深度学习——模型的压缩和加速
1. 简介
随着深度学习发展,越来越多的模型被发现和应用,模型的体量也越来越大,出现了模型过于庞大和参数冗余的问题。同时,移动端对模型的需求也是越轻量越好,因此,模型压缩和加速技术应运而生。
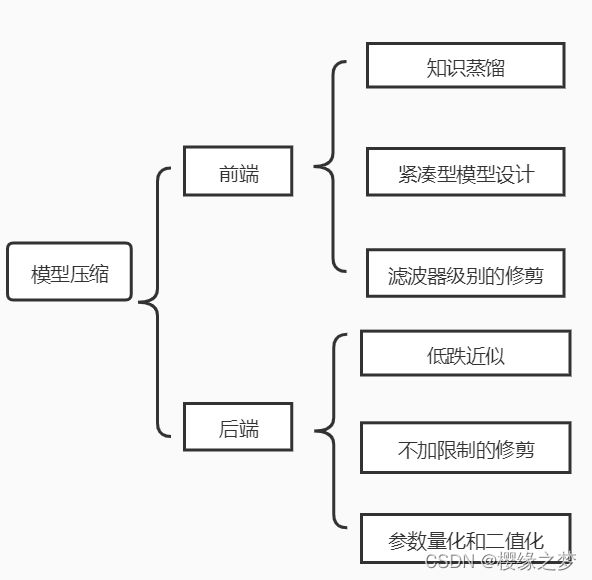
模型压缩和加速的方案有4种:参数修剪和共享(去除不重要的参数)、低秩分解(使用矩阵/张量分解来估计深层CNN【应该适应于其他神经网络模型】中具有信息量的参数)、迁移/压缩卷积滤波器(通过设计特殊结构的卷积核以减少存储和计算成本)、知识精炼(设计教师模型和学生模型,即训练一个更加紧凑的神经网络模型以再现大型网络的输出结果)
模型压缩的方法分为前端和后端两种,后端的压缩方法会改变网络结构,压缩结果不可逆。
2. 入门级技术:量化
初级技术是通过量化或者牺牲精度来降低每一个权重所需要的占用的空间,从而压缩和加速深度神经网络模型。量化技术包括
- 标量量化
对参数矩阵的所有标量值进行聚类,然后存储每一个矩阵值得索引和聚类中心
- 乘积量化
把原始数据划分为若干个子空间,在每个子空间分别进行聚类
- 残差量化
首先对原始的参数矩阵W进行聚类,得到Wc,计算残差W'=W-Wc,然后对残差继续聚类。
- 二值化
设定一个阈值,若权重大于该阈值,将该权重量化为1,否则,量化为-1。
3. 初级技术:修剪
初级技术是修剪法,修剪不重要的连接或者通道来减少模型冗余。主要分为非结构化修剪和结构化修剪。
- 非结构化修剪
为了学习更加复杂的数据集,模型有两方面的趋势,一方面是进行大型矩阵相乘运算来训练数据集,另一方面是把深度网络部署到低能耗、嵌入式设备。常见的方法有
- 静态阈值法:给网络参数设定阈值,低于阈值的都丢弃掉
- Dropout:以等概率性丢弃一些节点
- Adaptive Dropout:使用伯努利分布,取样的概率正比于激活值
- Winner-Take-All:只保留隐藏层排名前k%的激活值
- 随机性哈希法:采用局部敏感性哈希来提高最大内积搜索效率,从而快速选择激活值最大的那些节点
- 结构化修剪
常见方法有:
- 滤波器修剪:分为HFP和SFP,HFP(Hard Filter Pruning)是一种粗粒度修剪方法,寻找一些指标对卷积核进行排序,对不符合指标的卷积全部删除,然后再对网络进行微调,SFP(Soft Filter Pruning)是在每一个epoch训练结束之后将被修剪的卷积核的值置为0,但是会参与到下一次迭代。
- 通道修剪:两个步骤:第一步是通道选择,使用L1范数约束,将权重置为0,使得权重稀疏,并减掉稀疏的通道,第二步是重建,用最小二乘法进行约束,使得修剪前后特征图一致。
4. 中级技术:稀疏化技术
- 正则化
正则化是修改目标函数和学习问题,从而得到一个参数较少的神经网络,分为结构正则化和非结构正则化,非结构正则化是L0,L1,L2;结构化正则化是group-lasso范式和L2.1范式。
- 知识精炼(Knowledge Distillation,KD)
知识精炼可以将深度和宽度的网络压缩为千层模型,该压缩模型模仿了复杂模型所能实现的功能。基本思想是通过软目标学习教师输出的类别分布而将大兴教师模型的知识精炼为较小的模型。
- 张量分解
张量分解也叫低秩分解或者低秩近似,方法有SVD分解、Tucker分解。
秩是度量矩阵行列之间的相关性,如果矩阵的各行和各列都是线性无关的,矩阵就是满秩,秩等于行数,低秩是矩阵的行列可以用其他行列代替,存在一定的数据冗余。
5. 高级技术:轻量级模型设计
相较于在已经训练好的模型上进行压缩处理,轻量化模型设计主要思想是设计更搞笑的网络计算方式,从而使得网络参数减少的同时,不损失网络性能。
5.1 SqueezeNet
