In the last decade, with the discovery of deep learning, the field of image classification has experienced a renaissance. Traditional machine learning methods have been replaced by newer and more powerful deep learning algorithms, such as the convolutional neural network. However, to truly understand and appreciate deep learning, we must know why does it succeed where the other methods fail. In this article, we try to answer some of those questions, by applying various classification algorithms on the Fashion MNIST dataset.
在过去的十年中,随着深度学习的发现,图像分类领域经历了复兴。 传统的机器学习方法已被更新和更强大的深度学习算法(例如卷积神经网络)取代。 但是,要真正理解和欣赏深度学习,我们必须知道为什么其他方法失败时它会成功。 在本文中,我们尝试通过对Fashion MNIST数据集应用各种分类算法来回答其中的一些问题。
Dataset information Fashion MNIST was introduced in August 2017, by research lab at Zalando Fashion. Its goal is to serve as a new benchmark for testing machine learning algorithms, as MNIST became too easy and overused. While MNIST consists of handwritten digits, Fashion MNISTis made of images of 10 different clothing objects. Each image has the following properties:
数据集信息Fashion MNIST由Zalando Fashion的研究实验室于2017年8月推出。 随着MNIST变得过于简单和过度使用,其目标是成为测试机器学习算法的新基准。 MNIST由手写数字组成,而Fashion MNIST由10种不同服装对象的图像组成。 每个图像具有以下属性:
- Its size is 28 × 28 pixels. 尺寸为28×28像素。
- Rotated accordingly and represented in grayscale, with integer values ranging from 0 to 255. 进行相应旋转并以灰度表示,整数值的范围为0到255。
- Blank space represented by black color and having value 0. 黑色表示的空白,值为0。
In the dataset, we distinguish between the following clothing objects:
在数据集中,我们区分以下服装对象:
- T-shirt/Top T恤/上衣
- Trousers长裤
- Pullover拉过来
- Dress连衣裙
- Coat涂层
- Sandal凉鞋
- Shirt衬衫
- Sneaker运动鞋
- Bag袋
- Ankle Boot脚踝靴
Exploratory data analysis As the dataset is available as the part of the Keras library, and the images are already processed, there is no need for much preprocessing on our part. The only changes we made was converting images from a 2D array into a 1D array, as that makes them easier to work with.
探索性数据分析由于数据集可以作为Keras库的一部分使用,并且图像已经过处理,因此我们不需要太多预处理。 我们所做的唯一更改是将图像从2D数组转换为1D数组,因为这使它们更易于使用。
The dataset consists of 70000 images, of which the 60000 make the training set, and 10000 the test set. Like in the original MNIST dataset, the items are distributed evenly (6000 of each of training set and 1000 in the test set).
数据集包含70000张图像,其中60000张为训练集,10000张为测试集。 像在原始MNIST数据集中一样,项目也平均分配(每个训练集6000个,测试集中1000个)。
However, a single image still has 784 dimensions, so we turned to the principal component analysis (PCA), to see which pixels are the most important. We set the traditional benchmark of 80% of the cumulative variance, and the plot told us that that is made possible with only around 25 principal components (3% of the total number of PCs). However, that is not surprising, as, we can see in the photo above, that there is a lot of shared unused space in each image and that different classes of clothing have different parts of images that are black. The latter can be connected to the fact that around 70% of the cumulative variance is explained by only 8 principal components.
但是,单个图像仍然具有784个尺寸,因此我们转向了主成分分析(PCA),以了解哪些像素最重要。 我们将传统基准设置为累积方差的80%,该图告诉我们,只有大约25个主要组件(占PC总数的3%)才能实现这一点。 但是,这并不奇怪,因为我们可以在上一张照片中看到,每个图像中都有大量共享的未使用空间,并且不同类别的衣服具有不同的黑色图像部分。 后者可能与以下事实有关:仅由8个主要成分来解释大约70%的累积方差。
We will apply the principal components in the Logistic regression, Random Forest and Support Vector Machines.
我们将在Logistic回归,随机森林和支持向量机中应用主要组件。
The image classification problems represent just a small subset of classification problems. The most used image classification methods are deep learning algorithms, one of which is the convolutional neural network. The rest of the employed methods will be a small collection of common classification methods. As class labels are evenly distributed, with no misclassification penalties, we will evaluate the algorithms using accuracy metric.
