- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 谢谢你们,爱你们!
鹿游儿
昨天家人去泡温泉,二个孩子也带着去,出发前一晚,匆匆下班,赶回家和孩子一起收拾。饭后,我拿出笔和本子(上次去澳门时做手帐的本子)写下了1\2\3\4\5\6\7\8\9,让后让小壹去思考,带什么出发去旅游呢?她在对应的数字旁边画上了,泳衣、泳圈、肖恩、内衣内裤、tapuy、拖鞋……画完后,就让她自己对着这个本子,将要带的,一一带上,没想到这次带的书还是这本《便便工厂》(晚上姑婆发照片过来,妹妹累得
- 小丽成长记(四十三)
玲玲54321
小丽发现,即使她好不容易调整好自己的心态下一秒总会有不确定的伤脑筋的事出现,一个接一个的问题,人生就没有停下的时候,小问题不断出现。不过她今天看的书,她接受了人生就是不确定的,厉害的人就是不断创造确定性,在Ta的领域比别人多的确定性就能让自己脱颖而出,显示价值从而获得的比别人多的利益。正是这样的原因,因为从前修炼自己太少,使得她现在在人生道路上打怪起来困难重重,她似乎永远摆脱不了那种无力感,有种习
- 我的烦恼
余建梅
我的烦恼。女儿问我:“你给学生布置什么作文题目?”“《我的烦恼》。”“他们都这么大了,你觉得他们还有烦恼吗?”“有啊!每个人都会有自己烦恼。”“我不相信,大人是没有烦恼的,如果说一定有的话,你的烦恼和我写作业有关,而且是小烦恼。不像我,天天被你说,有这样的妈妈,烦恼是没完没了。”女儿愤愤不平。每个人都会有自己的烦恼,处在上有老下有小的年纪,烦恼多的数不完。想干好工作带好孩子,想孝顺父母又想经营好自
- 今日联对0306
诗图佳得
自对联:烟销皓月临江浒,水漫金山荡塔裙。一一肖士平2020.3.6.1、试对肖老师联:烟销皓月临江浒,夜笼寒沙梦晚舟。耀哥求正2、试对萧老师联:烟销浩月临江浒,雾散乾坤解汉城。秀霞习作请各位老师校正3、自对联:烟销皓月临江浒,水漫金山荡塔裙。一一肖士平2020.3.6.4、试对肖老师垫场联:烟销皓月临江浒,雾锁寒林缈葉丛。小智求正[抱拳]5、试对肖老师联:烟销皓月临江浒;风卷乱云入峰巅。一一五品6
- 每日一题——第八十四题
互联网打工人no1
C语言程序设计每日一练c语言
题目:编写函数1、输入10个职工的姓名和职工号2、按照职工由大到小顺序排列,姓名顺序也随之调整3、要求输入一个职工号,用折半查找法找出该职工的姓名#define_CRT_SECURE_NO_WARNINGS#include#include#defineMAX_EMPLOYEES10typedefstruct{intid;charname[50];}Empolyee;voidinputEmploye
- 情殇——(5)压抑的小木匠放纵了自己。
石疯聊情感故事
木讷的小木匠,其实只是不苟言笑。其实内心深处也是挣扎着,由于性格内敛,不喜形于色,给人的感觉非常的木讷。其实小木匠情商智商都不低。他为人扎实,非常的务实。他的爱是既深沉又宽容。可是是一个男人,都会对妻子出轨的事儿,不会忘怀!只是压抑在心底,为了某种考量或许是真爱。小木匠对于丽影和别人私奔又重回家庭,表面上并没有,天翻地覆,暴风骤雨,其内心深处也是经历了,痛苦的挣扎。。。再一次酒后,他和一个离家多年
- 感赏日志133
马姐读书
图片发自App感赏自己今天买个扫地机,以后可以解放出来多看点书,让这个智能小机器人替我工作了。感赏孩子最近进步很大,每天按时上学,认真听课,认真背书,主动认真完成老师布置的作业。感赏自己明白自己容易受到某人的影响,心情不好,每当此刻我就会舒缓,感赏,让自己尽快抽离,想好的一面。感赏儿子今天在我提醒他事情时,告诉我谢谢妈妈对我的提醒我明白了,而不是说我啰嗦,管事情,孩子更懂事了,懂得感恩了。投射父母
- 我的黑历史
袖手围观有来有去
孩子同学与我们一起共进晚餐,俩孩子加我三个人。小同学是一个大方率性礼貌的小孩,我们也都非常喜欢。好了,回到正题上来让我把这个故事讲完。俩孩子都喜欢吃鱼,所以就发生了小孩子之间常会发生的事。我狠狠的盯了我家孩子,孩子表情有些狼狈。和孩子单独一起的时候,见她尚未释怀,并谴责我不该狠盯她,让她没面子。也许是她触动了我的童年往事吧。由此,一狠心,给她讲了一段埋藏心里极深的黑历史:我奶奶有四个儿子,四个儿子
- 从0到500+,我是如何利用自媒体赚钱?
