【目标检测-YOLO】YOLOv5-5.0v-yaml 解析及模型构建(第二篇)
YOLOv5 中网络结构的配置使用 yaml 文件。
1. yaml 是什么?
YAML 是一种较为人性化的 数据序列化语言。YAML是"YAML Ain't a Markup Language"(YAML不是一种标记语言)的递归缩写。在开发的这种语言时,YAML 的意思其实是:"Yet Another Markup Language"(仍是一种标记语言),但为了强调这种语言以数据作为中心,而不是以标记语言为重点,而用反向缩略语重命名。
关键词:数据序列化语言、递归缩写、标记语言、
参考:If YAML ain't markup language, what is it? - Stack Overflow
计算机语言分类:机器语言、汇编语言、标记语言、脚本语言、编程语言 - panchanggui - 博客园
Advantages and Disadvantages of YAML over XML and JSON
YAML vs JSON vs XML | What is the Difference Between Them?
友善且神奇的YAML - 知乎
数据序列化导读 - 标签 - veli - 博客园
2. yolov5 yaml解析
以yolov5-5.0v-yolov5s.yaml为例。
yaml 文件读取:
import yaml # for torch hub
from pathlib import Path
cfg='yolov5-5.0/models/yolov5s.yaml'
yaml_file = Path(cfg).name # yolov5s.yaml
with open(cfg) as f:
yaml = yaml.load(f, Loader=yaml.SafeLoader) # model dict
ch = 3
print(yaml.get('ch', ch)) # dict 的get 方法, 没有'ch',则返回 chyaml.load() 后的结果为 dict,Loader参数是为了停止得到警告。其中的get 为字典的get 方法。
其中 Path 是python中用于简化路径的一个模块。
参考:
pathlib — Object-oriented filesystem paths — Python 3.10.3 documentation
Python | Path 让文件路径提取变得简单(含代码)_HinGwenWoong的博客-CSDN博客_python 文件路径截取
下面介绍解析load后的 yaml 字典。
self.yaml = {'nc': 80,
'depth_multiple': 0.33,
'width_multiple': 0.5,
'anchors': [[10, 13, 16, 30, 33, 23],
[30, 61, 62, 45, 59, 119],
[116, 90, 156, 198, 373, 326]],
# [f, n, m, args]
'backbone': [[-1, 1, 'Focus', [64, 3]], # 0-P1/2
[-1, 1, 'Conv', [128, 3, 2]], # 1-P2/4
[-1, 3, 'C3', [128]],
[-1, 1, 'Conv', [256, 3, 2]], # 3-P3/8
[-1, 9, 'C3', [256]],
[-1, 1, 'Conv', [512, 3, 2]], # 5-P4/16
[-1, 9, 'C3', [512]],
[-1, 1, 'Conv', [1024, 3, 2]], # 7-P5/32
[-1, 1, 'SPP', [1024, [5, 9, 13]]],
[-1, 3, 'C3', [1024, False]]], # 9;False 表示 shortcut = False
# [f, n, m, args]
'head': [[-1, 1, 'Conv', [512, 1, 1]],
[-1, 1, 'nn.Upsample', ['None', 2, 'nearest']],
[[-1, 6], 1, 'Concat', [1]], # cat backbone P4
[-1, 3, 'C3', [512, False]], # 13
[-1, 1, 'Conv', [256, 1, 1]],
[-1, 1, 'nn.Upsample', ['None', 2, 'nearest']],
[[-1, 4], 1, 'Concat', [1]], # cat backbone P3
[-1, 3, 'C3', [256, False]],
[-1, 1, 'Conv', [256, 3, 2]],
[[-1, 14], 1, 'Concat', [1]], # cat head P4
[-1, 3, 'C3', [512, False]], # 20 (P4/16-medium)
[-1, 1, 'Conv', [512, 3, 2]],
[[-1, 10], 1, 'Concat', [1]], # cat head P5
[-1, 3, 'C3', [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, 'Detect', ['nc', 'anchors']]]} # Detect(P3, P4, P5)f - from:表示当前模块的输入来自那一层的输出,-1表示来自上一层的输出。
n - number: 表示当前模块的理论重复次数,实际的重复次数还要由上面的参数depth_multiple共同决定,决定网络模型的深度。
m - module:模块类名,使用eval函数,通过这个类名去common.py中寻找相应的类,进行模块化的搭建网络。
args: 是一个list,模块搭建所需参数,channel,kernel_size,stride,padding,bias等。会在网络搭建过程中根据不同层进行改变
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist注意:上述调用是 deepcopy,self.yaml 是一个字典,所以是可变对象。
对于浅拷贝和深拷贝来说,如果拷贝对象都是不可变对象的话,那么两者效果是一样的。如果是可变对象的话,“=”拷贝的方式,只是拷贝了内存中的地址引用,两个对象的地址引用一样,所以两个对象的值会随着一方的修改而修改。而对于deepcopy()来说,如果是可变对象的话,那么拷贝内容后新对象的内存地址也会重新分配,跟原来的内存地址不一样了。所以两者任意修改变量的内容不会对另一方造成影响。
参考:Python中copy,deepcopy,=之深拷贝浅拷贝使用详解_mb6128917e8c03e的技术博客_51CTO博客
我们对 models/yolo.py 文件进行调试。
parse_model(d, ch) 是一个单独的函数,ch = [3] 是一个list。
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
# d['backbone'] + d['head'] 是把字典的两个元素的值连接到一起构成一个大的 list。[..., [-1, 3, 'C3', [1024, False]], [-1, 1, 'Conv', [512, 1, 1]], ...]
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings; 'None' -> None;
