基于人类视觉系统建模的仿生低层次图像处理
丘山积卑而为高,江河合水而为大。——《庄子·则阳》
好久没有写博客了,主要是最近几个月做的东西确实没什么可以拿来写博客的。我也是很着急呀!
最近这一两周看有关图像增强的论文多一些,主要是看一下有没有什么方法对视觉SLAM有所帮助,提升一下系统对于光照变换和暗光环境下的鲁棒性和定位精度。结果发现大部分都是将伽马变换、CLAHE等算法稍加改动,然后在数据集中跑一个好一点的结果,似乎创新性不大,也比较简单。当然了,这其中也有特例,前两天看了一篇论文,作者在文章当中比较了四种图像增强的方法在视觉SLAM中的表现,得出的结论是有一个算法模型对SLAM在暗光环境下定位精度的提升要好于伽马变换、L*a*b*算法和Remove blue算法。那么这究竟是什么算法模型呢?我们放下比较四种算法的文章不管,直接来看提出该算法模型的文章。文章题目是:Using Human Visual System modeling for bio-inspired low level image processing。
摘要
在一些文献中已经提出了一个在视网膜水平和V1视觉皮层处的有效处理模型。文章的主要目的是展示使用模型来开发快速有效的仿生模块来进行低层次图像处理的优点。
在视网膜层面,时空滤波保证了视频数据的精确结构(去除噪声和光照变化,静态和动态轮廓增强)。在V1皮层,进行基于频率和方向的分析。
将视网膜和V1皮层模块组合应用可以有效提升使低层次图像处理,可以用于轮廓增强、运动轮廓提取、运动分析和运动事件检测等。我们对每个模块进行了描述,并对其性能进行了评估。
视网膜模型已经被集成到了实时运行的C/C++优化程序,本文还利用衍生的计算机视觉工具介绍了该程序。
关键词:视网膜模型,V1皮层模型,低层次图像处理,实时处理,轮廓分析,运动分析,预处理,纹理和结构增强,局部自适应
1 简介
在本文中,我们提出了一个属于称为“基于生物视觉的方法”的图像处理方法。其基本思想是通过对人类视觉系统(HVS)的某些部分进行建模来复制人类视觉系统,以开发低层次图像处理模块。到目前为止,人类视觉系统中最著名的部分是视网膜和V1皮质区,这两个部分是我们研究的重点。视网膜可以被认为是一个预处理步骤,以便于高层次的分析。V1皮层可以被看做低层次的视觉信息描述。我们通过这两个工具来展示如何设计有效的低层次图像处理工具。
受生物启发的图像处理方法有很多,我们选择只关注用于图像处理的仿生模型,以使论文更易于阅读。例如,有人提出的Retinex滤波器是一种增强数字图像的方法,该方法在动态范围压缩、颜色独立于场景照明的空间分布以及在视网膜和皮质中进行的颜色/亮度渲染。这个方法基于亮度分析和它的增强。它假设颜色感知与相邻区间的特定波段的反射光强度的比率有关。因此,该算法专用于彩色应用。HVS的其他模型有用于信息编码的。这些方法通常使用高水平的信息处理,如视觉皮层建模,但不考虑发生在视网膜水平的低水平处理。
既然我们的目标是证明使用视网膜和V1皮质模型进行低水平图像处理,我们工作的初步步骤,即选择最合适的视网膜和皮质模型,如下所述。正如文献中所讨论的,标准模型的定义是一个丰富的研究领域,一些方法针对特定的图像处理问题。就视网膜模型而言,已经提出了一些具有不同精度的模型。Mead和Mahowold是通过考虑电路类比来模拟脊椎动物视网膜神经生理特性的先驱。他的模型关注视网膜结构与其功能之间的联系。然而,他的工作更多地强调视网膜的空间过滤特性,而不是与运动分析相关的时间效应。Franceschini等人也对生物视网膜的建模进行了研究,他们研究了苍蝇的视网膜结构。他制造了在同一模型上工作的机器人,并展示了它们在目标跟踪、在不稳定的风力条件下飞行以及防止碰撞方面的特性。此外,基于峰值的模型也有所研究:SpikeNet工具箱提供了一个高级模型。它模拟了视网膜神经节细胞和V1皮质层神经细胞交换的电脉冲峰。它已经展示了高水平图像分析的高速计算特性,但低水平视网膜处理还没有完全描述。其他方法也在发展,如数字视网膜。其中一些是专用于VLSI(超大规模集成)实现的方法。这些算法是生成二进制或浮点输出图像的有效并行方法,但模型仅包含视网膜中执行的所有过程的一部分。
我们工作的出发点是建立一个精确的人类视网膜模型。该模型从生物视网膜的电子电路和信号处理策略之间的类比出发,提出了一种视网膜处理的全局方法。它以米德的工作为基础,并在空间和时间特性方面得到了Herault和Beaudot的改进。它描述了在视网膜的第一层细胞中进行的不同计算(外部和内部网状层)。该模型允许精细的感知建模。这强调了视网膜的不同细胞网络特性,由于自然的并行处理特性,其实现能够实现快速计算。
考虑V1皮层,几项研究导致了各种模型的产生。Marcelja表明V1皮质中的皮质细胞对方向敏感,可以用1D Gabor滤波器建模。Daugman将这项工作扩展到2D。这种建模导致了光谱域中场景信息的简单表示。这样,2D Gabor滤波器通常用于纹理分类,或显著区域研究,以提取场景中的相关特征。因为它们在对数尺度上的特性(可靠的缩放效果处理),我们提出使用上述V1皮质区域的建模,这个模型使用对数极性Gabor滤波器(GloP)代替Gabor滤波器。