图像分类问题仅代表分类问题的一小部分。 最常用的图像分类方法是深度学习算法,其中之一就是卷积神经网络。 其余采用的方法将是一小部分常见分类方法。 由于类别标签均匀分布,没有分类错误的惩罚,因此我们将使用准确性度量来评估算法。
CONVOLUTIONAL NEURAL NETWORK (CNN) The first method we employed was CNN. As the images were in grayscale, we applied only one channel. We selected the following architecture:
卷积神经网络(CNN)我们采用的第一种方法是CNN。 由于图像是灰度图像,因此我们仅应用了一个通道。 我们选择了以下架构:
- Two convolutional layers with 32 and 64 filters, 3 × 3 kernel size, and relu activation. 具有32和64个滤镜,3×3内核大小和relu激活的两个卷积层。
- The polling layers were chosen to operate of tiles size 2 × 2 and to select the maximal element in them. 选择轮询层以操作大小为2×2的图块并在其中选择最大元素。
- Two sets of dense layers, with the first one selecting 128 features, having relu and softmax activation. 两组密集层,其中第一层选择128个要素,具有relu和softmax激活。
There is nothing special about this architecture. In fact, it is one of the simplest architectures we can use for a CNN. That shows us the true power of this class of methods: getting great results with a benchmark structure.
这种架构没有什么特别的。 实际上,它是我们可用于CNN的最简单的体系结构之一。 这向我们展示了此类方法的真正力量:通过基准结构获得出色的结果。
For loss function, we chose categorical cross-entropy. To avoid overfitting, we have chosen 9400 images from the training set to serve as a validation set for our parameters. We used novel optimizer adam, which improves overstandard gradient descent methods and uses a different learning rate for each parameter and the batch size equal to 64. The model was trained in 50 epochs. We present the accuracy and loss values in the graphs below.
对于损失函数,我们选择分类交叉熵。 为了避免过度拟合,我们从训练集中选择了9400张图像作为我们参数的验证集。 我们使用了新颖的优化程序adam,它改进了超标准的梯度下降方法,并且对每个参数使用了不同的学习率,并且批处理大小等于64。模型在50个历元内进行了训练。 我们在下图中显示精度和损耗值。
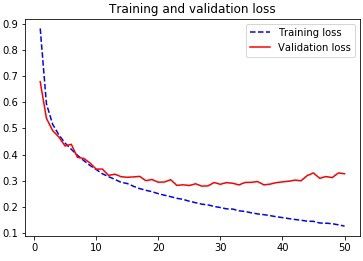

We see that the algorithm converged after 15 epochs, that it is not overtrained, so we tested it. The obtained testing accuracy was equal to89%, which is the best result obtained out of all methods!
我们看到该算法在15个纪元后收敛,没有受到过度训练,因此我们对其进行了测试。 获得的测试精度等于89%,这是所有方法中获得的最佳结果!
Before proceeding to other methods, let’s explain what have the convolutional layers done. An intuitive explanation is that the first layer was capturing straight lines and the second one curves. On both layers we applied max pooling, which selects the maximal value in the kernel, separating clothing parts from blank space. In that way, we capture the representative nature of data. In other, neural networks perform feature selection by themselves. After the last pooling layer, we get an artificial neural network. Because we are dealing with the classification problem, the final layeruses softmax activation to get class probabilities. As class probabilities follow a certain distribution, cross-entropy indicates the distance from networks preferred distribution.
在继续其他方法之前,让我们先解释一下卷积层的作用。 直观的解释是,第一层捕获直线,第二层捕获曲线。 在这两个层上,我们都应用了最大池化(max pooling),该池选择内核中的最大值,从而将衣物部分与空白空间分开。 这样,我们可以捕获数据的代表性。 换句话说,神经网络自己执行特征选择。 在最后的合并层之后,我们得到了一个人工神经网络。 因为我们正在处理分类问题,所以最后一层使用softmax激活来获取类概率。 当类别概率遵循某个分布时,交叉熵表示距网络首选分布的距离。
Multinomial Logistic Regression As pixel values are categorical variables, we can apply Multinomial Logistic Regression. We apply it one vs rest fashion, training ten binary Logistic Regression classifiers, that we will use to select items. In order not to overtrain, we have used the L2 regularization. We get 80% accuracy on this algorithm, 9% less accurate than convolutional neural networks. But we have to take into account that this algorithm worked on grayscale images which are centred and normally rotated, with lots of blank space, so it may not work for more complex images.