except:
pass # 'nearest' -> 'nearest';
n = max(round(n * gd), 1) if n > 1 else n # depth gain 控制 c3 模块的个数,round 是四舍五入,yaml文件中 c3 为3或9,所以这里c3的个数n为1或3
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
C3, C3TR]:
c1, c2 = ch[f], args[0] # ch是一个list,会记录下不同层(yaml中的m)输出的通道数;c2是yaml中 args[0],表示当前模块输出的通道数
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8) # 使用gw控制模型的宽度,也就是每层的输出通道数,这里 *0.5,也就是yaml定义的通道数减半;在utils/general.py中 math.ceil(c2 * gw / 8) * 8 向上取整,保证输出通道数是8的倍数。所以 Focus 的输出通道数变成了 32。
args = [c1, c2, *args[1:]] # *args[1:]为每个模块的 k,s 等,*list表示把list解开为多个独立的元素
if m in [BottleneckCSP, C3, C3TR]:
args.insert(2, n) # number of repeats 从位置2处插入n,n为模块的个数,会在模块中使用for循环重复多次;然后置n=1
n = 1
elif m is nn.BatchNorm2d: # yaml中不存在BN module,因此不会执行。
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[x] for x in f]) # 如果是Concat 模块,会把输入(f)通道加起来作为输出通道个数。
elif m is Detect:
args.append([ch[x] for x in f]) #[nc, anchors].append([17, 20, 23])
if isinstance(args[1], int): # number of anchors;不会执行
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract: # yaml中不存在该module,因此不会执行
c2 = ch[f] * args[0] ** 2
elif m is Expand: # yaml中不存在该module,因此不会执行
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f] # yaml中的 nn.Upsample,输出通道数和上一层的输出通道数一样
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module; n表示当前模块的个数也就是循环几次;m(*args)表示实例化一个m对象。
# 打印输出参数个数
t = str(m)[8:-2].replace('__main__.', '') # module type; 如 ""变成了 "models.common.Focus"
np = sum([x.numel() for x in m_.parameters()]) # number params; numel()函数:返回数组中元素的个数; net.parameters():是Pytorch用法,用来返回net网络中的参数,sum后就是当前的模块中参数的总数目
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist;extend函数为在list后面添加另一个序列;最后save为[6, 4, 14, 10, 17, 20, 23],也就是yaml文件中的f不是-1的那些
layers.append(m_)
if i == 0:
ch = [] # Focus为第一层,这里把 ch=[3]清空了
ch.append(c2) # ch list 添加该层输出通道个数
return nn.Sequential(*layers), sorted(save) na=3是每个检测头的anchors的个数, no = 3*(80+4+1)=255是输出的大小。
值得注意的是:
from models.common import *
print(globals()["Focus"]) #
m = eval(m) if isinstance(m, str) else m # eval strings m 本来是一个字符串类型,如 'Focus',经过eval(m) 后 变成了class类型: "
Python中的eval()函数eval(expression, globals=None, locals=None) 官方文档中的解释是,将字符串str当成有效的表达式来求值并返回计算结果。globals和locals参数是可选的,如果提供了globals参数,那么它必须是dictionary类型;如果提供了locals参数,那么它可以是任意的map对象。
python是用命名空间来记录变量的轨迹的,命名空间是一个dictionary,键是变量名,值是变量值。
当一行代码要使用变量 x 的值时,Python 会到所有可用的名字空间去查找变量,按照如下顺序:
- 1)局部命名空间 - 特指当前函数或类的方法。如果函数定义了一个局部变量 x, 或一个参数 x,Python 将使用它,然后停止搜索。
- 2)全局命名空间 - 特指当前的模块。如果模块定义了一个名为 x 的变量,函数或类,Python 将使用它然后停止搜索。
- 3)内置命名空间 - 对每个模块都是全局的。作为最后的尝试,Python 将假设 x 是内置函数或变量。
python的全局名字空间存储在一个叫globals()的dict对象中;局部名字空间存储在一个叫locals()的dict对象中。我们可以用print(locals())来查看该函数体内的所有变量名和变量值。
因此上面的 eval(m) 在全局命名空间找到了 字符串如 'Focus'。也就是当前 yolo.py 中的 from models.common import * 中,也就是 models/common.py中的 class Focus。
在eval("字符串") 函数中,如果字符串是一个类名字,例如: 'models.common.Focus'
那么 eval('models.common.Focus')就是一个Focus类,eval('models.common.Focus')() 就可以创建一个类的实例。
参考:Python中eval的使用 - 元宝向前 - 博客园
3. yolov5-5.0v-yolov5s.yaml 各模块解析
3.1 Conv
Conv 是 yolov5中的最核心模块,代码如下:
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity()) # nn.Identity() 表示直接返回,啥都不干
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))注意:
当 不指定 p时,Conv2d 的pad 值是让 k//2(除法向下取整)计算得到的(aotopad函数)。有以下两种情况:
当s=1时候,显然经过 Conv2d后特征的大小不变;
当s=2时候,那么经过 Conv2d后特征的大小减半;
附计算公式:

Conv分两种情况:
- Conv2d + BatchNorm2d + SiLU(forward),Conv2d没有bias

- Conv2d + SiLU(fuseforward)
后者在模型导出(models/export.py)、推理(detect.py)、测试(test.py)以及训练(train.py)测试阶段时候把 Conv2d + BatchNorm2d 融合为 Conv2d。
models/experimental.py-attempt_load函数中调用了fuse函数:
model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().fuse().eval()) # FP32 model
fuse函数定义在models/yolo.py中:
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
print('Fusing layers... ')
for m in self.model.modules():
if type(m) is Conv and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.fuseforward # update forward
self.info()
return self在上述代码中:判断 m是否为带bn的Conv(conv2d+bn+silu),若是则融合conv2d+bn, 替换Conv的conv,然后把bn移除,替换Conv的forward 为 fuseforward ,也就是 上述的情况2:conv2d + silu。
其中 融合conv2d+bn 的函数 fuse_conv_and_bn(conv, bn) 定义在utils/torch_utils.py中。
def fuse_conv_and_bn(conv, bn):
# Fuse convolution and batchnorm layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
fusedconv = nn.Conv2d(conv.in_channels,
conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
groups=conv.groups,
bias=True).requires_grad_(False).to(conv.weight.device)
# prepare filters
w_conv = conv.weight.clone().view(conv.out_channels, -1)
w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
# prepare spatial bias
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
return fusedconv代码理解:博客翻译:利用融合conv和bn的方法加速模型_星魂非梦的博客-CSDN博客
3.2 Focus
前世今生:yolov2中的Neck的passthrough层 ,Swin Transformer 中的 Patch Merging 我认为和yolov5中的Focus一样,都是用来downsample。
示意图:

Netron可视化:
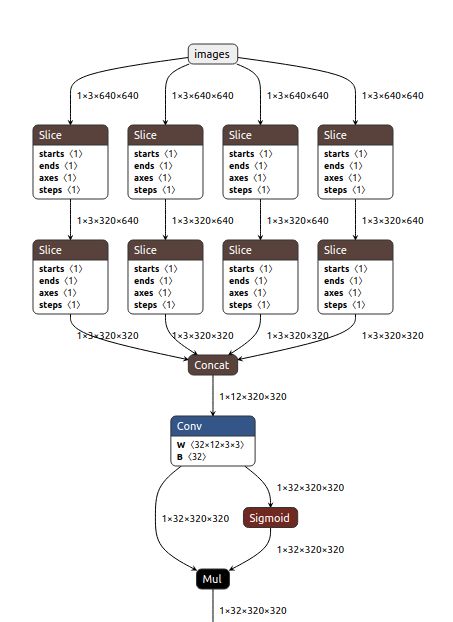
代码:models/common.py
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))理解:
- 切片:
x[..., ::2, ::2], 红色图 w, h 从0开始,每隔一个切一个
x[..., 1::2, ::2], 黄色图 w 从1开始, h 从0开始,每隔一个切一个
x[..., ::2, 1::2], 绿色图 w 从0开始, h 从1开始,每隔一个切一个
x[..., 1::2, 1::2] 蓝色图 w, h 从1开始,每隔一个切一个
2. cat:从通道维度(1)拼接,得到 (1,12,320,320)
3. CBS: yaml中:[-1, 1, Focus, [64, 3]];c2 = 62*0.5 = 32;得到 (1,32,320,320)
3.3 C3
C3 模块一共分为两种,通过yaml文件中的 shortcut=True or False 确定:
- C3_x

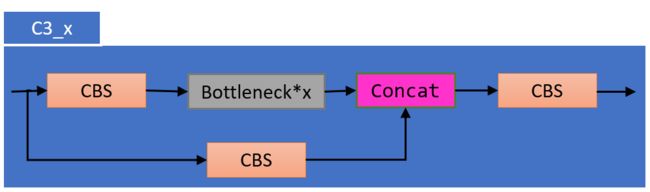
- C3_x_F


以上 x 表示 有几个 Bottleneck 模块。大写F表示 shortcut = False。
代码:models/common.py
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))3.4 SPP

代码:models/common.py
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))3.5 nn.Upsample
nn.Upsample-nearest

3.6 Concat
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super(Concat, self).__init__()
self.d = dimension # 从哪个维度拼接,yaml中都是通道维度也就是维度1
def forward(self, x):
return torch.cat(x, self.d)3.7 Detect
代码:
args = [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
nc = 80;
anchors= [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]];
ch = [128, 256, 512].
当yolov5/export.py模型时候:
因为推理返回的不是归一化后的网格偏移量 需要再加上网格的位置 得到最终的推理坐标下图中的output。 再送入nms。因此导出的模型有下图中4个输出(红色部分)。

想去掉另外右上角三个输出可以修改代码:
# return x if self.training else (torch.cat(z, 1), x)
return x if self.training else torch.cat(z, 1)当训练模型时候:
直接返回上图右上角红色部分的3个输出。
class Detect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
self.nc = nc # number of classes 多少类 nc = 80
self.no = nc + 5 # number of outputs per anchor 每个anchor的输出个数(80类+4坐标+1置信度) no = 85
self.nl = len(anchors) # number of detection layers 几个检测head 这里 nl = 3
self.na = len(anchors[0]) // 2 # number of anchors 每个cell 有几个 anchor nl = 3
self.grid = [torch.zeros(1)] * self.nl # init grid # grid = [tensor([0.]), tensor([0.]), tensor([0.])]
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
# a=tensor([[[ 10., 13.],
# [ 16., 30.],
# [ 33., 23.]],
# [[ 30., 61.],
# [ 62., 45.],
# [ 59., 119.]],
# [[116., 90.],
# [156., 198.],
# [373., 326.]]])
self.register_buffer('anchors', a) # shape(nl,na,2)
# register_buffer
# 模型中需要保存的参数一般有两种:一种是反向传播需要被optimizer更新的,称为parameter; 另一种不要被更新称为buffer
# buffer的参数更新是在forward中,而optim.step只能更新nn.parameter类型的参数
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
# output conv 对每个输出的feature map都要调用一次conv1x1 用于通道降维到 3*85
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
# bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
bs, _, ny, nx = map(int, x[i].shape)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# 如果想要断开这两个变量之间的依赖(x本身是contiguous的),就要使用contiguous()针对x进行变化,感觉上就是我们认为的深拷贝。当调用contiguous()时,会强制拷贝一份tensor,让它的布局和从头创建的一模一样,但是两个tensor完全没有联系。
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]: # 后者是当前head 的特征图大小 如 20,20
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy 这里y: (bs,3,20,20,85) 85为 (x,y,w,h,confidence,80个类)。所以0:2 为 x,y。2:4为w,h。+ self.grid[i]获得网格的坐标;*self.stride[i] 映射到原图的x,y坐标
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh power method
# y[..., 2:4] = torch.exp(y[..., 2:4]) * self.anchor_wh # wh yolo method
# z.append(y.view(bs, -1, self.no))
z.append(y.view(-1, int(y.size(1) * y.size(2) * y.size(3)), self.no)) # 把-1放在 bs 维度
return x if self.training else (torch.cat(z, 1), x)
@staticmethod
def _make_grid(nx=20, ny=20): # 创建一个网格 与当前 head 的输出大小一样
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
上图中虚线框为 Anchor box,蓝色框为预测框,网络输出的是 tw, th,经过上述变换得到了预测框bw, bh。
cx, cy 为代码中的 self.grid[i]。self.stride[i](模型的下采样步长:32,16,8)表示把当前值映射到原图。
虚线框 Anchor box也就是代码中的 self.anchor_grid[i],也就是上图公式中的 pw和ph。
x,y 的预测被乘以2并减去了0.5,所以这里的值域从yolov3里的(0,1)注意是开区间,变成了(-0.5, 1.5)。从表面理解是yolov5可以跨半个格点预测了,这样可以提高对格点周围的bbox的召回。当然还有一个好处就是也解决了yolov3中因为sigmoid开区间而导致中心无法到达边界处的问题。
pw和ph的回归的值域从基于anchor宽高(yolov2/3:
)的(0,+∞)变成了(yolov5:
)(0,4)。通过sigmoid约束,让回归的框比例尺寸更为合理,训练更稳定。
上图来自:yolov5深度剖析+源码debug级讲解系列(三)yolov5 head源码解析_吸欧大王的博客-CSDN博客_yolov5源码
4. 以上模块组合构成 yolov5s
运行 python models/yolo.py 得到以下输出:
from n params module arguments
0 -1 1 3520 models.common.Focus [3, 32, 3]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 1 156928 models.common.C3 [128, 128, 3]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 1 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 656896 models.common.SPP [512, 512, [5, 9, 13]]
9 -1 1 1182720 models.common.C3 [512, 512, 1, False]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 229245 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 283 layers, 7276605 parameters, 7276605 gradients, 17.1 GFLOPS由以上各组件内容画出以下的 yolov5s 架构图。

