【2022吴恩达机器学习】神经网络week3
1.2模型评估
选取70%作为训练集,30%作为测试集。为了训练模型并对其进行评估,使用有平方误差成本的线性回归。首先通过最小化w和b的成本函数j来拟合参数。然后为了说明这个模型表现如何,计算测试集误差以及训练集误差。

训练集的平均误差是0或接近0,所以训练集的J将会很接近0;测试集里可能有没训练过的示例,那么测试集的J会很高。
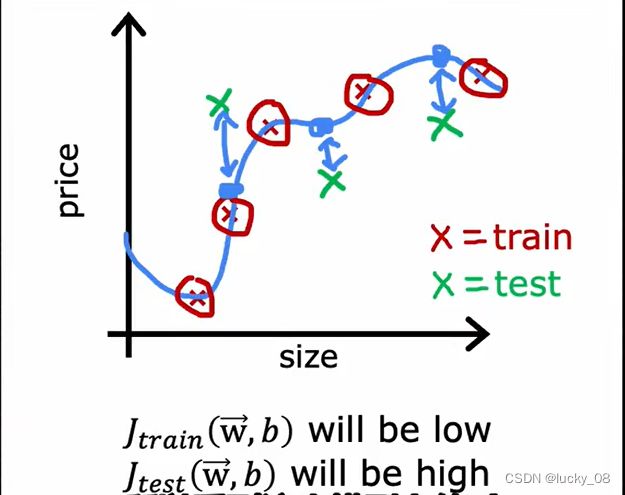
模型选择:

发现d=5时,j最低,但可能会导致过拟合。
问题是d=5时,Jtest像是泛化误差的乐观估计。
原因:此处通过不同的d也就是不同个数的w来寻找最小的Jtest来拟合模型,从本质上和前面的方法一样,因为数据集是无穷的,在我们给定的有限数据之外还有更多的数据。
训练集/交叉验证集/测试集:6:2:2
交叉验证集(验证集/开发集):用于检查不同模型的有效性和真实性
vali用于选模型(选Jcv最低的),test用于检查模型的泛化能力(机器学习算法对新鲜样本的适应能力)

因为引入validation set之前的通过test set选择d,也就是说test set参与了d的生成;引入validation set之后,training set生成w和b,validation set选择d,test set没有参与wbd的生成,此时用test set评估泛化能力就会更准。测试集要具有泛化评估能力,就不能参与参数的生成。
三个数据集一个训练,一个挑选最合适的一个模型,test用来算误差,具体来说训练集在不同的模型上拟合出每个模型的最优WB,交叉验证再从已经拟合好的模型里选择一个最好的模型,再用测试集测试这个模型的误差。
2.1正则化、方差variance和偏差bias
欠拟合会导致Jtrain很高,导致高偏差
过拟合会导致Jtrain很低,但Jcv远高于Jtrain,导致高方差
如果输入数据部分过拟合部分欠拟合,会导致高偏差和高方差
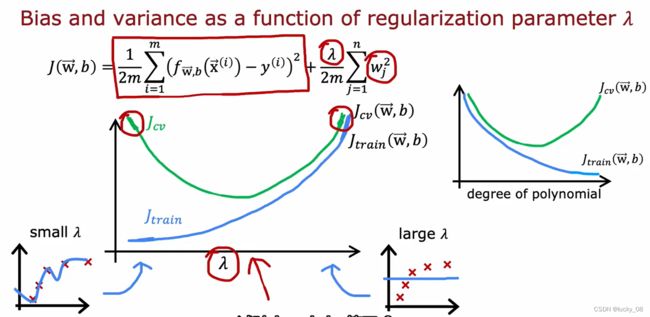
lanmda越小越过拟合,对应模型次幂越高越容易过拟合,即高方差
2.3基线baseline
基线可以是一个简单的模型的结果,也可以是通过经验决定的一个数值,通过和基线的对比,我们知道下一步该做什么,需要改善的有三种类型:
-
过拟合:train误差和baseline一样但validation误差很大,说明过拟合了
-
欠拟合:train和validation误差类似,但都比baseline大,说明欠拟合了
-
train误差比baseline大,而且validation误差比train还大,情况少见,可忽略
2.4学习曲线
前提是模型已经确定了是线性函数,当数据量比较小的时候,可以很好吻合,所以Jtrain比较小,当数据量比较大,误差就变大了。
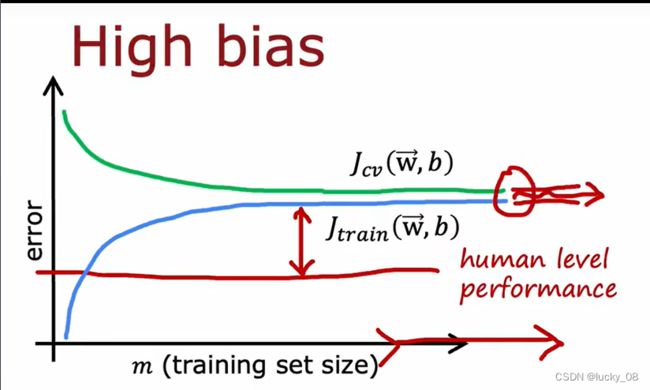
如果学习算法具有高偏差,添加更多的训练数据不会让直线拟合的更好,不会更接近基线。
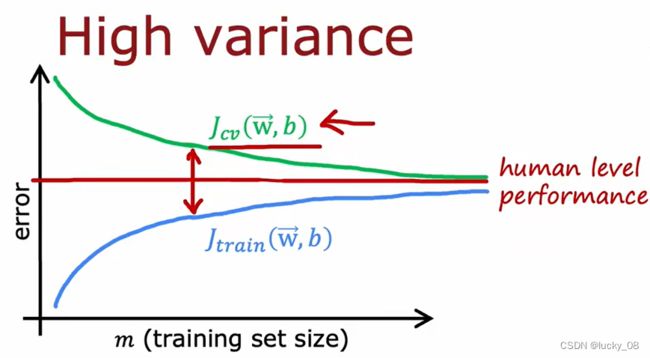
如果学习算法具有高方差,添加更多的训练数据可以帮助直线更好的拟合。
解决过拟合和欠拟合的问题:
欠拟合:如果是模型简单,就需要增加复杂度:
-
换用复杂模型,如神经网络多加几层,决策树多加几层数
-
增加特征量,如多加几个多项式的项
-
减少正则化,等于减少特征量
如果是学过头了就要调整学习策略:
-
增加学习率
-
加大训练步数
过拟合:方法和欠拟合反着来,还可以收集更多数据
3.1垃圾邮件分类实战(文本分类)
获取邮件的文本文档,将其分类为垃圾邮件或非垃圾邮件
基本流程:选择适当的架构,训练模型,诊断模型(方差、偏差或误差分析),再调整架构
方法一:训练监督学习算法
输入标签x是电子邮件,输出标签y是1/0
取垃圾邮件里出现最多的10000个单词,并用它们来定义特征x_1,x_2,...,x_10000
看邮件里有没有出现该单词,出现了就是1,否则就是0,这样我们就有一个10000维向量可以当作特征量。