视网膜建模采用Herault模型,V1皮质建模采用Guyader模型,因此我们获得了感兴趣的视觉系统部分的模型。为了将所选择的全局HVS模型与众所周知的视觉系统模型相比较,我们介绍了这些工作和我们的工作的主要方向。Ltti和Koch模型侧重于从尺度和方向描述的角度分析视觉场景。该模型展示了在视觉皮层水平上实现的高级分析,以计算视觉注意建模的显著性映射。这些自下而上的方向和尺度描述确实是V1皮层区域的特定特征,我们也建议借助Guyader的模型来执行这些特征。Walter的工作还坚持在皮层水平进行处理,并为视觉注意力模拟添加了自上而下的交互。然而,在视网膜水平上,低水平的处理并没有得到充分考虑。类似的方法已经被提出,例如Daly的、Irccyn实验室的模型和Gipsa实验室的模型。这些模型适用于图像和视频质量评估和显著区域提取。这些精确的模型更多地坚持高水平的皮层处理(甚至在V1区域以上)用于图像描述,而不是在视网膜水平上进行低水平处理。他们使用的对比敏感度功能(CSF)不包括视网膜的某些特定特征,如局部适应和时间过滤。相比之下,我们的方法更侧重于第一个低水平视网膜处理和V1皮质,目的是证明低水平视网膜过滤特性的重要性。未来的工作将包括将我们的模型与上述方法融合,以达到更高的复杂度和更精确的低水平处理精度,并描述更广泛的图像处理应用领域。
为了展示这种人类视觉模型在高效低层图像计算中的潜力,本文提出了一套实时图像处理模块。第一组基于视网膜模型,允许提取细节和运动信息。第二组基于V1皮层区域和运动事件检测器,能够在更高的语义水平上描述视觉场景。请记住,将要公开的运动分析可被视为接近光流计算。然而,我们更多地强调了视网膜的运动能量提取、噪声抑制和局部运动信息增强的预处理方面。即使提供了关于运动能量的信息,光流的提取也是在下一步骤。
本文介绍如下:第2节简要介绍了视网膜和V1皮质过程模型。第3节描述了我们为轮廓增强、运动轮廓提取、图像方向分析和上下文感知运动事件检测开发的四个底层处理模块。第4节描述了开发的实时视网膜程序,该程序已公开,证明了我们的全局方法的合理性,包括使用HVS建模以建立高效的图像处理算法。本节还总结了以前的图像处理算法,这些算法已经通过所提供的模型实现。
2 人类视觉系统建模
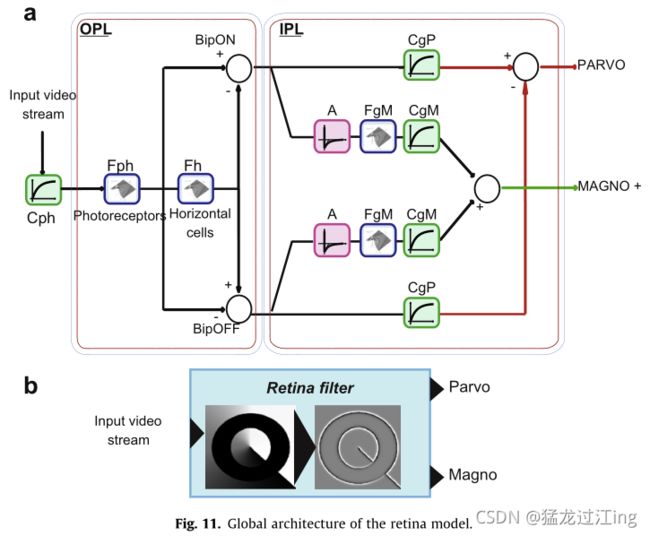
图1给出了此处考虑的HVS部件的一般概述。在视网膜中,考虑了不同细胞层的空间和时间特性,从光感受器到所谓的外丛状层(OPL)的连接细胞层,再到内丛状层(IPL)。第2.1节描述了这些处理步骤。提出的模型允许对两个信息通道进行建模。前者与细节提取相关,后者则致力于运动分析。在V1皮层区域(参见第2.2节),进行对数极域的频率和方向分析。它旨在处理视网膜模型给出的信息,以便执行低级别视觉场景属性描述。
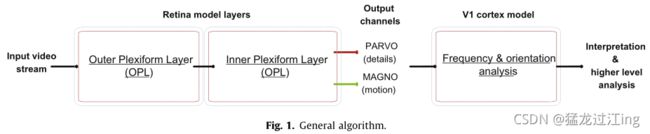
2.1. 视网膜模型
图2描述了不同的视网膜细胞:光感受器、水平细胞、双极细胞、神经节细胞和无长突细胞。光感受器负责视觉数据采集,也与图像亮度的局部对数压缩有关。视网膜细胞相互连接形成两个细胞层:外丛状层(OPL)和内丛状层(IPL)。每个层都使用特定的过滤器建模。最后,在构成视网膜输出的IPL水平上,可以识别不同的信息通道。我们在此重点介绍最著名的:用于细节提取的小细胞通道(Parvo)和用于运动信息提取的大细胞通道(Magno)。请注意,我们在这里考虑在整个视觉场景的小细胞和巨细胞处理。在人类视网膜中,由于特殊细胞的相对变异,小细胞通道在中央凹水平(中央视力)最为存在,而大细胞通道在中央凹(周边视力)之外最为重要,因为特殊细胞的相对变异。考虑图像同一区域中的两条信息对于计算机视觉来说可能是有趣的,因为细节和运动数据在同一区域中成为并行信息。
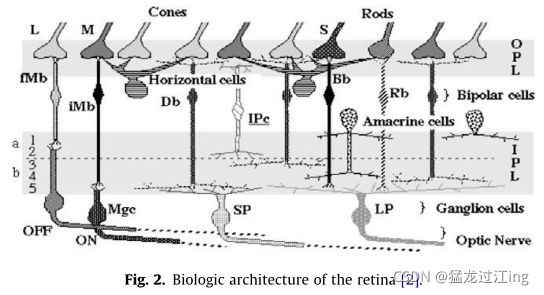
2.1.1 光感受器与光照变化去除
模型
光感受器能够根据其邻近区域的亮度调整其灵敏度。这是由Michaelis–Menten关系建模的,该关系在[0,Vmax]亮度范围内标准化。
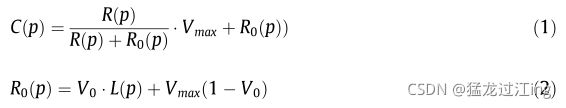
在该关系中,光感受器p的调整亮度C(p)取决于当前亮度R(p)和压缩参数R0(p),压缩参数是与光感受器p的邻域的局部亮度L(p)存在线性关系(参见等式(2))。通过对输入图像应用空间低通滤波器来计算该局部亮度(p)。这种低通滤波实际上是由下一个多细胞网络实现的:第2.1.2.1节中将介绍水平细胞。
如式(2)所示,R0(p)取决于局部亮度L(p)。此外,为了增加灵活性并使系统更精确,我们添加了静态压缩参数V0的贡献值范围[0;1] ,这允许调整局部自适应效果,以提高易用性和精度。它的值通过实验设定为0.90。较低的值会降低局部适应效果。该参数为计算机视觉应用提供了新的自由度。该值范围可以在0.60和0.99之间调整,以获得每像素八比特或更多比特的图片的最佳结果。请注意,Vmax表示图像中允许的最大像素值。在标准八位图像的情况下,其值为255,但在不同编码的情况下(例如高动态范围(HDR)图像、openEXR图像),其值可能会非常不同。在这种情况下,应将Vmax设置为图像或已处理图像集的最大像素值。
图3a示出了关于参数R0(p)的灵敏度的演变。对于R0(p)的低值,灵敏度得到加强,对于高值,灵敏度保持线性。因此,该模型增强了黑暗区域的对比度可见性,同时保持了明亮区域的对比度可见性。
