《异常检测——从经典算法到深度学习》15 通过无监督和主动学习进行实用的白盒异常检测
《异常检测——从经典算法到深度学习》
- 0 概论
- 1 基于隔离森林的异常检测算法
- 2 基于LOF的异常检测算法
- 3 基于One-Class SVM的异常检测算法
- 4 基于高斯概率密度异常检测算法
- 5 Opprentice——异常检测经典算法最终篇
- 6 基于重构概率的 VAE 异常检测
- 7 基于条件VAE异常检测
- 8 Donut: 基于 VAE 的 Web 应用周期性 KPI 无监督异常检测
- 9 异常检测资料汇总(持续更新&抛砖引玉)
- 10 Bagel: 基于条件 VAE 的鲁棒无监督KPI异常检测
- 11 ADS: 针对大量出现的KPI流快速部署异常检测模型
- 12 Buzz: 对复杂 KPI 基于VAE对抗训练的非监督异常检测
- 13 MAD: 基于GANs的时间序列数据多元异常检测
- 14 对于流数据基于 RRCF 的异常检测
- 15 通过无监督和主动学习进行实用的白盒异常检测
- 16 基于VAE和LOF的无监督KPI异常检测算法
- 17 基于 VAE-LSTM 混合模型的时间异常检测
- 18 USAD:多元时间序列的无监督异常检测
- 19 OmniAnomaly:基于随机循环网络的多元时间序列鲁棒异常检测
- 20 HotSpot:多维特征 Additive KPI 的异常定位
相关:
- VAE 模型基本原理简单介绍
- GAN 数学原理简单介绍以及代码实践
- 单指标时间序列异常检测——基于重构概率的变分自编码(VAE)代码实现(详细解释)
15. 通过无监督和主动学习进行实用的白盒异常检测
论文名称:Practical and White-Box Anomaly Detection through Unsupervised and Active Learning
发表于 ICCCN 2020
下载地址:https://netman.aiops.org/wp-content/uploads/2020/08/ICCCN2020-YaoWang.pdf
会议PPT:https://netman.aiops.org/wp-content/uploads/2020/09/icccn-2020-talk-ppt.pdf
个人翻译地址:笑颜网
论文源码未能找到,抱歉。
15.1 论文概述
论文提出的模型 iRRCF-Active,包含两部分:
- 改进的 RRCF:(improved Robust Random Cut Forests) ,即 iRRCF
- Active learning :主动学习。
首先了解一下 RRCF 用于异常检测的基本原理 14. 对于流数据基于 RRCF 的异常检测。
接着看论文中的 图3,即对模型结构的总体概述:

三个部分:
- 训练。用到了改进的 RRCF ,怎么改进的后面再看。
- 检测。用到了主动学习,这个步骤与 Feedback 关系密切。
- 优化。也就是 主动学习的一个指导部分,这部分最好提供一下人工标签进行指导。
15.2 训练(III-A Training)
15.2.1 预处理(Preprocessing)
论文主要是对相似的 KPI 进行集群,这里面用到了两个方法:
- Dynamic Time Warping (DTW) 用来计算两个 KPI 之间的相似程度(《Using dynamic time warping to find patterns in time series》)。
- DBSCAN 对大量的KPI 进行集群。
这样做的主要目的是节省训练的时间,集群后 KPI 的长度以及 KPI 的数量都会有所减少。
15.2.2 改进的RRCF(Improved RRCF)
此部分主要包括以下几个方面。
特征表示 Feature Representation
先看表2,这里列举了 改进的 iRRCF 与 原始的 RRCF 的区别。