一列脚印
运营公众号半个多月,从零基础的小白到现在慢慢懂了一些运营的知识。做好公众号是很不容易的,要做很多事情;排版、码字、引流…通通需要自己解决,业余时间全都花费在这上面涨这么多粉丝是真的不容易,对比知乎大佬来说,我们这种没资源,没人脉,还没钱的小透明来说,想要一个月涨粉上万,怕是今天没睡醒(不过你有的方法,算我piapia打脸)至少我是清醒的,自己慢慢努力,实现我的万粉目标!大家快来围观、支持我吧!孩子
- 想明白这个问题,你才能写下去
文自拾
春节放假的时候,又有一天梦见她,第二天她冒着漫天大雪,傻傻地跑来见我。她说,见见傻傻的我,天很冷,心很暖。她回去后,我写了一篇文章,题目叫——从此梦中只有你。我们没在一起的很长一段时间里,她都在我的心底,一次次出现在我的梦里。我对她说,在一起之前,是胆小且闷骚,在一起之后,我变得不要脸了。不要脸的——去爱你。那文章没写完,火车上,给她看了。我有点小失望,花了好几个小时写,她分分钟就看完,很希望她逐
- 2019-08-08
65454
东莞家庭聚会出行旅游去哪里玩住?想起来有很久没有和家里人聚会啦,这次组织家人来到威廉古堡别墅轰趴,一大家子27个人,在别墅订了一天办,玩的非常的开心,小孩子玩游戏机,也很放心不会丢,我们就在唱歌、打麻将、打桌球一系列的活动,还准备小次等小孩生日在别墅举办,还可以给孩子做一个生日的策划
- 没有邀请码怎么注册买手妈妈?
氧惠评测
买手妈妈怎么注册小编为大家带来买手妈妈没有邀请码怎么注册。打开买手妈妈APP,点击“马上注册”,输入邀请信息“邀请码”点击下一步,没有邀请码是登录不上的,所以这个必须要填写,那我们没有怎么办?填写成功就可以登录下一步。这里面有手机登录和淘宝登录,手机登录以后也需要用淘宝授权的,所以基本上都是淘宝登录。购物、看电影、点外卖、用氧惠APP!更优惠!氧惠(全网优惠上氧惠)——是与以往完全不同的抖客+淘客
- 嘿,谢谢你
小小玛拉沁
突然想对一个女孩子说,谢谢你!很久很久以前,总是觉得和你不会有太多交集,充其量也只是普通的舍友吧,毕竟有很多习惯,性格等方面相差甚远。其实特别感谢2017这一段经历和我遇见的人,只会慢吞吞的过自己生活的安小蜗是不会主动去结交朋友的,所以她来到了我的世界,让我在不知不觉中发现了自己太多太多的问题,而我正在逐渐去改变这些的习惯,成为更好的自己!我总是超级佩服她不管什么时候精力都超级旺盛,可以在上了一天
- 怎么做淘客赚钱(2022最新免费淘客盈利的方法)
高省_飞智666600
很多人都不知道什么是淘宝客,今天小编为大家解答一下吧。淘宝客,现在简称淘客,是时下比较流行的一个词语,特质为淘宝店推广商品获取提成的人,这些人没有自己的产品,只是在淘宝里面选择适合自己的产品,在自己比较熟悉的领域推广,把产品卖出去之后,会从淘宝店家那里获得百分之五到百分之五十左右的佣金。淘宝客付出的是什么呢?时间。你需要花时间去选适合自己推广的产品,需要花时间去选自己的推广方法,如果你打算自己做个
- C++菜鸟教程 - 从入门到精通 第二节
DreamByte
c++
一.上节课的补充(数据类型)1.前言继上节课,我们主要讲解了输入,输出和运算符,我们现在来补充一下数据类型的知识上节课遗漏了这个知识点,非常的抱歉顺便说一下,博主要上高中了,更新会慢,2-4周更新一次对了,正好赶上中秋节,小编跟大家说一句:中秋节快乐!2.int类型上节课,我们其实只用了int类型int类型,是整数类型,它们存贮的是整数,不能存小数(浮点数)定义变量的方式很简单inta;//定义一
- 2019-3-23晨间日记
红红火火小耳朵
今天是什么日子起床:7点40就寝:23点半天气:有太阳,不过一会儿出来一会儿进去特别清爽的凉意,还蛮舒服的心情:小激动要给女朋友过生日啦纪念日:田田女士过生日任务清单昨日完成的任务,最重要的三件事:1.英语一对一2.运动计划3.认真护肤习惯养成:调整状态周目标·完成进度英语七天打卡(5/7)轻课阅读(87/180)音标课(25/30)读书(福尔摩斯一章)学习·信息·阅读#英语课#Cookingte
- 日常演播练习0822
开阳春天