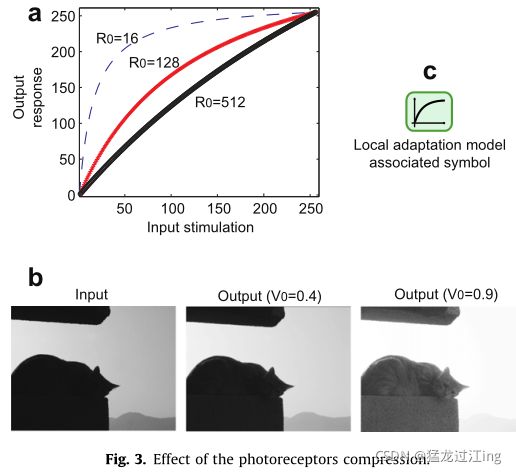
属性
图3b示出了这种压缩对具有两个不同压缩参数V0的背光图片的影响。低照度区域变得更亮,对比度更高,以便显示细节。另一方面,明亮区域没有明显改变。注意,在此示例中,V0的较低值允许限制高亮度值饱和。图3c中描绘的符号与光感受器的对数压缩效应相关联。
2.1.2 OPL:时空滤波与轮廓增强
模型
OPL层的细胞相互作用可以用不可分离的时空滤波器建模,其1D信号的传递函数在式(3)中定义,其中变量fs是空间频率,ft是时间频率。

该滤波器可被视为两个低通时空滤波器之间的差异,这两个低通时空滤波器模拟视网膜的光感受器网络ph和水平细胞网络h。连接的双极细胞执行最后的减法。水平细胞网络(h)的输出仅包含图像的极低空间频率。因此,它被用作局部亮度L(p),L(p)反馈第2.1节中描述的亮度适应阶段。图4a示出了全局OPL方案。在该图中,我们用两个操作符BipON和BipOFF表示Fph和Fh之间的差异,分别给出了Ph和h图像之间差异的正负部分。这模拟了双极单元的动作,双极单元将OPL输出分成两个通道,即ON和OFF。由于这些输出是互补的,因此可以组合它们以可视化图4b中所示并对应于等式(3)的OPL(FOPL)的全局传递函数。该滤波器具有低时间频率的空间带通效应、低空间频率的宽时间带通效应、高时间频率的低通效应和高空间频率的低通效应。
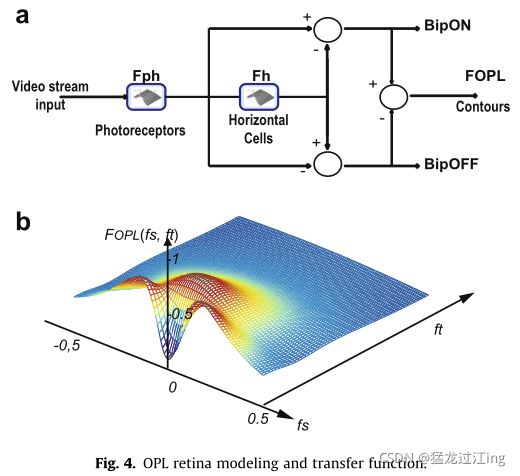
Fopl时空滤波器涉及几个参数:bph是滤波器Fph的增益,该参数通常设置为0,但如果动态范围增大,则应增大该参数。hbh是滤波器Fh的增益。通过将此参数设置为0,只有轮廓信息被提取了出来。调整此参数可以在零频率下调整增益,从而修改图像的平均亮度。Tph和Th是时间滤波约束,使时间噪声最小化。Xph和Xh是设置空间滤波功能的空间滤波约束:Xph设置高截止频率,Xh设置低截止频率。第4节讨论了参数设置示例。
属性
OPL滤波器可以去除时空噪声,增强轮廓。这两个特性是互补的,因为噪声会产生干扰轮廓,所以增强轮廓通常与噪声增强相关联。图5示出了OPL滤波器的效果。这两个序列是在标准光照条件(见图5a)和非常低光照条件(小信噪比)(见图5c)下,使用商用网络摄像头(CCD传感器质量低,压缩效果差)采集的。在这两种情况下,经过OPL滤波后,轮廓增强,信噪比增加。此外,最相关的效果之一是光谱白化,其补偿自然图像的1/f光谱趋势,如图5b所示。这将作为图像输入的解相关。模型和生理学报告先前强调了视觉信息处理在时空域中的这种去相关性。
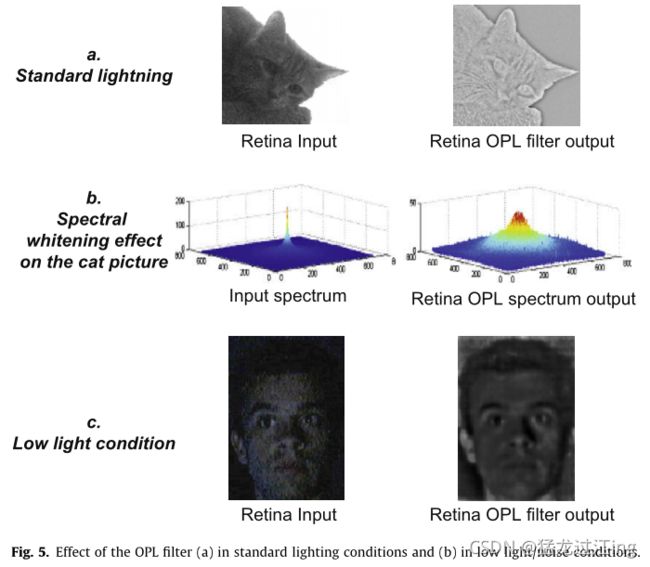
结果,高空间频率轮廓得到增强,零频率降低(例如,这里用Bh=0取消平均亮度)。然后可以轻松提取场景的结构和纹理。
2.1.3 IPL和细小通道:轮廓增强
模型
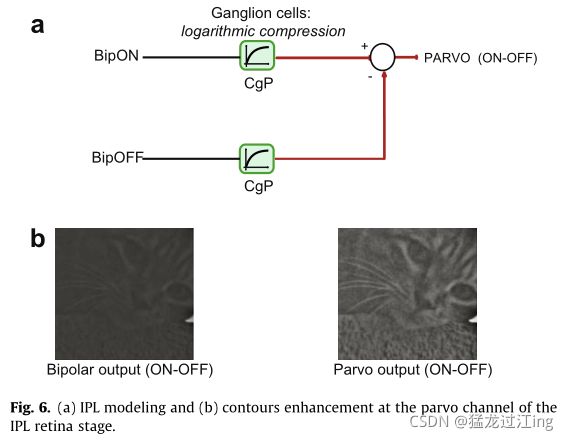
细小通道的神经节细胞(这些神经节细胞称为“侏儒”)接收来自OPL的BipON和BipOFF输出的轮廓信息。根据这些信息,它们充当局部增强器CgP,增强轮廓数据。这是由类似于光感受器的米氏定律模拟的(参见图6a)。
属性
由于输入的信息是关于轮廓的,因此结果是轮廓对比度的增强(参见图6b)。在这里,局部适应定律和光感受器的完全相同。然而,这里输入的数据是不同的。事实上,在这一点上,如果bh> 0的亮度降低,则只有轮廓信息可用,而如果bh= 0则没有亮度。因此,轮廓增强不太依赖于局部亮度,而更依赖于轮廓。此外,由于信息分为两个通道(打开和关闭),每个通道在其自身环境中独立增强,并导致图像局部对比度均衡。
全局细小通道特性
我们在图7a所示的图片中说明包括光感受器、OPL和IPL细小模型在内的细小滤波。在这张图片中,小的黑色箭头放在背景上,背景从深白色到深黑色呈线性变化。使用参数bh=0应用于该图像(参见图7b)的视网膜细小滤波允许提取所有箭头,即使是隐藏在黑色背景中的箭头,同时取消亮度信息。在第二步中,图片被高频时空高斯噪声(u=0,o=0.01)破坏(参见图7c)。图7d显示视网膜细小滤波器对该噪声图像的影响。由于低通时间频率效应和空间频率(即空时间频率)的带通效应,噪声降低了。全局结果是同时降噪和轮廓增强。

表1给出了信噪比分析的结果,符号MSE表示均方误差。视网膜细小模型提高了信噪比:在去除噪声和平均亮度的同时保留轮廓。事实上,图像与视网膜微小滤波后的噪声对应物之间的差别小于输入图像和输入噪声图像之间的差异,增益约为3.1 dB SNR。因此,即使输入受到噪声和背景亮度变化的影响,轮廓响应也会增强。这也解释了为什么计算细小滤波器输入和输出之间的均方误差和信噪比没有意义,因为滤波器会抵消导致完全不同图像的平均亮度。作为比较,使用著名的Cany-Derich算法获得的信噪比为2.8 dB,这略低于视网膜处理,因为在黑暗区域的灵敏度较低。

