自己使用 numpy, pandas, matplotlib 时踩过的坑 + 一些python知识
自己使用 numpy, pandas, matplotlib 时踩过的坑
-
- numpy.sum()计算元素出现次数
- pandas 读取或者选择某几列
- 不同维度array的广播
- 可变参数和关键字参数(*args **kw)
- torch.stack 和 torch.cat
- numpy中的meshgrid方法
- pytorch 将模型和张量加载到GPU
numpy.sum()计算元素出现次数
众所周知,Numpy的sum()方法除了能求和,还能计算元素出现次数,但是目的为后者时,接收对象须为array对象
a = ['外观', '外观', '你好', '1', '1']
print(np.sum(a == '1')) # 输出为0
a = np.array(a)
print(np.sum(a == '1')) # 输出为2
# 除此之外,也能直调用collections模块对数组计数
import collections
collections.Counter(['外观', '外观', '你好', '1', '1']) # 结果为2
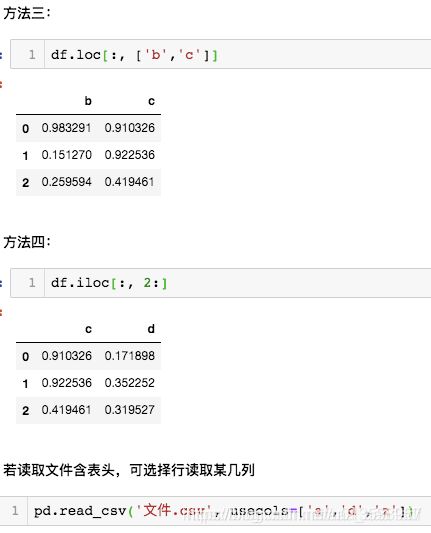
pandas 读取或者选择某几列
df.loc[:, 1:] # 错误
# 方法一
df = pd.DataFrame(df, columns=['a', 'b']
# 方法二
df[['a', 'b']]
# 方法三
df.loc[:, ['a', 'b']]
# 方法四
df.loc[:, 1:]
不同维度array的广播
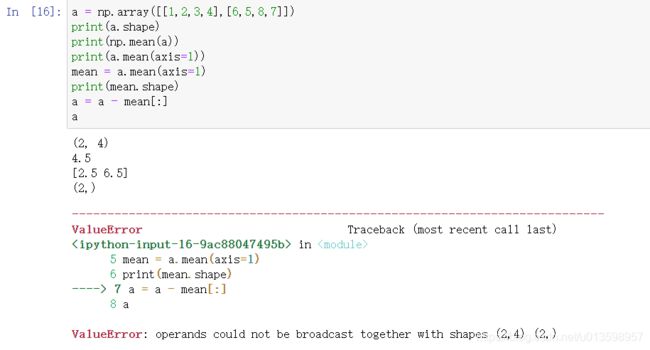
解决方法:
a = a = mean[:, np.newaxis]
# np.newaxis的作用就是选取部分的数据增加一个维度
可变参数和关键字参数(*args **kw)
Python语法中,当*参数 (可变)和 **参数(关键字) 同时出现在函数定义的参数列表中时,说明参数列表可接受任意数量的参数,它们都统称为可变参数。
-
函数定义时
1、*args表示可接受任意个(包含0个)位置参数,当函数调用时,所有未使用(未匹配)的位置参数会在函数内自动组装进一个tuple对象中,此tuple对象会赋值给变量名args
元组的解包功能的如下特点:
1、可以在可变参数中使用
2、也可以在未定义可变参数的函数上使用
所以,元组解包功能是完全独立的一个功能def calc(*numbers): sum = 0 for n in numbers: sum = sum + n * n return sum >>> calc(1, 2) 5 >>> calc() 0 >>> nums = [1, 2, 3] >>> calc(*nums) 142、**kwargs表示可接受任意个(包含0个)关键字参数,当函数调用时,所有未使用(未匹配)的关键字参数会在函数内组装进一个dict对象中,此dict对象会赋值给变量名kwargs
def person(name, age, **kw): print('name:', name, 'age:', age, 'other:', kw) >>> person('Michael', 30) name: Michael age: 30 other: {} >>> person('Bob', 35, city='Beijing') name: Bob age: 35 other: {'city': 'Beijing'} >>> person('Adam', 45, gender='M', job='Engineer') name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'} >>> extra = {'city': 'Beijing', 'job': 'Engineer'} >>> person('Jack', 24, **extra) name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}3.可变参数必须定义在普通参数(也称位置参数、必选参数、选中参数等名称)和默认参数后面!因为可变参数会收集所有未匹配的参数!
