),而我们的VT只使用了16个视觉tokens来实现卓越的性能。
3.1. Tokenizer
我们的直觉是,一幅图像可以由几个单词或视觉符号概括出来。这与使用数百个滤波器的卷积和使用数百个“潜在节点”来检测所有可能的概念而不管图像内容的卷积形成了对比。为了利用这种直觉,我们引入了tokenizer模块来将特征映射转换为紧凑的视觉token集。形式上,我们表示输入特征图![]() 和视觉token
和视觉token![]() ,L远小于HW。
,L远小于HW。
3.1.1 Filter-based Tokenizer
对于特征图X,我们使用逐点卷积将每个像素![]() 映射L组。然后,在每个组内,我们对像素进行空间池化以获得tokens T:
映射L组。然后,在每个组内,我们对像素进行空间池化以获得tokens T:

在这里,![]() ,
, ![]() 将这些激活转化为空间注意力。最后,A与X相乘,在X中计算像素的加权平均来获得L个visual tokens。
将这些激活转化为空间注意力。最后,A与X相乘,在X中计算像素的加权平均来获得L个visual tokens。

然而,许多高级语义概念是稀疏的,可能每个概念只出现在少数图像中。因此,通过一次性对所有这些高级概念进行建模,可能会浪费计算。我们称其为“基于滤波器”的tokenizer,,因为它使用卷积tokenizer提取视觉tokens。
3.1.2 Recurrent Tokenizer
为了弥补基于滤波器的tokenizers的局限性,我们提出了一种依赖于前一层视觉tokens的加权循环tokenizers。直觉是让前一层的tokens指导当前层的新tokens的提取,当前tokens的计算依赖于以前的tokens:

其中![]() ,通过这种方式,VT可以通过以前处理过的概念为条件,逐步地细化视觉tokens。我们应用Recurrent Tokenizer从第二个vt开始,因为它需要来自之前的VT的tokens。
,通过这种方式,VT可以通过以前处理过的概念为条件,逐步地细化视觉tokens。我们应用Recurrent Tokenizer从第二个vt开始,因为它需要来自之前的VT的tokens。

3.2. Transformer
在token化之后,我们需要对这些视觉tokens之间的交互进行建模。我们采用transformers,支持具有可变含义的视觉tokens,用更少的tokens覆盖更多可能的概念。我们采用了一个标准的transformers,但有一些细微的变化:

其中![]() 为视觉tokens,在transformers中,token之间的权值是与输入相关的,并作为一个key query乘积计算:
为视觉tokens,在transformers中,token之间的权值是与输入相关的,并作为一个key query乘积计算:![]() ,这使得我们只需使用16个视觉tokens,自注意力后,再使用非线性和两个点卷积,其中
,这使得我们只需使用16个视觉tokens,自注意力后,再使用非线性和两个点卷积,其中![]() ,σ(·)为ReLU函数。
,σ(·)为ReLU函数。
3.3. Projector
许多视觉任务需要像素级的细节,但这些细节没有保存在视觉token中。因此,我们将transformer的输出与特征图融合,将特征图的像素阵列表示细化为:
![]()
其中,![]() 为输入和输出特征图,
为输入和输出特征图,![]() 是从输入特征图Xin计算得到的query,
是从输入特征图Xin计算得到的query,![]() 是从视觉token中得到的像素要求的信息,
是从视觉token中得到的像素要求的信息,![]() 是从token T计算得到的key,
是从token T计算得到的key,![]() 代表第一个token编码的信息。key-query乘积决定如何将编码在视觉tokens中的信息投影到原始的特征图中,
代表第一个token编码的信息。key-query乘积决定如何将编码在视觉tokens中的信息投影到原始的特征图中,![]() 用于计算query和key的可学习权值。
用于计算query和key的可学习权值。
四、Using Visual Transformers in vision models
Image classification model 对于图像分类,我们遵循之前的工作,使用从ResNet继承的骨干来构建我们的网络。基于ResNet-{18, 34, 50, 101},通过用VT模块替换卷积的最后阶段,我们构建了相应的visual-transformer-ResNets (VT- resnets)。ResNet-{18, 34, 50, 101}的最后一个阶段分别包含2个basic blocks,3个basic blocks,3个bottleneck blocks,3个bottleneck blocks。我们用相同数量的VT模块(2,3,3,3)替换它们。在第4个stage结束时(第5个stage的max pooling之前),ResNet-{18,34}生成形状为14^2×256的特征图,ResNet-{50,101}生成形状为14^2×1024的特征图。对于ResNet-{18, 34, 50, 101},我们设置VT的特征图通道大小为256,256,1024,1024。我们为所有模型采用16个通道大小为1024的视觉tokens。在网络的最后,我们向分类头输出16个视觉tokens,分类头对tokens应用平均池化,并使用一个全连接层来预测概率。

Semantic segmentation 我们展示了使用VTs进行语义分割可以解决像素卷积范式的几个挑战。首先,卷积的计算复杂度随着图像分辨率的增加而增加,其次,卷积难以捕捉像素之间的长期的关系,另一方面,VTs不管图像分辨率如何,都只对少量的视觉tokens进行操作,由于它在tokens空间中建模概念交互,因此它绕过了像素阵列的“长期”挑战。为了验证我们的假设,我们使用FPN作为基线,并使用VTs改进网络。fpn以ResNet为骨干,从不同阶段提取不同分辨率的特征图,然后将这些特征图以自顶向下的方式融合到特征金字塔网络中,生成一个多尺度、保留细节、语义丰富的特征图用于分割(图4左)。FPN的计算成本很高,因为它严重依赖于在大通道尺寸的高分辨率特征图上运行的空间卷积。我们使用VTs代替FPN中的卷积,将新模块命名为VT-FPN(图4右)。从每个分辨率的特征图中,VT-FPN提取8个通道大小为1024的视觉tokens,视觉tokens被组合并输入到一个Transformer中,以计算跨分辨率的视觉tokens之间的交互。然后将输出tokens投影回原始特征映射,然后使用原始特征映射执行像素级预测。
五、实验
实验部分请看原论文。
六、结论
计算机视觉中的惯例是将图像表示为像素阵列,并应用深度学习算子卷积。我们提出了视觉Transformer(VTs),作为一种新的计算机视觉范式的标志,它可以更有效地学习和关联稀疏分布的高级概念,与像素数组不同,VTs只是使用视觉tokens在图像中表示高级概念。VTs没有使用卷积,而是使用Transformer直接关联tokens空间中的语义概念。为了评估这一想法,我们用VTs替换了卷积模块,在任务和数据集之间获得了显著的准确性提高。这个范例可以进一步与本文范围之外的其他同时代的技巧结合,包括额外的训练数据和神经结构搜索。然而,我们的目标并不是展示深度学习技巧的大杂烩,而是展示像素卷积范式充满了冗余。