当处理高动态范围的图像时,例如自然图像,这个细小的过滤器更有趣。这种图像包含更大范围的亮度值,因为图像编码高于标准的每色通道8位格式;它通常是32位。这允许像真实生活一样的图像存储。获取的图像可以包含非常亮和非常暗的区域,具有恒定的精度,但在标准媒体(如标准显示器或打印机)上无法看到所有亮度范围。相似的,由人眼捕获的自然高动态范围(HDR)图像不能由神经元编码,但局部亮度自适应作为数据压缩工具,保留所有相关信息。然后,对这些图像的处理展示了该模型的真正潜力。图8示出了在不同曝光下显示的HDR图像(“记忆”),以使所有细节在纸张上可见。然后,使用视网膜细小通道过滤该高动态范围图像,允许提取场景所有区域中的所有结构信息,无论亮度变化如何。可以实现两个目标:细节提取和亮度压缩。图8b示出了第一个想法:具有零水平细胞增益值(参数Bh=0)的细小滤波器消除平均亮度并提取图像的结构和纹理。第二个想法如图8c所示,其中使用增益的正值(参数Bh=1)的细小滤波器压缩亮度范围,同时保持全局视觉场景环境。在本例中,由于Bh非空值,低频会急剧衰减,但不会被取消。然后,降低局部平均亮度变化幅度。因此,视觉场景可以在较低动态范围的媒体(如打印纸)上渲染,同时保留场景所有区域的所有细节。这种处理被称为“色调映射”,这是一个在更专门的论文中讨论的主题。

2.1.4 IPL和Magno通道:运动专用滤波
模型
在IPL的大细胞通道上,无长突细胞充当高通时间滤波器。我们用一阶滤波器来模拟这种效应。
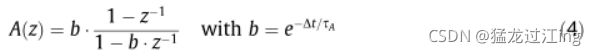
其中Dt=1是离散时间步长,Ta是滤波器的时间常数。此过滤器可增强空间和时间发生变化的域。图9a显示了IPL Magno模型:无长突细胞(A)连接到双极细胞(BipON和BipOFF)和“阳伞”神经节细胞。如同在细小通道上一样,神经节细胞执行局部对比度压缩(CgM),但由于其与相邻细胞的远距离连接,它们也充当空间低通滤波器(FgM,一种类似于OPL模型滤波器的滤波器)。其结果是对轮廓信息进行高通时间滤波(A滤波器),平滑并增强(FgM滤波器和CgM压缩)。因此,仅提取和增强低空间频率的运动轮廓(特别是垂直于运动方向的轮廓)。我们在此重点关注MagnoY输出,它代表在cat Y型细胞上观察到的非线性。
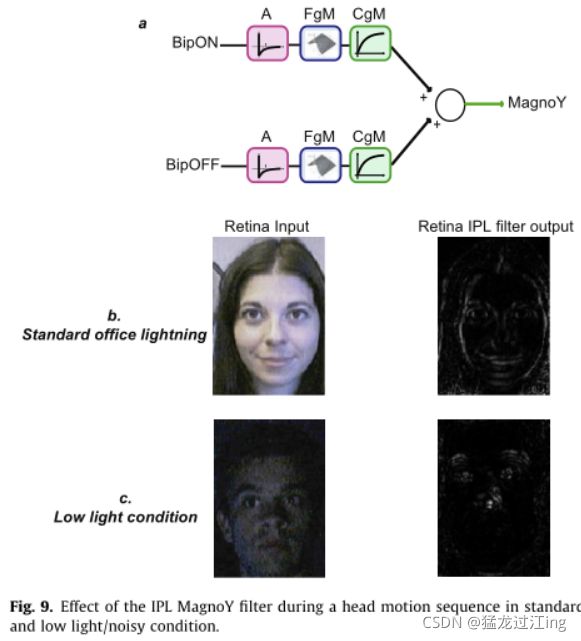
属性
图9b和c给出了IPL Magno输出的示例。图9b示出了平移头部运动的情况。图9c示出了在嘈杂和照明不良的场景中倾斜头运动的情况。垂直于运动方向的运动轮廓被突出,而其他轮廓则被缩小或删除。IPL Magno输出振幅与速度成线性关系(快速移动区域的高响应和静止区域的零响应,在静止区域没有变化)。
我们说明视网膜Magno滤波(包括光感受器、OPL和IPL Magno模型)对图10a所示合成视频序列的影响。在此序列中,一个对象正在平移,而另一个对象在静态背景上保持静止。应用于该图像的视网膜Magno滤波(参见图10b)仅提取运动对象。此外,由于时间效应,运动能量在整个运动物体表面都很高。在第二步中,序列被高频时空高斯噪声(u=0,o=0.01)破坏(见图10c)。图10d示出视网膜Magno滤波器对该噪声序列的影响;噪音已经降低了。更准确地说,应用于原始序列和噪声序列的视网膜Magno滤波输出之间的信噪比为3.2dB。作为比较,图像差是最简单的运动提取方法,因为噪声并没有最小化,所以得到0.2 dB。然后,IPL Magno允许鲁棒运动信息提取,其优点是即使在黑暗或噪声区域也可以利用局部自适应轮廓提取。

2.1.5 视网膜模型综述
图11a显示了具有光感受器、OPL和IPL层的视网膜的全部模型。许多视网膜细胞仍然未知,并不是所有已知的细胞都已建模。然而,这个“不完整”的模型显示了计算机视觉的有趣特性。光感受器和OPL的联合作用构成了系统的基础,并提取出所有轮廓。然后,在IPL层次,两个信息通道显示有关细节和运动的信息。图11b表示整个模型。表2总结了该模型的主要优点和缺点:该模型吸收了生物模型的主要已知优点,并使其可用于图像处理应用。尽管如此,仍有一些工作要做,以便精确校准生物模型的参数,使其适用于视觉替代等生物模拟应用。此可能的应用程序目前正在开发中。

更进一步,最近的一项研究显示了其他参与特定运动背景抑制的特异性聚酮无长突细胞的特性。这篇文章表明,差异运动检测实际上在视网膜水平上很早就开始了。这些特性与所提议的模型的关联将允许针对特定应用(背景运动补偿等)改进高级运动描述。
2.2 初级视觉皮层建模:FFT和对数极坐标变换
2.2.1 模型
由视网膜过滤的信号由外侧膝状体核(LGN)接收并传输到称为区域V1[30]的皮质区域17(此处LGN被视为仅将信息从视网膜传输到皮质的元件)。已经证明,在V1区,视网膜的输出通过方向和频带进行分析。V1皮层水平上发生的有趣的处理模型是FFT振幅和对数极坐标变换的组合。对数极坐标变换通常使用Gabor滤波器执行,该滤波器通过方向和频带对笛卡尔谱进行采样。
我们建议考虑引入模型,该模型包括由以下单个GLOP滤波器的转换函数定义的GLOP滤波器(对数极Gabor滤波器)。
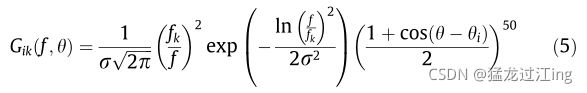
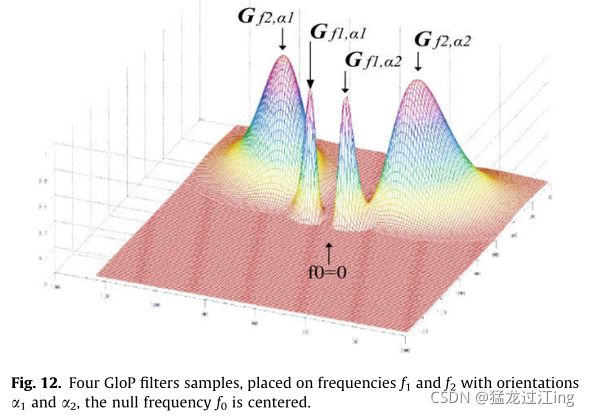
其中,GLOP滤波器以Oi方向中的频率Fk为中心,作为可分离滤波器带有比例参数r。图12展示了四个振幅归一化GLOP滤波器。这些滤波器充当频率和方向分析器,报告与每个特定频率和方向波段相关的能量。与标准Gabor滤波器相比,这些GloP滤波器具有在频率对数尺度上对称的优点,这允许更好的缩放效果分析。