之前画的图没有参考代码,该图才是最准确的图像。原始的 yaml 中 把 Neck + Detect 都称为head。
Backbone 中的 CBS: 都是用来降采样的,宽高减半,通道数加倍。
Neck中的CBS:10、14是通道减半,宽高不变;18、21是 通道不变,宽高减半。
Detect 中的 conv2d 是把上一层输出的通道数映射为:3*(80+4+1) 维度。
5. yolov5-v5.0 四种网络(s、m、l、x)
用衣服的尺码来表示网络的大小也挺有意思。
yolov5通过配置 yaml 文件,得到不同的网络。但是不同的yaml的区别只是:
models/yolov5s.yaml
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
models/yolov5m.yaml
depth_multiple: 0.67
width_multiple: 0.75
models/yolov5l.yaml
depth_multiple: 1.0
width_multiple: 1.0
models/yolov5x.yaml
depth_multiple: 1.33
width_multiple: 1.25 depth_multiple 用来控制网络的深度; width_multiple 用来控制每层的通道数
5.1 四种网络的深度
models/yolo.py-parse_model(d, ch)中:
gd = d['depth_multiple']
n = max(round(n * gd), 1) if n > 1 else n # depth gain其中, n 为 yaml 中的 number 列。

5.2 四种网络的宽度
width_multiple 用来控制每层的通道数;也就是下面代码中的 gw。
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
C3, C3TR]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8) # 保证8的倍数
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR]:
args.insert(2, n) # number of repeats
n = 1通过以上 gw 控制每层的输出通道数。下面代码保证是 divisor 的倍数。
def make_divisible(x, divisor):
# Returns x evenly divisible by divisor
return math.ceil(x / divisor) * divisor在上面架构图中,Backbone 中的 CBS 都是 下采样的,即宽高减半,通道加倍。一共四个CBS,所以,四种类型的网络的通道数:
models/yolov5s.yaml # 0.5
32 -> 64 -> 128 -> 256 -> 512
models/yolov5m.yaml # 0.75
48 -> 96 -> 192 -> 384 -> 768
models/yolov5l.yaml # 1
64 -> 128 -> 256 -> 512 -> 1024
models/yolov5x.yaml # 1.25
80 -> 160 -> 320 -> 640 -> 1280