日常演播练习0822一、绕口令练习司小四和史小世,四月十四日十四时四十上集市,司小四买了四十四斤四两西红柿,史小世买了十四斤四两细蚕丝。司小四要拿四十四斤四两西红柿换史小世十四斤四两细蚕丝。史小世十四斤四两细蚕丝不换司小四四十四斤四两西红柿。司小四说我四十四斤四两西红柿可以增加营养防近视,史小世说我十四斤四两细蚕丝可以织绸织缎又抽丝。二、文本练习狗熊是动物街有名的美食家,它吃得多所以长得胖,它能吃
- 数字里的世界17期:2021年全球10大顶级数据中心,中国移动榜首
张三叨
你知道吗?2016年,全球的数据中心共计用电4160亿千瓦时,比整个英国的发电量还多40%!前言每天,我们都会创造超过250万TB的数据。并且随着物联网(IOT)的不断普及,这一数据将持续增长。如此庞大的数据被存储在被称为“数据中心”的专用设施中。虽然最早的数据中心建于20世纪40年代,但直到1997-2000年的互联网泡沫期间才逐渐成为主流。当前人类的技术,比如人工智能和机器学习,已经将我们推向
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- 热和冷
萍梗子
刚回家时,是阴冷潮湿天气,担心孩子着凉感冒。如今气温回升,天气暖和舒适,却又觉得干燥了,孩子嘴唇有破裂,小脸蛋也红扑扑的。需要补水。需要保湿。小爹的一句“不适应了”,让我感慨不同地区气候的不同。从海南到浙江。而去年三月去北京那几天,也是觉得干燥得很,加上雾霾,嘴唇鼻子喉咙,都难受得很。真是一方水土养一方人。在一个地方待久了,就适应那个地方的气候了。中华大地,地域广阔。风土人情也真是有很大的不同。世
- 每天都有“小感动”
河北张海霞
上次开学,在楼道值班儿的我,回到办公室后,发现我的办公桌上了一个小饭盒,打开一看,是自家腌的萝卜片,闻起来香香的,是哪位有心的孩子带来的?我猜测着……会不会是杨同学,记得开学第一天,她胃疼再加上低血糖,我曾陪她去医务室看病,并给她带回了早餐……还是李同学,那次她被别的同学欺侮,我为她主持公道。晚餐时间到了,我还带她去餐厅吃饭,引得同学们一阵羡慕……会不会是王同学,那次她眼睛不好,我陪她聊天,关心地
- 第九十章 真情
溪境
图片发自App图片发自App和雏田在一起的日子真的很开心。姐姐永远是最亲的最真的。佐助总来捣乱。小樱准备一盆水泼佐助。想到恋爱通告亦菲被泼水不免高兴。亦菲是最美的。没想到她也会有这种遭遇。也许不需要赚那么多钱。和家人在一起的日子真好。却轻易破碎。雏田的话语温软,依稀在耳边。她的微笑纯美温柔。喜欢温柔的哥哥,雏田就是这样啊。不知道雏田是喜欢男生还是女生。我都支持。过去门当户对。现在自由恋爱。想永远和
- 厦门自由行之第一天:
大苏子在广漂
厦门三人行之杂记出发前一天:12️28日下午15:00从广州粗发,来深圳集合!但是中间发生一个小插曲,验票时候发现车票不见了,或许也是一场恶作剧,对于不排队的人,忍不住说了一下,接下来就发现车票不见了,已经是拿在手上!不过还好,可以凭借购票订单查看到信息,所以有惊无险,顺利进站!晚上三个人一起去吃了柠檬鱼,说实话,那会,感觉美吃饱,啊哈哈!晚上回来,两个人又开始彻夜长谈,发现身边优秀的人,一大把,
- Python开发常用的三方模块如下:
换个网名有点难
python开发语言
Python是一门功能强大的编程语言,拥有丰富的第三方库,这些库为开发者提供了极大的便利。以下是100个常用的Python库,涵盖了多个领域:1、NumPy,用于科学计算的基础库。2、Pandas,提供数据结构和数据分析工具。3、Matplotlib,一个绘图库。4、Scikit-learn,机器学习库。5、SciPy,用于数学、科学和工程的库。6、TensorFlow,由Google开发的开源机
- 在一起的日子
少些期待
在一起已经三年多了,我是一个97年的摩羯座女生,他是一个89年的同样的摩羯座男生,刚开始是他追的我,我开始对他也挺有好感的,他从他朋友哪里,要到我的电话号,给我发信息,我没理他。然后我们的故事就这样开始了·····我不记得到底是什么,让我对他特别喜欢,想一心一意跟着他过日子,说白了我也就是个他的小跟班,又或者是个小跟屁虫,或者是个保姆,反正就是他在那里,我就得陪他到哪里,谈了半年多对象的时候,他因