最后一句话,角度和频率样本越多,我们获得的精度就越高,但复杂度更高。作为折衷方案,我们目前最多使用15个角度乘以15个定向频率来获得12°分辨率和快速计算时间。注意,通常V1皮质模型使用大约七个方向的七个频带。
2.2.2 属性
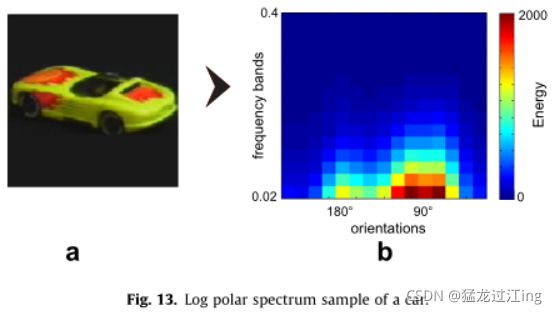
在我们的方法中,我们只考虑由GLOP滤波器集采样的振幅谱,例如,我们对每个滤波器的能量求和,以获得M个波段的N个方向的采样频谱。这种简化的采样光谱可以很容易地解释视觉场景,并具有良好的数据降维,并且可以获得有关其主要方向的信息。作为示例,图13显示了均匀黑色背景前汽车的对数极谱。由于高能量位于频谱的垂直频率(90°),我们可以推断视觉场景的主要方向是水平的。
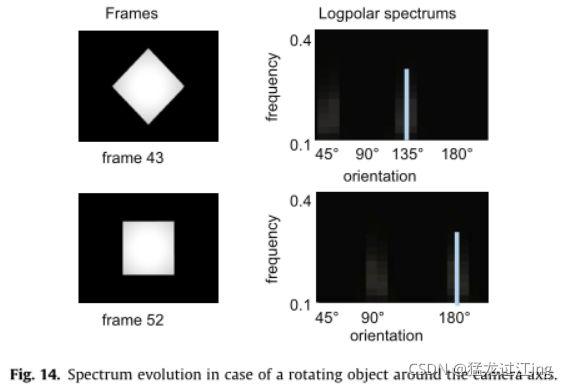
此外,对数极谱具有旋转和缩放效果的特定特性。如果物体绕相机轴旋转(滚动),光谱的结构特征不会改变。但是,全局光谱沿方向轴平移。该效果如图14所示:合成正方形在相机前面旋转。在第43帧,正方形具有垂直和水平对角线,从而产生特定的光谱。在第52帧,一个45°发生旋转,光谱平移45°。
在缩放的情况下,从视频采集系统(眼睛或相机)不同距离捕获的对象始终呈现相同的轮廓。但这些轮廓更集中或放松取决于观看距离。实际上,如果具有相应频谱S(f)的信号i(x)用因子a缩放,结果信号i(a·x) 具有以下光谱:

这导致频谱沿对数频率轴平移:

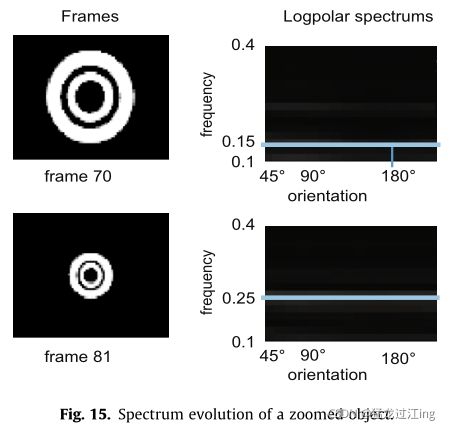
图15示出了在不同距离捕获的环的这种效果(在第70帧,圆环比在第81帧更靠近摄像机)。在频谱上,能量具有相同的方向分布,但第81帧处的平均频率高于第70帧处的平均频率。
这是使用GLOP滤波器而不是标准Gabor滤波器的优点。由于GLOP滤波器在对数空间频率尺度上的对称形状,因此可以准确估计能量平移,这是Gabor滤波器所不可能做到的。
该对数极谱用作结构和纹理分析器。我们将其指定为图16的符号。它的输入是一张图片,通常是视网膜的一个输出(Parvo或Magno),输出是相应的采样对数极谱。该分析器实际上可以被视为接近SIFT算法。事实上,这些算法和可能的应用(对象识别、局部特征分析)是相似的;然而,主要区别在于使用对数极性滤波器,这使得对缩放效果具有更好的鲁棒性。此外,提出的V1皮质模型与视网膜模型相结合,使频谱变白,对高频有更好地描述。
3 仿生低级图像处理模块
从生物学的角度来看,视觉皮层中发生的所有加工通常都与高级加工有关。从这个意义上说,我们正在考虑的生物模型结合了低水平分析(视网膜处理)和高水平分析(V1皮层处理)。同时,从图像处理的角度来看,低级处理与像素级处理相关,而高级处理与对象相关。从这个意义上讲,我们将要介绍的所有模块都是低级图像处理模块。
该生物模型利用来自V1皮质层视网膜的运动信息,并在枕颞皮质的MT/V5皮质层计算高级运动分析。在这个区域,已经指出了对速度梯度和瞬时方向变化敏感的特定皮层细胞。
在这里,我们提出了低层次的运动分析工具,使用类似的方法,并停留在人类视觉的第一个处理步骤。为了执行运动事件检测和方向分析,需要考虑Magno-retina通道和V1 cortex模型分析仪的组合(见图17)。
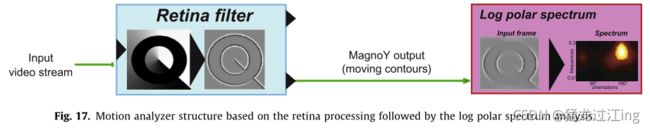
此外,所提出的方法依赖于对输入视频流的全局分析。因此,它适用于静态摄像机。然而,在摄像机运动的情况下,视网膜Magno通道会产生很高的干扰能量。这个问题可以通过使用运动补偿算法来解决。
3.1 运动分析
在所提出的运动分析工具(参见图17)中,对数极谱分析器作用于视网膜滤波器的Magno输出,以便可以提取关于运动幅度、运动方向和运动类型的信息。
3.1.1 运动幅度分析
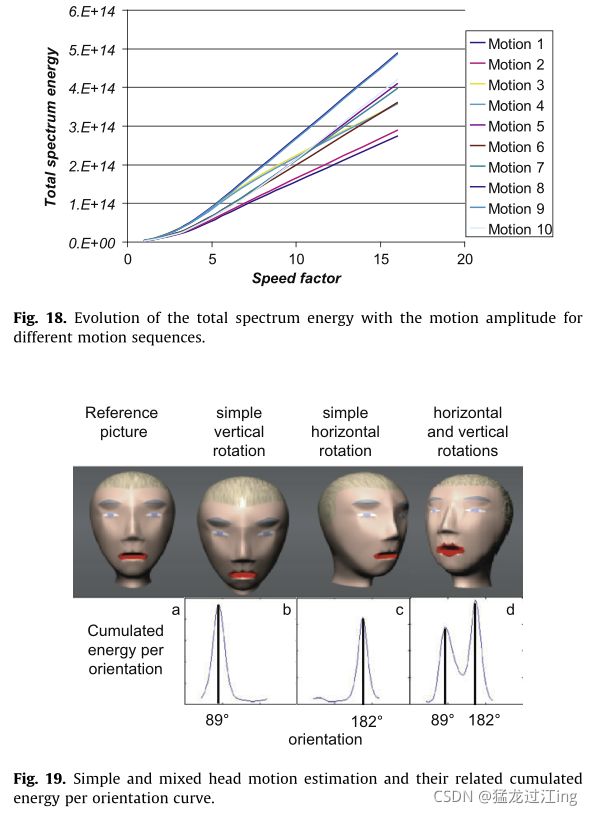
研究了视频序列Magno输出的对数极谱能量随运动幅值的变化规律,发现速度幅值与谱能量之间存在线性关系。这是一个已知的Magno通道特性,模型证实了这一点。我们生成了10个不同的合成头部运动序列(摇动、倾斜、多个方向的平移,参见图19中的说明),它们中的每一个都以10种不同的速度记录下来,从慢运动到快运动,速度系数为线性。然后,对于每个序列,我们计算运动期间的总Magno能量,并将其绘制在图18中。在这张图上,每个运动都给出了与运动速度有关的线性能量演化。考虑到非常低的速度,能量演化不再是线性的。因为只有移动的轮廓贡献了光谱能量,所以当没有运动发生时,该能量为零。
3.1.2 运动方向估计
对数极谱报告了与垂直于运动方向的轮廓相连的方向上的最高能量。为了估计运动方向,我们对每个方向的对数极谱能量求和。这导致每个方向曲线的累积能量(见图19a–d)。在该曲线上,最大振幅的横坐标对应于垂直于运动方向的最活跃运动轮廓的方向。更准确地说,图19给出了合成移动头的帧和相应的累积能量曲线。图19a–c表明单个运动会在每个方向曲线的累积方向能量上产生单个最大值。该能量最大值的横坐标对应于位移的方向。在更复杂运动的情况下(图18d),曲线报告了对应于所涉及的两个旋转轴的两个最大值(例如,与面部两个主要方向相关的水平和垂直方向)。当实现复杂旋转时,这两个方向显示能量,即使它们不是沿运动方向精确定向。这就是众所周知的孔径问题。在我们的例子中,这成为一个优势:在图19d中,出现了两个最大值,每一个(倾斜旋转182°,平移旋转89°)都用于同时发生的当前旋转。此外,可以通过观察每个最大值的振幅变化来分析这种复杂运动。在这种情况下,倾斜旋转比平移旋转要快,因为考虑了与脸部所有方向统计信息相关的归一化能量。