| 过程 | 原 RRCF | 改进的RRCF |
|---|---|---|
| 特征表示 | 历史临近点 | 具有特征选择的时间序列统计特征 |
| 结点分割选择 | 只考虑维度的范围 | 也考虑尺寸的最大距离 |
| 结点分割阈值选择 | 按随机选择的间隔切割 | 以最稀疏的间隔剪切 |
| 异常值计算 | 只考虑兄弟姐妹(同级)结点 | 还要考虑节点深度 |
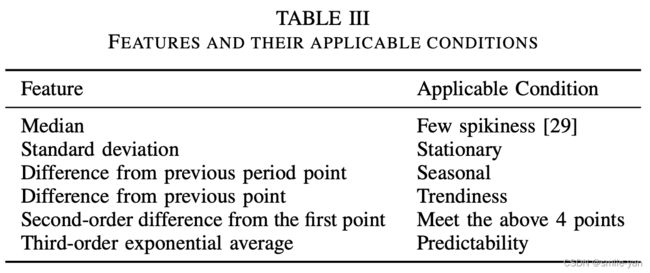
| 特征 | 适用条件 |
|---|---|
| 中值 | 少毛刺的 |
| 标准差 | 固定的 |
| 与之前区域的点的差异 | 周期的 |
| 与之前的点的差异 | 趋势的 |
| 与第一点的二阶差 | 满足以上4点 |
| 三阶指数平均 | 可预测性 |
节点切割尺寸(维度)选择 Node Cut Dimension Selection
由于不同的KPI通常具有不同的统计特征,因此这些特征可能不适用于每个KPI。因此,论文设计了一组统计指标,并计算每个KPI的值。接下来,我们根据这组指标确定哪些特征适合KPI(如上表所示)。即,根据KPI的情况选择相应条件下的特征。

在提取数据特征以后, RRCF 会随机地选择分割尺寸(维度),并进行分割,来构建多棵决策树。首先看 左边的图片(Fig. 4 (a)),首先把特征 1 进行分割,根据值是否大于 107.65 分割成两棵子树,进而下一步根据特征 2 进一步分割。**因为 Feature 1和 Feature 2 特征明显 (distinguishing),所以只需要分割成两层就可以区分所有样本。 ** 右边的图(Fig. 4(b)) 表示对于不明显的特征,需要分割成更多层才能把所有样本分开 。(注意两张图片 Feature 2 是没有关系的,个人认为这样处理不妥,不如把右边的特征 2 改成特征 5 )
节点分割阈值选择 Node Cut Threshold Selection
原始RRCF随机选择最大和最小特征值之间的值作为切割阈值。对于高分辨特征,其数据往往具有聚集分布,因此稀疏切割的效果要比密集切割的效果好得多。因此,在iRRCF中,在选择切割维度后,我们特别关注该维度中的数据分布,并增加稀疏分布中的切割概率。从形式上讲,这个过程可以总结如下:
- 将从训练集中提取的特征划分为 N N N 个区间 [ l 0 , h 0 , l 1 , h 1 , . . . , l N − 1 , h N − 1 ] [l_0, h_0,l_1,h_1,...,l_{N-1},h_{N-1}] [l0,h0,l1,h1,...,lN−1,hN−1]
- 计算每个区间的特征密度 d i = C o u n t ( p , p ∈ [ l i , h i ] ) d_i = Count(p, p\in [l_i, h_i]) di=Count(p,p∈[li,hi])。
- 选择一个与 d i ∑ j d j \frac{d_i}{\sum_j {d_j}} ∑jdjdi 成比例的随机区间 i i i 。
- 选择 X i ∼ U n i f o r m [ l i , h i ] X_i \sim Uniform[l_i, h_i] Xi∼Uniform[li,hi]。
异常值计算 Anomaly Score Calculation
在RRCF中,每个样本将落在树中的一个叶节点上,原始RRCF林将计算每个样本的异常得分 C o D i s p CoDisp CoDisp ,以表征异常程度。 C o D i s p CoDisp CoDisp 的计算过程如下:
- 找到每棵树的叶子中样本 x i x_i xi 的叶子结点 N o d e Node Node。
- 计算 N o d e Node Node 的兄弟结点以及父结点为根的子树中的样本数,记作 S N o d e . s i b l i n g S_{Node.sibling} SNode.sibling 和 S N o d e . p a r e n t S_{Node.parent} SNode.parent,计算 C o D i s p N o d e = S N o d e . s i b l i n g S N o d e . p a r e n t CoDisp_{Node} = \frac{S_{Node.sibling}}{S_{Node.parent}} CoDispNode=SNode.parentSNode.sibling 。
- 在树上上升一级, N o d e = N o d e . p a r e n t Node = Node.parent Node=Node.parent
- 重复 2 与 3 步骤 N N N 次,其中 N N N 是使用的特征的数量。
- C o D i s p T CoDisp_T CoDispT 是每一个 C o D i s p N o d e CoDisp_{Node} CoDispNode 的最大值。
- 对于样本 x i x_i xi 的最终的 C o D i s p x i CoDisp_{x_i} CoDispxi 为 C o D i s p T CoDisp_T CoDispT,其中 T ∈ f o r e s t T \in forest T∈forest
15.3 检测 (Detection)
15.3.1 候选标签推荐 Candidate Labels Recommendation
这部分的内容可以概述为:如何协助操作员,把最需要人工标记的部分推给操作员进行手动标记,标记完了后,可以更好地维护更新模型。
具体内容大致包括:
- 选择30个最不正常的段。获得这些标签可以进一步确认明显的异常并消除误报。
- 选择30个最不确定的异常片段。时间序列的异常检测是一个二元分类问题。获得此类标签可以进一步改善分类结果的边界,还可以提高识别模糊异常的准确性。
- 根据异常评分将数据分为10组,每组选择3个异常片段,概率中等。获取这些标签可以捕获操作员对算法评估产生的不同程度的异常的偏好,然后有助于确定哪一组更可能成为异常和正常情况之间的边界点。