- 《太虚游》第六十二章。玄牝之威。
古楼臭道士
“好好好,流云这孩子深得我心,想必长爻知道是你的话定然会惊喜不已的。”白玄牝听得风流云应了下来,脸色慈和,伸手在他头顶轻轻抚了抚,如同抚在怀中九尾小狐一样自然,极其温柔。身后的四位青丘长老同时一怔,嘴角微动,似要开口劝阻。风流云只感到一道霞光瑞气如有实质一般顺着头顶百会大穴直沉在下丹田内,随后这股气息又逐渐凝聚,似乎给自己吃了什么东西一般。啊喔不好,这祖奶奶该不会是看中我这肉身,像人魔一样,要给她
- 童年那些故事教给我们的
山川大地日月星辰
同事的女儿二次考研失败,但是仍不气馁还想接着再学再考,得为孩子点个赞,可是同事很矛盾,以她的意见,当初女儿大学毕业就该直接考编,回到家过安稳日子,我问她还记不记得《小马过河》的故事?她说跟小马有啥关系?幼儿园就给孩子讲《小马过河》,当然孩子们除了喜欢故事里的“人物”小松鼠、老牛、小马跟老马,对小马爱劳动喜欢帮助妈妈干活也是有基本认知的,孩子们对为什么老牛说水浅、而松鼠说水深也有一定的常识,到了成人
- 一颗小桃树
李蓉乐平市湾头中小学
当“凹”同“洼”的时侯,才读(wa,平声),他不叫贾平洼(贾,原名贾平娃),非要写作贾平凹。为了表示对他的尊重,对文学的尊重,对文化人的尊重。如果不是帮闺蜜的儿子修改作文,我也不会发现贾平凹叫贾平娃。以下是摘选他的文章《一棵小桃树》:可我的小桃树儿,一颗“仙桃”的种子,却开得太白了,太淡了,那瓣片儿单薄得似纸做的,没有肉的感觉,没有粉的感觉,像患了重病的少女,苍白白的脸,又偏苦涩涩地笑着。雨还在下
- Python实现简单的机器学习算法
master_chenchengg
pythonpython办公效率python开发IT
Python实现简单的机器学习算法开篇:初探机器学习的奇妙之旅搭建环境:一切从安装开始必备工具箱第一步:安装Anaconda和JupyterNotebook小贴士:如何配置Python环境变量算法初体验:从零开始的Python机器学习线性回归:让数据说话数据准备:从哪里找数据编码实战:Python实现线性回归模型评估:如何判断模型好坏逻辑回归:从分类开始理论入门:什么是逻辑回归代码实现:使用skl
- 关于旗正规则引擎中的MD5加密问题
何必如此
jspMD5规则加密
一般情况下,为了防止个人隐私的泄露,我们都会对用户登录密码进行加密,使数据库相应字段保存的是加密后的字符串,而非原始密码。
在旗正规则引擎中,通过外部调用,可以实现MD5的加密,具体步骤如下:
1.在对象库中选择外部调用,选择“com.flagleader.util.MD5”,在子选项中选择“com.flagleader.util.MD5.getMD5ofStr({arg1})”;
2.在规
- 【Spark101】Scala Promise/Future在Spark中的应用
bit1129
Promise
Promise和Future是Scala用于异步调用并实现结果汇集的并发原语,Scala的Future同JUC里面的Future接口含义相同,Promise理解起来就有些绕。等有时间了再仔细的研究下Promise和Future的语义以及应用场景,具体参见Scala在线文档:http://docs.scala-lang.org/sips/completed/futures-promises.html
- spark sql 访问hive数据的配置详解
daizj
spark sqlhivethriftserver
spark sql 能够通过thriftserver 访问hive数据,默认spark编译的版本是不支持访问hive,因为hive依赖比较多,因此打的包中不包含hive和thriftserver,因此需要自己下载源码进行编译,将hive,thriftserver打包进去才能够访问,详细配置步骤如下:
1、下载源码
2、下载Maven,并配置
此配置简单,就略过
- HTTP 协议通信
周凡杨
javahttpclienthttp通信
一:简介
HTTPCLIENT,通过JAVA基于HTTP协议进行点与点间的通信!