最后,估计运动方向的精度与对数极坐标变换的角度分辨率和观测对象的频率特性有关。因此,如果存在垂直于运动方向的轮廓,则精度更高。
3.1.3 运动类型检测
运动类型(旋转、缩放或平移)与视网膜MagnoY输出对数极谱的一些简单变换有关。如第2.2.2节所述,缩放和滚动运动分别导致沿频率轴和方向轴的全局平移。
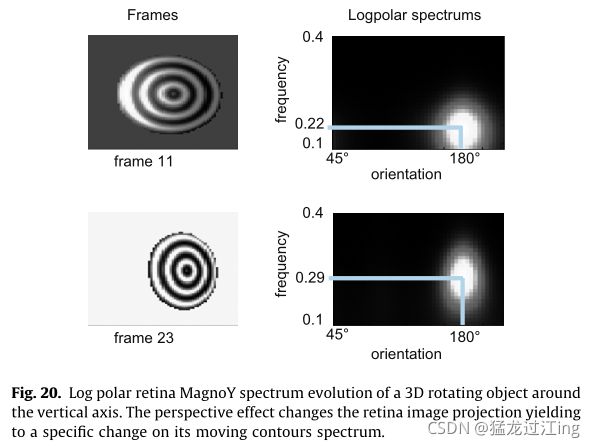
在对数极域中,平移和倾斜旋转会导致沿旋转轴的局部频率平移。事实上,当发生平移或倾斜旋转时,移动轮廓沿着主旋转轴被压缩或扩张,从而相关的空间频率增加或减少。图20示出了环形纹理对象的水平旋转的这种效果。由于旋转方向,对数极谱的能量集中在垂直轮廓上(例如,水平频率)。在第11帧和第23帧之间,对象执行25°水平旋转,最大能量从f11=0.16转换为f23=0.22标准化频率。对数极谱的白色像素对应于高能量值。
最后一种运动类型是对象在摄影机前面的2D平移。在这种情况下,没有频率变化,因为轮廓没有修改。图21示出了相同对象向上平移时的这种效果。只有水平移动的轮廓在频谱上给出响应,并且频谱在运动过程中不会改变。

3.2 上下文感知事件检测
目标是尽可能准确地检测所有慢速或快速运动的动态事件。通过考虑IPL输出的全局能量或其全局对数极谱能量,可以推断视频序列上的运动时间演化信息。事实上,IPL输出能量在运动情况下是最大的,在没有运动发生时是最小的,遵循线性规律。最小能量值与所获取视频序列的时空噪声残差相关。当运动出现时,加速度导致全局谱能量增加,当运动停止时,减速导致全局谱能量减少。
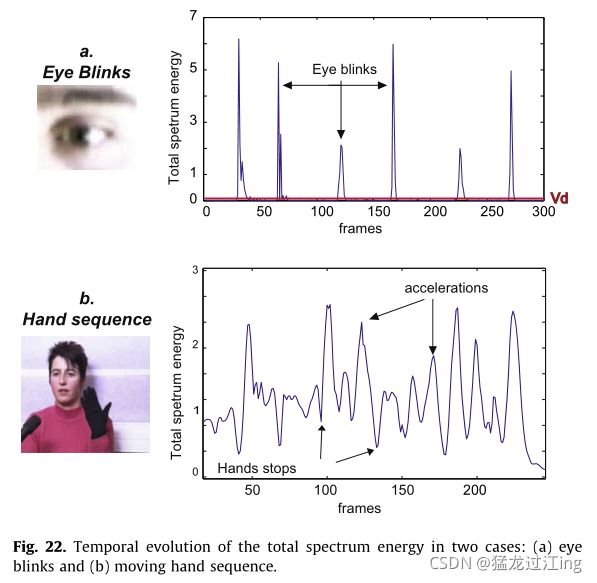
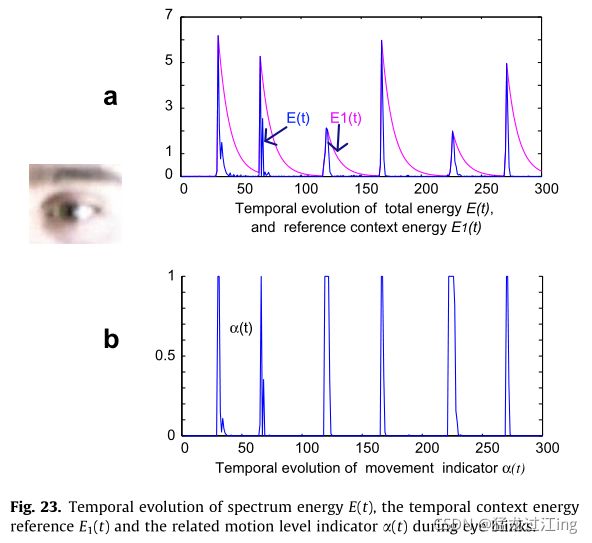
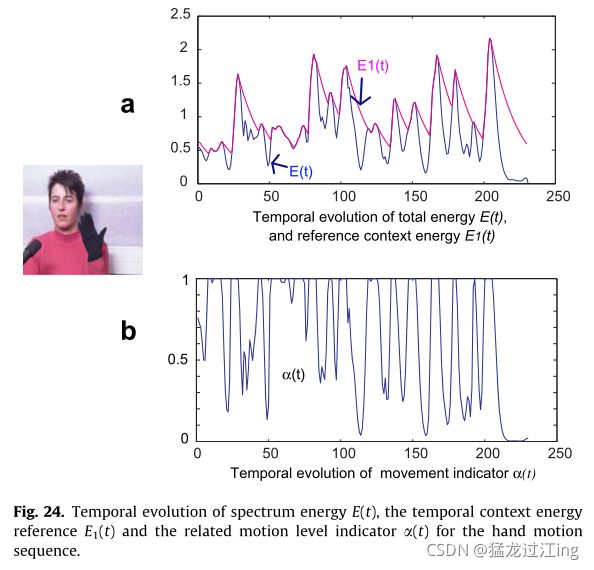
图22给出了周期运动事件的两个示例:图22a示出了眨眼情况下全局频谱能量的演变,图22b示出了移动手势情况下全局频谱能量的演变。
- 在能量曲线上,每个最大值与最大速度相关,每个最小值与运动停止或运动过渡相关。
-
眨眼示例(图22a)示出,即使眨眼从一个眨眼到另一个眨眼几乎相同,由于运动的周期相对于帧速率而言太短,因此对于每个眨眼,全局频谱能量也不相同。采集帧速率(每秒30幅图像)太低,无法捕获最大速度,因此无法达到IPL频谱的预期最大能量值。
-
移动的手示例(图22b)显示每个能量最小值与手减速有关,例如,与两个不同的特定手势之间的运动转换有关。
3.2.1 噪声级估计
与帧采集系统相关的平均噪声级Unoise及其噪声标准偏差Onoise被估计得到(假设为高斯噪声)。噪声级被计算为其中没有发生运动的n个第一帧(当前n=40)的残余噪声级的平均值。Unoise的值可以在序列期间通过使用无运动的帧来更新。事实上,由于Magno IPL能量接近于零,因此很容易检测到没有运动的帧。
当前全局频谱能量E(t)应突出显示场景中存在的运动,如果:
![]()
阈值Vd可视为分析仪可检测到的最小运动变化。从生物学的角度来看,这样的阈值使我们的视觉系统具有最小的灵敏度。在这里,我们主要关注运动检测灵敏度,但在其他任务中,例如视觉对比度灵敏度,已经考虑了该阈值概念。从信号处理的角度来看,这允许通过不考虑小的能量变化来限制假警报。
实际上,即使是非常慢的运动(两帧之间的像素位移超过0.2),全局光谱能量E(t)也高于所考虑的阈值(见图22a,其中Enoise=0.15,Onoise=0.01)。
3.2.2 上下文感知运动水平指示器
我们的目标是提出一种作用于运动能量E(t)的时间滤波,以验证场景中是否存在运动。这需要一个参考来做出决定,这个参考在这里是一个称为E1(t)的运动上下文级别。最后,我们提出了相对运动水平指示器a(t)的定义,其值显示了相对于先前运动的当前运动强度。下面介绍所选择的方法。
参考指示器E1(t)可解释为应用于IPL总能量E(t)的电模拟/连续电流转换器的输出。E1(t)在时间t0达到E(t)的每个最大能量值,并根据指数曲线规律(具有时间常数D的容量效应)暂时减小。
![]()
图23a展示了图22a中呈现的眨眼序列的该效果,并且图24a展示出了图22b的手序列的结果。指示器E1(t)可被视为“运动上下文参考”因为它的值与发生运动转换时的当前运动能量相同,并且忘记了其他时间的最后一个能量峰值作为记忆效果。
最后,我们构建一个相对运动指示器a(t),其目标是将当前能量水平E(t)链接到运动能量上下文E1(t)。a(t)允许估计关于最后一个运动事件(当前事件之间的D秒)的当前能级可靠性。a(t)的定义如下:
![]()
可以将其视为当前上下文中的运动级别指示器。其值保持在0和1之间。当当前能量E(t)比E1(t)所代表的运动能量上下文(即最后的运动振幅)高时,a(t) = 1;当当前能量水平E(t)低于运动能量上下文时,a(t)=0。因此,a(t)给出了与先前运动事件相比当前运动振幅可靠性的信息。