改进方法:
-
收集更多垃圾邮件数据;
-
从邮件的metadata里设计更多特征量,比如发件人的邮箱地址里有没有buy这个词;
-
从邮件正文出发设计更多的特征量;
-
设计一个算法检测故意的拼写错误。
误差分析
假如有5000个交叉验证示例,如果算法错误分类了其中的1000个,那么可以随机抽取100个子集,然后把模型犯的错进行分类,然后根据分类结果决定下一步怎么做。
对随机抽取的100个数据进行手动分类,例如结果如下:
药品广告21->收集更多医药垃圾邮件数据或设计更多特征便于更好的识别这种类型的垃圾邮件
故意拼写错误3->可忽略
不常见的邮件地址7
钓鱼邮件18
把邮件写在照片里40->对图片进行文字识别后再把文字加入特征量
3.3数据增强
数据增强就是利用现有数据来造出更多数据
在做图像处理或自然语言处理时,可以合理利用数据增强来增加数据。比如做文字识别(OCR)时,一个字母可以以很多形式出现。
数据增强采用现有的训练示例并对其进行修改以创建另一个训练示例,其中一种技术是数据合成,不是修改现有的示例,而是创建全新的示例。常用于计算机视觉。
注意点:
-
不要加一些现实中不存在的数据,比如给图片加上随机噪点。
3.4迁移学习
迁移学习就是利用训练好的神经网络模型,然后在最后加一层输出层。
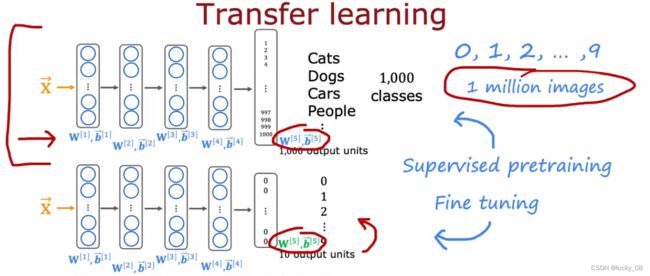
复制神经网络,输出层不能被复制,第一步为监督预训练(下载带参数的神经网络),第二步是微调。
因为改变了最后一层,所以需要从头训练
可以使用前四层的参数,除输出层之外的所有层作为参数的起点,然后运行优化算法
两个方法训练神经网络:
1.只训练输出层参数,将w1,b1,...,w4,b4作为顶部的值,使用随机梯度下降或adam优化算法仅更新w5,b5,降低成本函数。(适用小数据集)
2.训练所有参数,但前四层的参数w1,b1,...,w4,b4使用顶部训练的值进行初始化(适用大数据集)
顶部的值?不理解,求大佬解答!