二: 代码举例
测试类:
import java
- java unix时间戳转换
g21121
java
把java时间戳转换成unix时间戳:
Timestamp appointTime=Timestamp.valueOf(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()))
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd hh:m
- web报表工具FineReport常用函数的用法总结(报表函数)
老A不折腾
web报表finereport总结
说明:本次总结中,凡是以tableName或viewName作为参数因子的。函数在调用的时候均按照先从私有数据源中查找,然后再从公有数据源中查找的顺序。
CLASS
CLASS(object):返回object对象的所属的类。
CNMONEY
CNMONEY(number,unit)返回人民币大写。
number:需要转换的数值型的数。
unit:单位,
- java jni调用c++ 代码 报错
墙头上一根草
javaC++jni
#
# A fatal error has been detected by the Java Runtime Environment:
#
# EXCEPTION_ACCESS_VIOLATION (0xc0000005) at pc=0x00000000777c3290, pid=5632, tid=6656
#
# JRE version: Java(TM) SE Ru
- Spring中事件处理de小技巧
aijuans
springSpring 教程Spring 实例Spring 入门Spring3
Spring 中提供一些Aware相关de接口,BeanFactoryAware、 ApplicationContextAware、ResourceLoaderAware、ServletContextAware等等,其中最常用到de匙ApplicationContextAware.实现ApplicationContextAwaredeBean,在Bean被初始后,将会被注入 Applicati
- linux shell ls脚本样例
annan211
linuxlinux ls源码linux 源码
#! /bin/sh -
#查找输入文件的路径
#在查找路径下寻找一个或多个原始文件或文件模式
# 查找路径由特定的环境变量所定义
#标准输出所产生的结果 通常是查找路径下找到的每个文件的第一个实体的完整路径
# 或是filename :not found 的标准错误输出。
#如果文件没有找到 则退出码为0
#否则 即为找不到的文件个数
#语法 pathfind [--
- List,Set,Map遍历方式 (收集的资源,值得看一下)
百合不是茶
listsetMap遍历方式
List特点:元素有放入顺序,元素可重复
Map特点:元素按键值对存储,无放入顺序
Set特点:元素无放入顺序,元素不可重复(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的)
List接口有三个实现类:LinkedList,ArrayList,Vector
LinkedList:底层基于链表实现,链表内存是散乱的,每一个元素存储本身
- 解决SimpleDateFormat的线程不安全问题的方法
bijian1013
javathread线程安全
在Java项目中,我们通常会自己写一个DateUtil类,处理日期和字符串的转换,如下所示:
public class DateUtil01 {
private SimpleDateFormat dateformat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public void format(Date d
- http请求测试实例(采用fastjson解析)
bijian1013
http测试
在实际开发中,我们经常会去做http请求的开发,下面则是如何请求的单元测试小实例,仅供参考。
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.httpclient.HttpClient;
import
- 【RPC框架Hessian三】Hessian 异常处理
bit1129
hessian
RPC异常处理概述
RPC异常处理指是,当客户端调用远端的服务,如果服务执行过程中发生异常,这个异常能否序列到客户端?
如果服务在执行过程中可能发生异常,那么在服务接口的声明中,就该声明该接口可能抛出的异常。
在Hessian中,服务器端发生异常,可以将异常信息从服务器端序列化到客户端,因为Exception本身是实现了Serializable的
- 【日志分析】日志分析工具
bit1129
日志分析
1. 网站日志实时分析工具 GoAccess
http://www.vpsee.com/2014/02/a-real-time-web-log-analyzer-goaccess/
2. 通过日志监控并收集 Java 应用程序性能数据(Perf4J)
http://www.ibm.com/developerworks/cn/java/j-lo-logforperf/
3.log.io
和
- nginx优化加强战斗力及遇到的坑解决
ronin47
nginx 优化
先说遇到个坑,第一个是负载问题,这个问题与架构有关,由于我设计架构多了两层,结果导致会话负载只转向一个。解决这样的问题思路有两个:一是改变负载策略,二是更改架构设计。
由于采用动静分离部署,而nginx又设计了静态,结果客户端去读nginx静态,访问量上来,页面加载很慢。解决:二者留其一。最好是保留apache服务器。
来以下优化:
- java-50-输入两棵二叉树A和B,判断树B是不是A的子结构
bylijinnan
java
思路来自:
http://zhedahht.blog.163.com/blog/static/25411174201011445550396/
import ljn.help.*;
public class HasSubtree {
/**Q50.
* 输入两棵二叉树A和B,判断树B是不是A的子结构。
例如,下图中的两棵树A和B,由于A中有一部分子树的结构和B是一
- mongoDB 备份与恢复
开窍的石头
mongDB备份与恢复
Mongodb导出与导入
1: 导入/导出可以操作的是本地的mongodb服务器,也可以是远程的.
