【论文阅读】Maskformer:Per-Pixel Classification is Not All You Need for Semantic Segmentation
文章目录
- 一、引言:像素级分类v.s.掩膜分类:
- 二、论文概述
- 三、代码实现
-
- pixel-level module
- transformer module
- segmentation module
- 损失函数
一、引言:像素级分类v.s.掩膜分类:
分割领域有两个大框架,一方面是像素级分类(per-pixel classification)统治语义分割领域,另一方面是以Mask-FCN为首的掩膜分类(mask classification)统治实例分割、全景分割领域。
像素级分类(per-pixel classification):分类损失应用于每个输出像素,将预测图像划分为不同类别的区域;
掩膜分类(mask classification):基于mask的方法不对每个像素进行分类,而是预测一组二进制掩码,每个掩预测一个单一的类别。
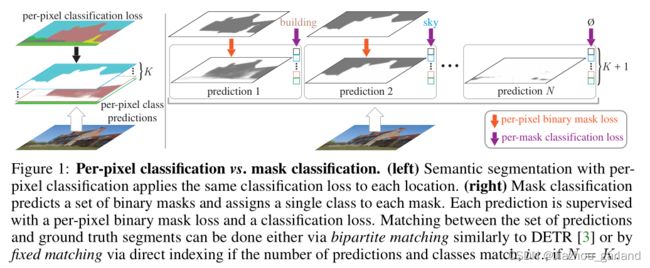
二、论文概述
参考资料:作者知乎亲自写的简介、《MaskFormer:使用Mask分类实现语义分割》
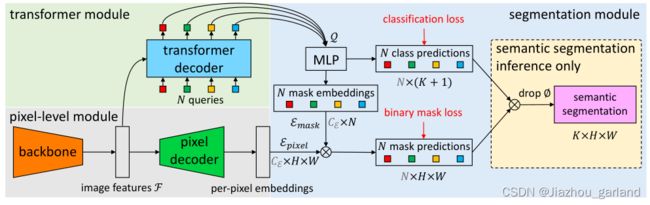
MaskFormer的结构如上图所示,主要可以分为三个部分:
- pixel-level module:用来提取每个像素embedding(灰色背景部分)
- transformer module:用来计算N个segment的embedding(绿色背景部分)
- segmentation module:根据上面的per-pixel embedding和per-segment embedding,生成预测结果。(蓝色背景部分)
三、代码实现
pixel-level module
基于pytorch的Swim Transformer代码实现与讲解
Swin Transformer中的mask机制
transformer module
这一部分从torch.nn.Transformer复制粘贴,具体实现在此, 位置编码实现在此,并进行以下修改:
- 在MultiheadAttention中使用位置编码
- 删除了编码器末尾的额外LN
- 解码器返回所有解码层的激活后的特征
即实现了下图所示部分:

参数细节:

segmentation module
本小节涉及代码位置
- 分类
即实现下图所示部分:
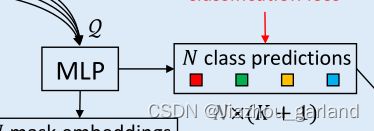
在看了源代码之后,怀疑这里图画错了,分类这里直接用的transformer module产出特征图,并没有过MLP。
鉴于自己水平不高,另有高见的朋友麻烦告诉我一下。
# hs是transformer module出来的特征,维度大小是[batche_size, queries, embed]
if self.mask_classification:
outputs_class = self.class_embed(hs) # 对hs做了一个线性变换
out = {"pred_logits": outputs_class[-1]}
上述代码第二行在init中定义如下:
if self.mask_classification:
self.class_embed = nn.Linear(hidden_dim, num_classes + 1) # [batche_size, queries, K+1]
# queries就是原文中说的transformer decoder产出的N个分割块的embedding
# K+1个预测类别,加的那个一是背景单独作为一个类别
- 分割
即实现下图所示部分:
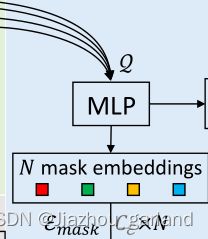
具体实现如下:
# hs是transformer module出来的特征,维度大小是[batche_size, queries, embed]
# mask_features是decoder模块输出per-pixel embeddings,维度大小是[batche_size, c, h, w]
# 注意c就是原文中mask embeddings $\epsilon_{mask}$,是个可调参数
mask_embed = self.mask_embed(hs[-1]) # 先对输出特征过一个MLP
outputs_seg_masks = torch.einsum("bqc,bchw->bqhw", mask_embed, mask_features) # 多维矩阵相乘得到mask
out["pred_masks"] = outputs_seg_masks # out字典关键字赋值
ϵ m a s k \epsilon_{mask} ϵmask的参数细节:

第一行的self.mask_embed在init中定义:
self.mask_embed = MLP(hidden_dim, hidden_dim, mask_dim, 3)
上述实例化的MLP(多层感知机)代码如下:
class MLP(nn.Module):
"""Very simple multi-layer perceptron (also called FFN)"""
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim])
)
def forward(self, x):
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
return x
损失函数
损失函数实现如下:
# bipartite matching-based loss
losses = self.criterion(outputs, targets)
for k in list(losses.keys()):
if k in self.criterion.weight_dict:
losses[k] *= self.criterion.weight_dict[k]
else:
# remove this loss if not specified in `weight_dict`
losses.pop(k)
上述代码第一行self.criterion在类函数中定义如下,具体代码地址:
criterion = SetCriterion(
sem_seg_head.num_classes,
matcher=matcher,
weight_dict=weight_dict,
eos_coef=no_object_weight,
losses=losses,
)
上述代码第三行self.criterion在类函数中定义如下, 具体代码地址:
matcher = HungarianMatcher(
cost_class=1,
cost_mask=mask_weight,
cost_dice=dice_weight,
)