SqueezeNet提出了一种fire module来进行卷积操作,它分为两个部分:squeeze层和expand层,squeeze层是压缩层,使用1*1的卷积核来减少通道数量,其卷积核数要少于上一层feature map数。expand是扩展层,分别使用1*1和3*3的卷积,并将分别得到的结果进行合并。
5.2 深度可分离卷积
深度可分离卷积(Depthwise Separable Convolution)是将标准卷积分解成深度卷积(Depthwise Convolution)以及一个1*1的卷积即逐点卷积(Pointwise Convolution),DC是对输入的特征图的每一个通道分别使用一个卷积核,然后所有卷积核的输出再进行拼接。
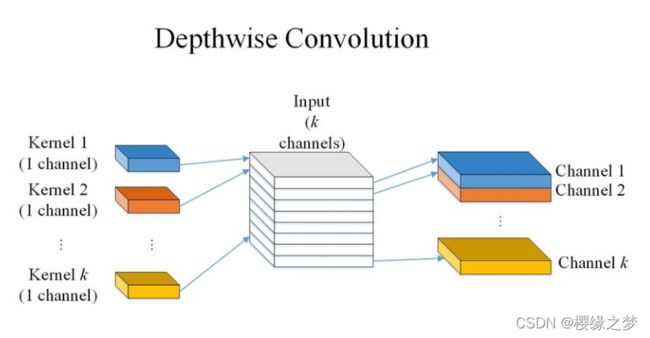
PC是1*1的卷积,可以自由改变输出通道的数量,也可以对DC的结果进行通道融合。特殊的结构使DSC的效率较高,常用在轻量化模型中。
(1)MobileNet
MobileNet是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络。MobileNet基于一个流线型的架构,使用DSC来构建,还引入了Width Multiplier和Resolution Multiplier两个超参数,WM是宽度因子,用于控制输入和输出的通道数,RM是分辨率因子,用于控制输入和内部层表示,即控制输入的分辨率。
MobileNet有三个版本:
V1:基于深度可分离卷积而构建的模型
V2:基于倒置残差结构
V3:使用NAS搜索
详解回头补充吧!!!
(2)ShuffleNet
ShuffleNet是通道洗牌(channel shuffle),是将各部分特征图的通道进行有序地打乱,构成新的特征图,以解决分组卷积带来的信息流通不畅的问题。
(3)Inception和Xception
Inception模型是GoogleNet提出的一种为解决卷积核选择困难的问题的方案,使用3个不同大小的卷积核对输入图片进行卷积操作,并附加最大池化,将这4个操作的输出沿着通道这一维度进行拼接,构成的输出特征图将会包含经过不同大小的卷积核提取出来的特征,从而达到捕捉不同尺度信息的效果。
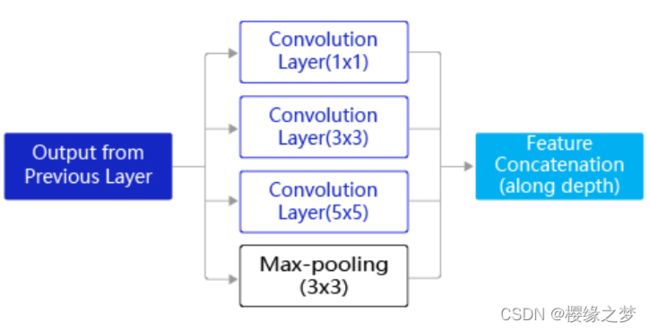
Inception模块采用多通路(multi-path)的设计形式,每个支路使用不同大小的卷积核,最终输出特征图的通道数是每个支路输出通道数的总和,这将会导致输出通道数变得很大,尤其是使用多个Inception模块串联操作的时候,模型参数量会变得非常大。为了减小参数量,Inception模块在每个3x3和5x5的卷积层之前,增加1x1的卷积层来控制输出通道数;在最大池化层后面增加1x1卷积层减小输出通道数。
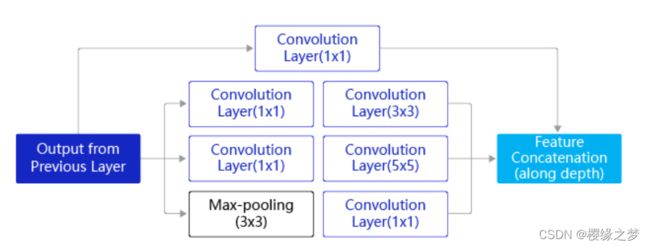
Xception的X是extreme,是基于Inception V3来改进的,采用了DSC模型,目的不在于模型压缩,而是提高性能。
6. 自动化工具
6.1. PaddleSlim
PaddleSlim是一种深度学习模型压缩的工具库,提供剪裁、量化、蒸馏和模型结构搜索等模型压缩策略,帮助用户快速实现模型的小型化。(百度公司提出的)
具体细节参考:
简介 — PaddleSlim 文档
6.2. PocketFlow
PocketFlow是一个开源框架,用于以最少的人力压缩和加速深度学习模型。深度学习广泛应用于计算机视觉、语音识别和自然语言翻译等各个领域。(腾讯公司提出的)
Home - PocketFlow Docs
参考:
《深入理解AutoML和AutoDL》——王健宗,瞿晓阳