所以,都有如下通用选项:
-h host 主机
--port port 端口
-u username 用户名
-p passwd 密码
2: mongoexport 导出json格式的文件
- [网络与通讯]椭圆轨道计算的一些问题
comsci
网络
如果按照中国古代农历的历法,现在应该是某个季节的开始,但是由于农历历法是3000年前的天文观测数据,如果按照现在的天文学记录来进行修正的话,这个季节已经过去一段时间了。。。。。
也就是说,还要再等3000年。才有机会了,太阳系的行星的椭圆轨道受到外来天体的干扰,轨道次序发生了变
- 软件专利如何申请
cuiyadll
软件专利申请
软件技术可以申请软件著作权以保护软件源代码,也可以申请发明专利以保护软件流程中的步骤执行方式。专利保护的是软件解决问题的思想,而软件著作权保护的是软件代码(即软件思想的表达形式)。例如,离线传送文件,那发明专利保护是如何实现离线传送文件。基于相同的软件思想,但实现离线传送的程序代码有千千万万种,每种代码都可以享有各自的软件著作权。申请一个软件发明专利的代理费大概需要5000-8000申请发明专利可
- Android学习笔记
darrenzhu
android
1.启动一个AVD
2.命令行运行adb shell可连接到AVD,这也就是命令行客户端
3.如何启动一个程序
am start -n package name/.activityName
am start -n com.example.helloworld/.MainActivity
启动Android设置工具的命令如下所示:
# am start -
- apache虚拟机配置,本地多域名访问本地网站
dcj3sjt126com
apache
现在假定你有两个目录,一个存在于 /htdocs/a,另一个存在于 /htdocs/b 。
现在你想要在本地测试的时候访问 www.freeman.com 对应的目录是 /xampp/htdocs/freeman ,访问 www.duchengjiu.com 对应的目录是 /htdocs/duchengjiu。
1、首先修改C盘WINDOWS\system32\drivers\etc目录下的
- yii2 restful web服务[速率限制]
dcj3sjt126com
PHPyii2
速率限制
为防止滥用,你应该考虑增加速率限制到您的API。 例如,您可以限制每个用户的API的使用是在10分钟内最多100次的API调用。 如果一个用户同一个时间段内太多的请求被接收, 将返回响应状态代码 429 (这意味着过多的请求)。
要启用速率限制, [[yii\web\User::identityClass|user identity class]] 应该实现 [[yii\filter
- Hadoop2.5.2安装——单机模式
eksliang
hadoophadoop单机部署
转载请出自出处:http://eksliang.iteye.com/blog/2185414 一、概述