图23b和24b为指标a(t)的时间演化图。当没有运动发生时最小,当运动增加时最大,当运动减慢时减小。阈值水平ma可用于决定场景中是否存在运动:如果a(t)>ma,则检测到运动,如果条件无效,则无运动。较低的ma值(接近0)使系统对所有运动都敏感,并且如果以前的过滤器(此处为视网膜磁振过滤器)不能消除寄生运动的话,也可以检测寄生运动。相反,接近1的值使系统仅对非常高的运动或孤立运动(之前有长时间无运动周期的运动)敏感。例如,阈值水平ma=0.2允许检测所有运动幅度(即使是低运动)。当仅考虑高于Vd的总频谱能量值时,噪声级引入的错误检测风险最小化(见3.2.1)。
我们使用网络摄像头设备(罗技球),使用320*240的图像分辨率,根据表3评估了该指标的性能。它在标准办公室照明条件(300勒克斯环境)下测试,在弱光条件(10勒克斯环境)下测试,这迫使使用的设备传感器获得较低的信噪比,最后在噪声条件下测试(标准照明视频中添加了20%的高斯噪声)。图25示出了所测试的视频序列的一些示例;它由不同照明条件下的室内和室外序列组成。真值由人类专家确定,由3500个运动警报组成,总持续时间为5小时的25 Hz视频。
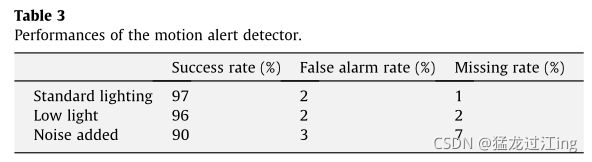

我们使用视网膜模型的相同参数集进行了所有测试:光感受器级(Fph filter)的空间截止频率设置为1.0像素,这使得高频噪声最小化。第二个滤波器Fh将其空间截止频率ah设置为7.0像素,以允许大对象运动检测。时间常数Tph和Th设置为1帧,以最小化高频时间噪声。最后,将IPL Magno级高通时间滤波器的时间常数TA设置为5帧,这允许提取主要高频变化。该系统能够在非常不同的条件下检测运动事件,平均成功率高于90%。我们可以看到,即使视网膜参数在不同的捕获条件下保持不变,运动检测器的性能仍然很高。一方面,这展示了视网膜模型的适应性,该模型允许信号在任何条件下得到增强,另一方面,在视网膜步骤后应用的算法的可靠性。当噪声水平过高时,性能最低。实际上,平均噪声能量级变得接近运动能量,这会产生更高的运动事件检测器丢失率。
4 人类视觉工具软件
4.1 一般介绍
演示软件可用。在网络摄像头的帮助下,可以将视网膜过滤器、V1皮质模型和事件检测器应用于单个图片、图像序列、视频文件或实时视频捕获。该演示还允许将高动态范围图像压缩到低动态范围,就像2.1中说到的那样。此外,可以使用去马赛克算法处理颜色信息。开发库也仅用于学术实验。
该软件的数据采集步骤基于OpenCV,它提供了一个简单、便携的图像处理库。工具箱是用C++编程开发的,它的显示允许在跨平台SDL和OpenGL库的帮助下实时查看处理结果。
考虑到视网膜处理,提出了四种不同的输出(见图26a):第一个对应于光感受器输出。该输出显示了具有背光校正和高频时空噪声滤波的局部亮度自适应。这张图片接近输入,但在信噪比增加的黑暗区域更亮,对比度更高。第二个输出对应于视网膜Parvo通道。在此阶段,平均亮度能量衰减,光谱变白,所有轮廓增强。第三个输出对应于视网膜Magno通道,该通道仅报告移动的低空间频率轮廓上的能量。最后一个输出是显示颜色处理。彩色图像在被视网膜处理之前使用拜耳颜色采样进行多路复用。彩色图像在Parvo视网膜通道的输出处解复用。根据视网膜参数设置,可以执行彩色图像色调映射(见2.1.3)。
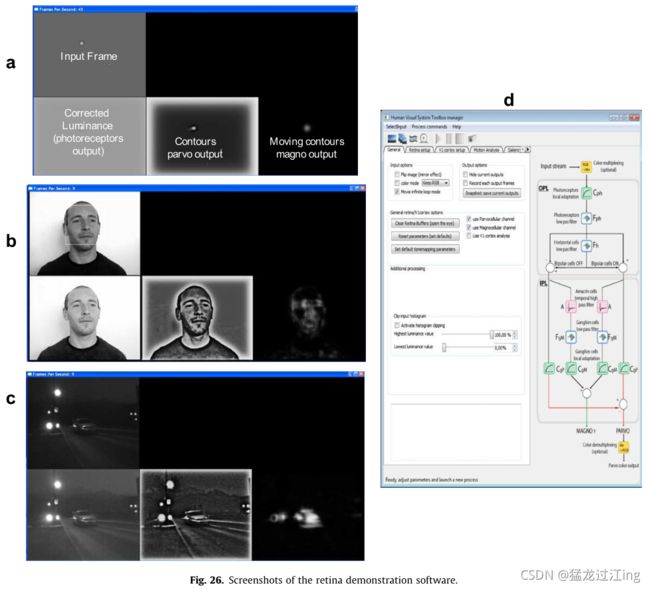
V1皮质模型可用,可应用于输入帧、视网膜Parvo通道或Magno通道,并可观察得到的对数极性采样光谱。最后,事件检测(参见第3.2节)是可用的,并允许灵活的初始化步骤,以适应情况的事件检测。
对于处理效率概述,我们在表4中给出了使用不同图像输入大小的单线程演示获得的帧率,从160×120像素到1024像素×768像素。这项测试是在一台基于英特尔Core2.5GHz T9300处理器和Windows Vista操作系统的笔记本电脑上进行的。请注意,报告的值不考虑图像采集和显示计算时间,以便只关注模型。此外,由于代码会定期增强,因此在相同配置上可以获得更好的结果,而硬件配置和外部库版本可能会影响性能(磁盘访问、实时帧抓取效率、FFT处理速度等)。
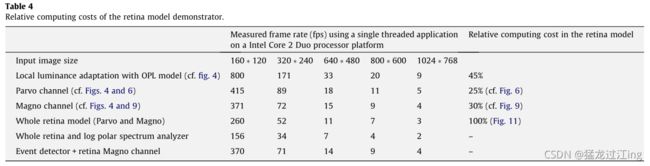
在表中,给出了视网膜模型、V1模型和全局处理的每个部分的计算成本(参见图11)。注意,对于Parvo和Magno滤波,OPL模型(参见图4a)及其包括的光感受器局部适配需要预处理步骤,该步骤在报告值中考虑。当处理如图8c所示的灰度HDR图像亮度压缩时,计算成本是Parvo信道之一,因为模型的这一部分实现了该效果。
视网膜模型及其部分(局部亮度适应和OPL)呈现线性复杂性:当修改图像大小和其他参数时,它们每像素的操作数不会改变。事件检测器也具有这样的属性。图27显示了计算时间和图像大小(要处理的像素数)之间的关系。我们可以看到,无论考虑哪个处理阶段,计算时间都与像素数成正比。请注意,在考虑高分辨率图像时,背景操作系统应用程序和系统内存管理可能会干扰模型计算时间测量,并将计算时间高估10%。
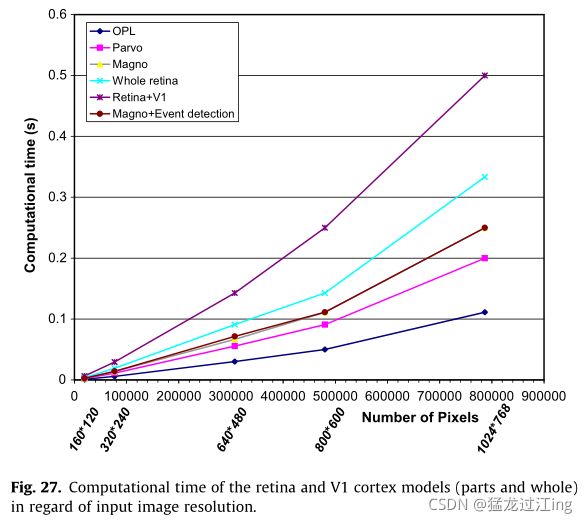