多项逻辑回归由于像素值是分类变量,因此我们可以应用多项逻辑回归。 我们将其应用于休息方式与休息方式,训练了十个二元Logistic回归分类器,这些分类器将用于选择项。 为了不过度训练,我们使用了L2正则化。 我们在此算法上获得80%的精度,比卷积神经网络的精度低9%。 但是我们必须考虑到,该算法适用于居中且正常旋转的灰度图像,并且有很多空白,因此对于较复杂的图像可能不起作用。
Nearest neighbors and centroid algorithms We used two different nearest distance algorithms:
最近邻居和质心算法我们使用了两种不同的最近距离算法:
- K-nearest neighbors K近邻
- Nearest Centroid最近的质心
Nearest centroid algorithm finds mean values of elements of each class and assigns test element to the class to which the nearest centroid is assigned. Both algorithms were implemented with respect to L1 and L2 distance. The accuracy for k-nearest algorithms was 85%, while the centroid algorithm had the accuracy of 67%. These results were obtained for k=12. High accuracy of the k-nearest neighbors tells us that the images belonging to the same class tend to occupy similar places on images, and also have similar pixels intensities. While nearest neighbours obtained good results, they still perform worse than CNNs, as they don’t operate in neighbourhood of each specific feature, while centroids fail since they don’t distinguish between similar-looking objects (e.g. pullover vs t-shirt/top)
最近质心算法查找每个类别的元素的平均值,并将测试元素分配给分配了最近质心的类别。 两种算法都是针对L1和L2距离实现的。 k最近算法的精度为85%,而质心算法的精度为67%。 对于k = 12获得这些结果。 k最近邻的高精度告诉我们,属于同一类的图像倾向于在图像上占据相似的位置,并且具有相似的像素强度。 虽然最近的邻居取得了不错的效果,但它们的表现仍然比CNN差,因为它们不在每个特定特征附近工作,而质心失败了,因为它们无法区分外观相似的物体(例如套衫vs T恤/上衣/上衣)
Random Forest To select the best parameters for estimation, we performed grid search with squared root (bagging) and the full number of features, Gini and entropy criterion, and with trees having maximal depth 5 and 6. Grid search suggested that we should use root squared number of features with entropy criterion (both expected for classification task). However, obtained accuracy was only equal to 77%, implying that random forest is not a particularly good method for this task. The reason it failed is that principal components don’t represent the rectangular partition that an image can have, on which random forests operate. The same reasoning applies to the full-size images as well, as the trees would be too deep and lose interpretability.
随机森林要选择估计的最佳参数,我们进行与平方根(套袋)和全多项功能,基尼和熵准则网格搜索,并用具有最大深度5和6网格搜索建议我们应该用根树具有熵标准的特征的平方数(均属于分类任务)。 但是,获得的准确性仅等于77%,这意味着随机森林并不是执行此任务的特别好的方法。 失败的原因是主要成分不代表图像可以具有的矩形分区,随机森林在该矩形分区上运行。 同样的道理也适用于全尺寸图像,因为树木太深并且无法解释。
Support Vector Machines (SVM) We applied SVM using radial and polynomial kernel. The radial kernel has 77% accuracy, while the polynomial kernel fails miserably and it is only 46% accurate. Although image classification is not their strength, are still highly useful for other binary classifications tasks. Their biggest caveat is that they require feature selection, which brings accuracy down, and without it, they can be computationally expensive. Also, they apply multiclass classification in a one-vs-rest fashion, making it harder to efficiently create separating hyperplane, thus losing value when working with non-binary classification tasks.
支持向量机(SVM)我们使用径向和多项式内核应用了SVM。 径向核的准确度为77%,而多项式核则严重失败,准确度仅为46%。 尽管图像分类不是它们的优势,但对于其他二进制分类任务仍然非常有用。 他们最大的警告是,他们需要特征选择,这会降低准确性,而没有它,它们在计算上可能会很昂贵。 而且,它们以“一对多”的方式应用多类分类,这使得更难有效地创建分离的超平面,从而在处理非二进制分类任务时失去了价值。
Conclusions In this article, we applied various classification methods on an image classification problem. We have explained why the CNNs are the best method we can employ out of considered ones, and why do the other methods fail. Some of the reasons why CNNs are the most practical and usually the most accurate method are:
结论在本文中,我们对图像分类问题应用了各种分类方法。 我们已经解释了为什么CNN是我们可以考虑使用的最佳方法,以及其他方法为什么会失败。 CNN最实用且通常最准确的方法的一些原因包括:
- They can transfer learning through layers, saving inferences, and making new ones on subsequent layers. 他们可以通过层级转移学习,保存推理并在后续层级上进行新的学习。
- No need for feature extraction before using the algorithm, it is done during training. 在使用算法之前不需要特征提取,它是在训练期间完成的。
- It recognizes important features. 它认识到重要功能。
However, they also have their caveats. They are known to fail on images that are rotated and scaled differently, which is not the case here, as the data was pre-processed. And, although the other methods fail to give that good results on this dataset, they are still used for other tasks related to image processing (sharpening, smoothing etc.).
但是,他们也有一些警告。 众所周知,它们在旋转和缩放比例不同的图像上会失败,在这种情况下不是这样,因为数据已经过预处理。 而且,尽管其他方法无法在此数据集上获得良好的结果,但它们仍用于与图像处理有关的其他任务(锐化,平滑等)。
Code: https://github.com/radenjezic153/Stat_ML/blob/master/project.ipynb
代码: https : //github.com/radenjezic153/Stat_ML/blob/master/project.ipynb
翻译自: https://towardsdatascience.com/image-classification-with-fashion-mnist-why-convolutional-neural-networks-outperform-traditional-df531e0533c2