Hadoop有三种模式 单机模式、伪分布模式和完全分布模式,这里先简单介绍单机模式 ,默认情况下,Hadoop被配置成一个非分布式模式,独立运行JAVA进程,适合开始做调试工作。
二、下载地址
Hadoop 网址http:
- LoadMoreListView+SwipeRefreshLayout(分页下拉)基本结构
gundumw100
android
一切为了快速迭代
import java.util.ArrayList;
import org.json.JSONObject;
import android.animation.ObjectAnimator;
import android.os.Bundle;
import android.support.v4.widget.SwipeRefreshLayo
- 三道简单的前端HTML/CSS题目
ini
htmlWeb前端css题目
使用CSS为多个网页进行相同风格的布局和外观设置时,为了方便对这些网页进行修改,最好使用( )。http://hovertree.com/shortanswer/bjae/7bd72acca3206862.htm
在HTML中加入<table style=”color:red; font-size:10pt”>,此为( )。http://hovertree.com/s
- overrided方法编译错误
kane_xie
override
问题描述:
在实现类中的某一或某几个Override方法发生编译错误如下:
Name clash: The method put(String) of type XXXServiceImpl has the same erasure as put(String) of type XXXService but does not override it
当去掉@Over
- Java中使用代理IP获取网址内容(防IP被封,做数据爬虫)
mcj8089
免费代理IP代理IP数据爬虫JAVA设置代理IP爬虫封IP
推荐两个代理IP网站:
1. 全网代理IP:http://proxy.goubanjia.com/
2. 敲代码免费IP:http://ip.qiaodm.com/
Java语言有两种方式使用代理IP访问网址并获取内容,
方式一,设置System系统属性
// 设置代理IP
System.getProper
- Nodejs Express 报错之 listen EADDRINUSE
qiaolevip
每天进步一点点学习永无止境nodejs纵观千象
当你启动 nodejs服务报错:
>node app
Express server listening on port 80
events.js:85
throw er; // Unhandled 'error' event
^
Error: listen EADDRINUSE
at exports._errnoException (
- C++中三种new的用法
_荆棘鸟_
C++new