然后,由于视网膜模型以相对较低的每像素操作数通过不可分离的空间和时间滤波实现了有效的局部特征提取,因此该方法适用于需要此类低水平数据提取的常见计算机视觉应用。然而,对于更高的分析级别(V1皮层模型),由于使用FFT,对数极谱的复杂性更高。实际上,它的实现依赖于OpenCV计算的傅里叶变换,然后是频谱对数极坐标变换。最后一步是使用预初始化的转换表(查找表)执行的,这确保了高效率和低处理成本。
4.2 参数
考虑到图像输入约束的标准问题(噪音和背光问题),演示参数被确定下来,以满足通用轮廓提取要求。从这个意义上讲,建议的值对于大范围的图像和图像序列输入是有效的。但是,该程序允许自由修改所有参数。
考虑到视网膜默认设置,光感受器Fph滤波器的空间截止频率aph设置为1.0(高频噪声最小化)。第二个滤波器Fh的空间截止频率ah设置为7.0。这两个值允许提取厚度在(1,7)像素范围内的静态轮廓。将时间常数Tph和Th设置为1帧,以使高频噪声最小化。
高通时间滤波器在IPL Magno级的时间常数Ta设置为5帧,这允许提取主要高频变化。
图26a示出了演示器的图形用户界面。图26b示出了标准照明室内序列处理的示例,其示出了标准条件下系统的效率:将噪声降至最低,可靠地提取静态和移动轮廓。图26c示出了在夜间室外城市八位灰度序列的情况下的视网膜处理的结果。光线不好导致了黑暗和采集到许多噪声。该视频流通过视网膜过滤增强,其输出显示原始帧上无法看到的细节(背景是山脉和建筑,前景是一辆不开灯的移动汽车)。最后,图26d显示了通用参数设置窗口,它允许用户自由调整所有视网膜和V1皮质参数。
4.3 应用和前景
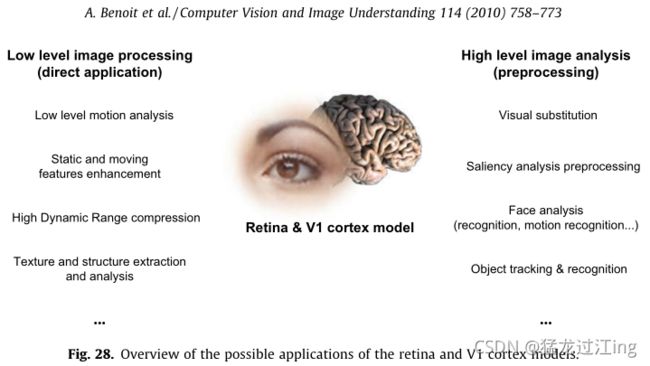
我们的方法考虑了视网膜水平上发生的处理,其主要优点是为高水平处理准备合适的视频数据。因此,从一般的视觉场景分析(细节和运动提取)到更具体的应用(参见图28),将其用于广泛的应用是非常有趣的。我们已经将其用于头部运动分析,并应用低警惕性分析来检测和防止驾驶员入睡。此外,我们还展示了在手语解码环境中使用我们的低级别图像处理模块进行头部运动分析的兴趣。
特别是,这种视网膜模型非常适合视频监控等应用,因为它能够增强视觉信息,即使在背光和噪声的情况下也是如此。我们目前正在研制一种运动物体跟踪器和识别器,该跟踪器和识别器能够通过考虑Magno-retina过滤器输出的运动信息来跟踪物体,并通过使用V1 cortex模型给出的轮廓细节((Parvo视网膜输出)的对数极谱对其进行识别或分类。这最后一步已经开始了。
此外,当考虑图8a所示的高动态范围图像时,该模型在图像亮度压缩方面的作用与人类视网膜类似(即“色调映射”),由于真实世界场景是高动态范围(HDR),但神经元无法编码如此广泛的值(它们可以被认为是低动态范围编码器),视网膜将该HDR信息压缩为LDR格式,并保留视觉场景中的所有细节,如图8c所示。
考虑中的另一个应用是将此模型用作视觉假肢和感觉替代的视频预处理步骤。
最后,这个视网膜模型被设计用于轮廓和对比度构成重要信息的任何环境中。该模型可用于标准摄像机或其他类型的图像(红外、X射线图像等),因为亮度/源振幅信息是考虑的输入数据。使用视网膜模型作为输入数据增强的通用预处理步骤,对于任何需要低水平特征提取以增强高水平分析能力的应用来说,都是非常合适的解决方案。这种预处理模拟人类视觉:需要这些低级计算步骤,以确保更高效的高级视觉场景分析和解释。因此,将这种方法应用于计算机视觉有望使可靠性和效率达到一个新的台阶。这种针对更高层次的通用场景识别或分类的预处理是下一步,它将显示这种方法的兴趣。一个起点应该是视频序列分析和解释,以便进行序列摘要合成。这样的主题将允许对这些模型进行评估,以用于关键帧提取、对象跟踪和识别以及视觉场景分类。关注现实生活中的视频和动画序列应该是评估这种方法在各种情况下的鲁棒性的出发点。
图28总结了所讨论的可从所提议的低级别处理中潜在受益的应用。从“经典”的计算机视觉应用到更多以人类视觉为中心的主题,“类视网膜”预处理有望提高目标应用的性能。在图中,我们区分了可由所提出的模型直接执行的低级图像处理应用程序和需要这些工具作为预处理步骤的高级分析。
5 结论
在本文中,我们提出了低层数据处理模块。所有考虑的模块都基于人类视觉系统特定部分(视网膜和V1皮层)的建模。提出的在高级处理之前的视频数据结构化模块的效率已得到证明。
该模型可以作为图像处理的核心基础,可以扩展到更具体的应用中。从生物学的角度来看,它在图像处理和不同的计算机视觉应用中表现出有趣的特性。它在视频监控应用、头部运动分析或图像分类中的集成显示了它在图像分析和快速计算时间方面的优点。这捍卫了我们构建仿生视觉算法的全局理念。
本文提出的模型侧重于灰度图像处理。有文献提出了用于高动态范围处理应用的颜色信息集成,使用了Chaix de Lavarène等人的精确去马赛克算法。然而,由于在视网膜水平上,许多细胞及其行为在生物学上仍然未知,因此仍然需要进行研究,以便理解和更好地模拟我们自然执行的所有视觉处理步骤。例如,为眼睛/摄像机运动处理引入运动补偿将扩大应用范围。最后,下一个研究步骤是将这种人类视网膜模型应用于更高层次的视频序列分析,在人脸分析中充分利用提取的低层次特征。
终于把这篇文章看翻译完了,之后可以好好学习一下。大家有什么想说的欢迎评论区留言!