3.函数定义时,二者同时存在,一定需要将*args放在**kwargs之前!
-
函数调用时
1、*args表示解包元组对象中的每个元素作为函数调用时传入的位置参数
2、**kwargs表示解包字典对象中的每个元素作为函数调用时传入的关键字参数,即不直接传入字典对象,而是使用字典解包语法 **再传入
torch.stack 和 torch.cat
# 使用方式
torch.stack(inputs, dim=0)
torch.cat(inputs, dim=0)
inputs:必须是张量序列, 在给定维度上对输入的张量序列进行连接操作,序列中所有的张量都应该为相同形状。
cat可以理解为续接,不会增加维度,stack可以理解为叠加,会新加增加一个维度(增加的维度根据输入的dim而定)。
x1 = torch.tensor([[1,2,3], [4,5,6]])# x1.shape = tensor.size([2,3])
x2 = torch.tensor([[7,8,9], [10,11,12]])
x = (x1, x2)
print(x1.shape)
# 沿第0维进行操作
y1 = torch.stack(x, dim=0)
y2 = torch.cat(x, dim=0)
print('y1:', y1.shape,'\n',y1)
print('y2:', y2.shape,'\n',y2)
输出:
torch.Size([2, 3])
y1: torch.Size([2, 2, 3])
tensor([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
y2: torch.Size([4, 3])
tensor([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
另外,对于torch.stack,其插入的维度是介于 0 与 待连接的张量序列数之间,即stack的输入维度范围要比cat大1。
当dim的值等于序列数时,效果如下:
new_x = torch.stack(x, dim=2)
print(new_x.shape)
print(new_x)
torch.Size([2, 3, 2])
tensor([[[ 1, 7],
[ 2, 8],
[ 3, 9]],
[[ 4, 10],
[ 5, 11],
[ 6, 12]]])
从以上结果可以看出,torch.stack(x, dim=2)是将x1[i][j]和x2[i][j]堆叠在一起的。如x1[0][0]=1和x2[0][0]=7堆叠在一起,得到[1, 7]。
numpy中的meshgrid方法
meshgrid函数就是用两个坐标轴上的点在平面上取范围画网格(当然这里传入的参数是两个的时候)。当然我们可以指定多个参数,比如三个参数,那么我们的就可以用三个一维的坐标轴上的点在三维平面上画网格。
numpy.mershgrid(),接受多个一维数组,这里以接受2个为例:

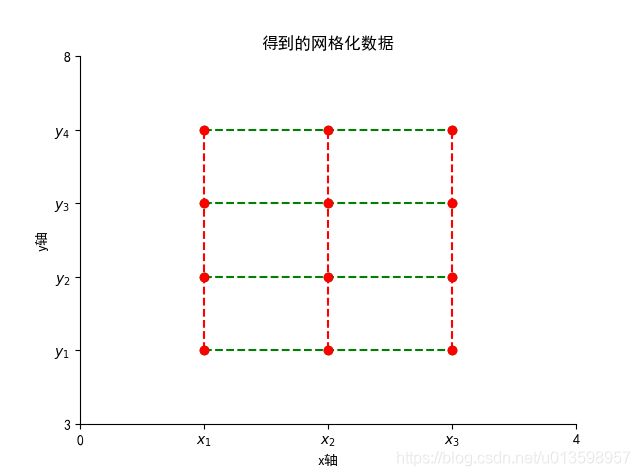
其他参数:
1.索引(indexing):(‘xy’[笛卡尔],‘ij’[矩阵]),可选。默认是’xy’,下面会详细解释一下;
2.稀疏(sparse):bool,可选。默认为False。如果为True为了节省内存会返回一个稀疏矩阵;
3.复制(copy):bool,可选。默认为True。如果为False则为了节省内存返回源始的视图。
对于三维来说,参数是三个一维数组,并且一维数组的形状分别是N,M,P,那么如果indexing = 'xy’的话返回的三个矩阵xv,yv,zv的形状都是(M,N,P);如果indexing = 'ij’的话返回的是三个矩阵xv,yv,zv的形状都是(N,M,P)。
pytorch 将模型和张量加载到GPU
方法一
if torch.cuda.is_available():
model = model.cuda()
X = X.cuda()
y = y.cuda()
方法二
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
X = X.to(device)
y = y.to(device)