转载自:http://news.ccidnet.com/art/32855/20100713/2114025_1.html
作者: mt
其一是new operator,也叫new表达式;其二是operator new,也叫new操作符。这两个英文名称起的也太绝了,很容易搞混,那就记中文名称吧。new表达式比较常见,也最常用,例如:
string* ps = new string("
- Ruby深入研究笔记1
wudixiaotie
Ruby
module是可以定义private方法的
module MTest
def aaa
puts "aaa"
private_method
end
private
def private_method
puts "this is private_method"
end
end
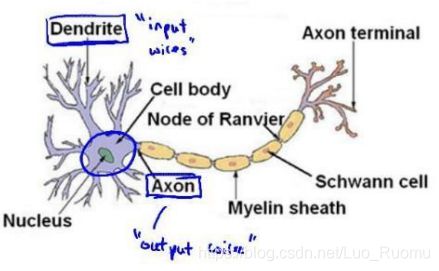
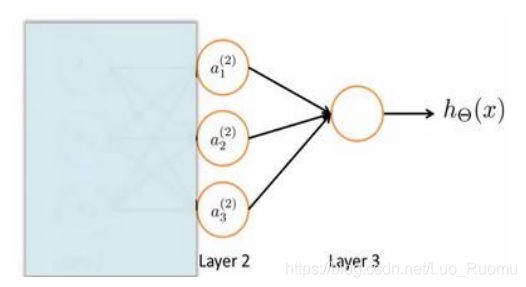
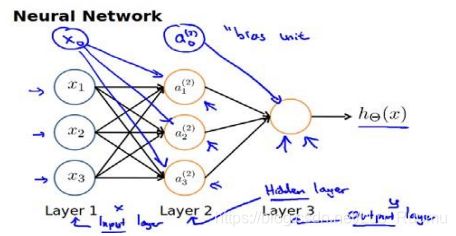 第一层成为输入层,最后一 层称为输出层,中间一层成为隐藏层
第一层成为输入层,最后一 层称为输出层,中间一层成为隐藏层 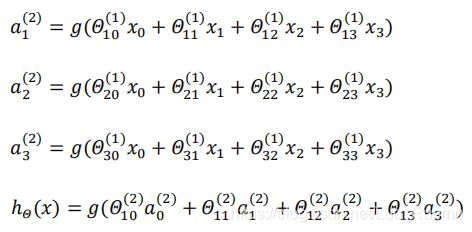 第(2)层第i个激活单元,θ权重矩阵
第(2)层第i个激活单元,θ权重矩阵
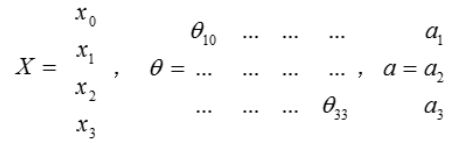 θ.X = a
θ.X = a
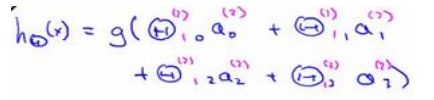
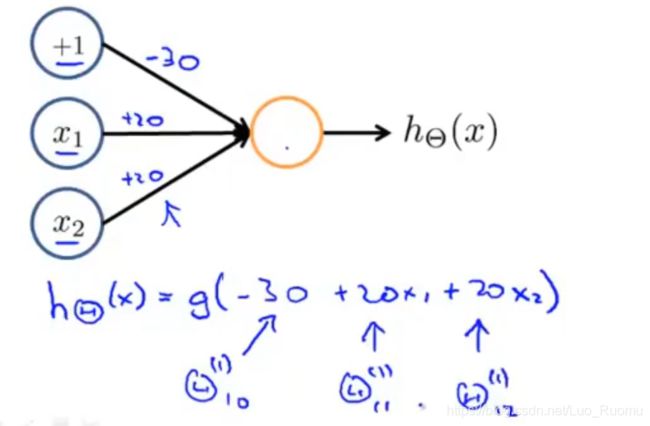
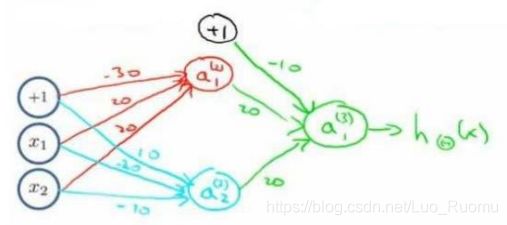 类似逻辑电路
类似逻辑电路
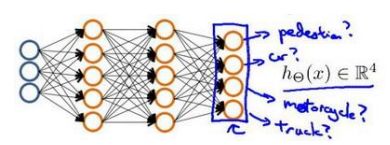
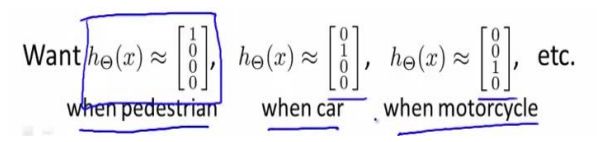



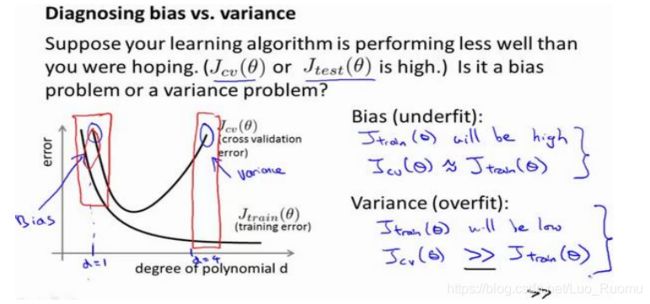
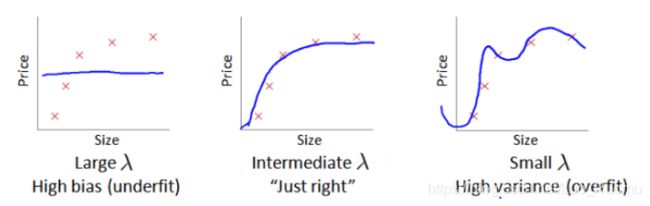
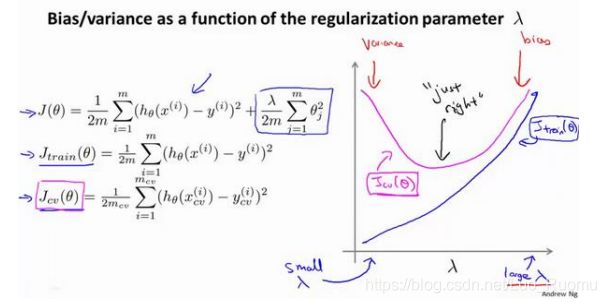
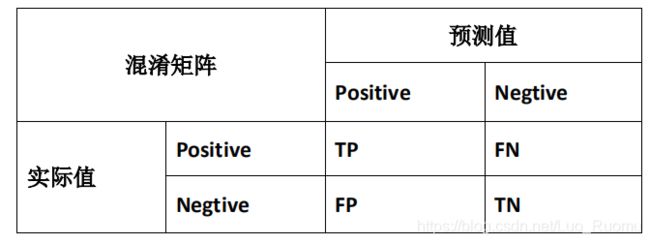
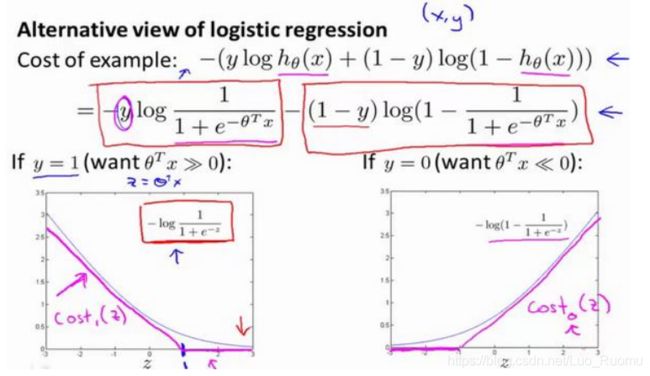
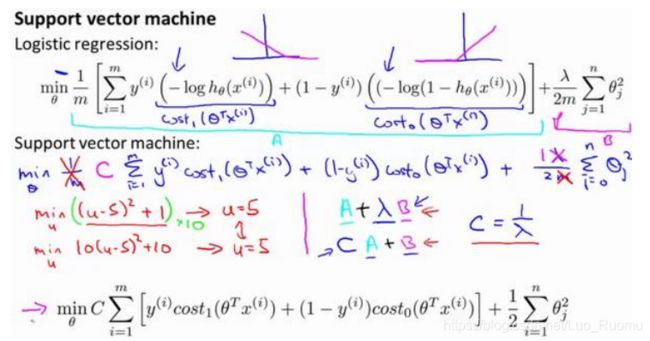

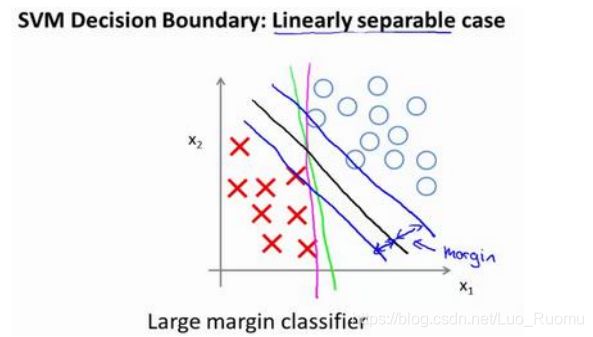
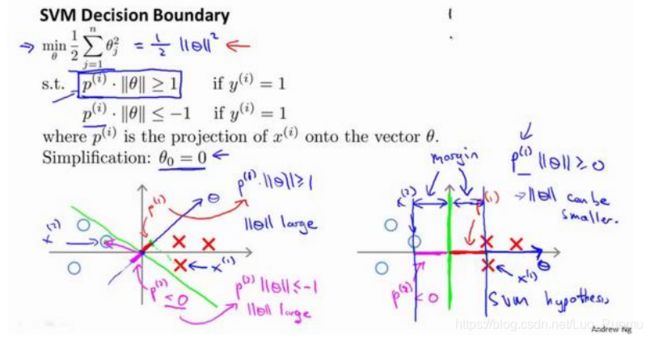
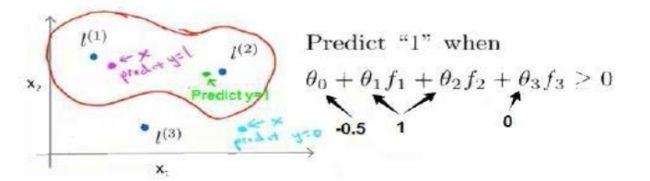 离L(1)近,f_1=1,离其他远,为0
离L(1)近,f_1=1,离其他远,为0