iRRCF中这些策略的详细实现如 图5 所示。根据第四节中的实验,策略 1 被证明比其他两种策略更有效。因此,论文在模型中采用了策略 1。
15.3.2 模型优化 Model Optimization
模型优化:原始RRCF基于实时数据维护动态树集合。当新数据点到达时,RRCF执行插入过程,并使用该数据点更新模型中的每个树。此过程会导致额外的计算,从而减慢检查过程。考虑到实际中异常的数量相对较少,可以根据数据的异常程度有选择地更新树。为了确保模型能够及时覆盖极端特征的变化,需要更新两类数据点。一种类型是连续异常段中的第一个异常点,另一种类型是在特定维度上被判断为正常但极度异常的点。我们统称这两类点为极端点。此外,为了获得某些特殊曲线的缓慢变化趋势,iRRCF-Active还将在两类数据点长时间未出现时,以较低的频率使用正常点更新模型。我们的方案如算法1所示。
论文中 算法1 则是指异常值计算与模型优化,具体内容如图所示:

关于 CODISP§ ,请参照上面 异常值计算部分。
15.4 反馈 Feedback
为了从用户反馈中受益,我们设计了两种基于标签的 iRRCF 模型优化策略。标签的使用不限于训练阶段。用户可以在训练阶段应用一组历史累积的标签。在开始实时检测后,由于结果不佳,他们可能会标记单个异常。因此,反馈策略必须同时适用于组或单个标签。
a. 原始 RRCF 包含多个随机构建的树,它们的分类精度分数不同。在用户反馈的帮助下,iRRCF 主动评估哪些树在分类方面更可靠,并相应地为这些树赋予更高的权重。算法2中描述了基于一组标签调整模型的过程。
b. 原始 RRCF 要求正态数据的比例远大于异常数据的比例。在iRRCF Active中,通过重复应用正常样本10次来更新模型,从而增强正常样本的影响。同时,对于标记为异常的样本,可以将每个树中样本对应的节点标记为异常。

根据第四节中的实验,策略a更适合我们改进的RRCF。
15.5 算法评估
这一部分内容这里不详细介绍了,用到了两个数据集,一个是 iops.ai 的比赛数据集,这个前面也提到过,注册登录就可以下载了,另外一个是银行的数据,这个肯定是不允许公开使用的。
如果需要编写论文,同样写到了算法评估这个模块的时候,可以参考一下这一部分内容。包括数据集介绍,算法结果展示方法等等。
15.6 总结
简单概述这篇论文就是:对 RRCF 进行了改进,改进方法主要包括两方面:算法模型比如训练方法,检测方法等,添加主动学习模块让算法可以在操作员的帮助下更新模型以适应新的场景。
但比较遗憾的是论文没有公开源码,不能跑一下源码体验一下了。论文来自于 ICCCN 2020,虽然ICCCN是一个 CCF C 类会议,但是它的难度一般比别的 C 类会议大很多。所以有时间的小伙伴也推荐读一读了解了解此方法。
Smileyan
2022.2.18 17:18
感谢您的 点赞、 收藏、评论 与 关注 .