PspNet在MMsegmentation框架下成功训练Pascal VOC2012数据集及踩坑实录
时间:2021/08/29/05:45:28
一晚上了,难以置信,我竟然还不困,还有着整理博客的冲动。也就在这周,熬夜能力突然就在几个晚上的不归宿中突破了,一夜过后天壤之别,一晚比一晚能熬,之前还会担心第二天精神不济,五点左右赶紧溜回去补觉,现在只想早餐要吃什么,睡什么觉,月亮不睡我不睡,月亮睡了,我也不睡,现在这个年纪,你也能睡得着觉?!!!!!!
言归正传,第一次跑起来语义分割网络,多少还是有点小兴奋,毕竟目标检测还是手把手从环境安装、网络配置、样本制作被带过来的,有点小经验,在自己的小摸索之下,得到了小小的前进吧,一点小收获。
主要遇到的问题:
一个是对语义分割的数据集制作不清楚,找了一些公开数据集,但是内部数据格式不完全规范,还需要代码辅助生成标准数据集,这里在坑里呆的久了点。
其次就是训练的时候出了个小问题导致没有开始训练就异常中断了,这个搜了一下,分分钟就解决了。
感觉还是个人能力不太行,这看起来都是小问题,就是当时没有直击弊害,导致时间耗费较多,可能是个人比较怕困难吧。下面说一下问题的解决。
对于语义分割的数据集,你要有一个清楚的认识,它的样本含jpg图片、jpg分类图片(标注后生成的)、jpg标注后生成的xml和txt文件。根据训练需求确定必需的文件。

先介绍一下官方提供的Pascal VOC2012数据集,它的构成如下:
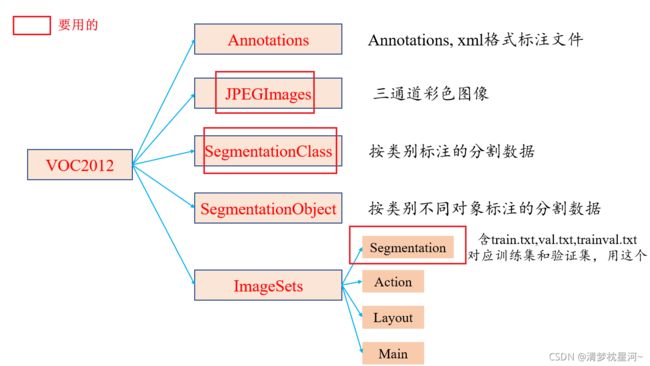
下载得到Pascal voc2012数据集(网址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar)解压后,按照官方的数据集格式放置,如下(原图略有干扰):
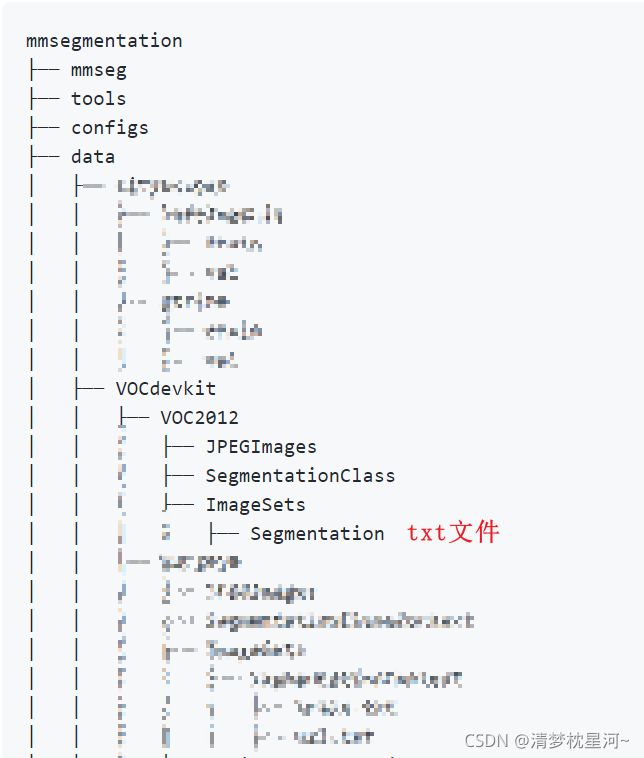
以这个位置放好数据后,就可以运行mmseg官方给出的相应生成数据集的代码,但是,代码里我遇到报错,改了一下就没问题了,不知道是不是好的修改,总之跑起来了就没细看了,代码如下:

# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import os.path as osp
from functools import partial
import mmcv
import numpy as np
from PIL import Image
from scipy.io import loadmat
AUG_LEN = 10582 **我把这里改了之后就没报错了,这个换成aug_train_list的实际数字大小,
看看具体大小,最好自己调试一下,我调出来是1464**
def convert_mat(mat_file, in_dir, out_dir):
data = loadmat(osp.join(in_dir, mat_file))
mask = data['GTcls'][0]['Segmentation'][0].astype(np.uint8)
seg_filename = osp.join(out_dir, mat_file.replace('.mat', '.png'))
Image.fromarray(mask).save(seg_filename, 'PNG')
...其余和官网一致
运行指令:
# --nproc means 8 process for conversion, which could be omitted as well.
python tools/convert_datasets/voc_aug.py data/VOCdevkit data/VOCdevkit/VOCaug
顺利执行完上述指令,就可以着手训练了,当然你要跑什么网络你要自己配置一下:
比如,跑pspnet,可以自己在mmsegmentation/my_model/pspnet专门建一个文件用来进行配置,先在configs/pspnet找到你要跑的网络,根据这个网络需要的配置文件,dataset、model、schedules等放在pspnet下面就完成了基本的配置。
接下来就可以开始跑了,我现在只有一张卡(GPU),所以不能跑多进程,训练指令如下:
python tools/train.py mmsegmentation/my_model/pspnet/...coco.py
结果报错了,原来我跑的网络默认使用多进程,导致异常卡死了(core dumped),改一个地方就行,找到你的网络pspnet/model/xx.py的如下位置:
norm_cfg = dict(type='SyncBN', requires_grad=True)
把SyncBN换成BN就行,把多进程换成单进程:
norm_cfg = dict(type='BN', requires_grad=True)
我的运行情况如下,我觉得我对样本那块还是没有理解透彻,后面再捋捋吧:
(mmseg) root@k8s-deploy-wqssem-1624892297649-8599c8f79f-4x694:/nfs/private/mmsegmentation# python demo/image_demo.py demo/demo.png configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth
Use load_from_local loader
Segmentation fault (core dumped)
(mmseg) root@k8s-deploy-wqssem-1624892297649-8599c8f79f-4x694:/nfs/private/mmsegmentation#
(mmseg) root@k8s-deploy-wqssem-1624892297649-8599c8f79f-4x694:/nfs/private/mmsegmentation# python tools/train.py ./exp-for-mine/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py
2021-08-29 05:24:45,132 - mmseg - INFO - Environment info:
------------------------------------------------------------
sys.platform: linux
Python: 3.7.11 (default, Jul 27 2021, 14:32:16) [GCC 7.5.0]
CUDA available: True
GPU 0: TITAN Xp
CUDA_HOME: /usr/local/cuda
NVCC: Cuda compilation tools, release 10.0, V10.0.130
GCC: gcc (Ubuntu 5.4.0-6ubuntu1~16.04.12) 5.4.0 20160609
PyTorch: 1.8.1
PyTorch compiling details: PyTorch built with:
- GCC 7.3
- C++ Version: 201402
- Intel(R) oneAPI Math Kernel Library Version 2021.3-Product Build 20210617 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v1.7.0 (Git Hash 7aed236906b1f7a05c0917e5257a1af05e9ff683)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 10.1
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_37,code=compute_37
- CuDNN 7.6.3
- Magma 2.5.2
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=10.1, CUDNN_VERSION=7.6.3, CXX_COMPILER=/opt/rh/devtoolset-7/root/usr/bin/c++, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.8.1, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON,
TorchVision: 0.9.1
OpenCV: 4.5.3
MMCV: 1.3.7
MMCV Compiler: GCC 5.4
MMCV CUDA Compiler: 10.0
MMSegmentation: 0.16.0+aa438f5
------------------------------------------------------------
2021-08-29 05:24:45,134 - mmseg - INFO - Distributed training: False
2021-08-29 05:24:45,573 - mmseg - INFO - Config:
norm_cfg = dict(type='BN', requires_grad=True)
model = dict(
type='EncoderDecoder',
pretrained='open-mmlab://resnet50_v1c',
backbone=dict(
type='ResNetV1c',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
dilations=(1, 1, 2, 4),
strides=(1, 2, 1, 1),
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=False,
style='pytorch',
contract_dilation=True),
decode_head=dict(
type='PSPHead',
in_channels=2048,
in_index=3,
channels=512,
pool_scales=(1, 2, 3, 6),
dropout_ratio=0.1,
num_classes=19,
norm_cfg=dict(type='BN', requires_grad=True),
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=1024,
in_index=2,
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=dict(type='BN', requires_grad=True),
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
train_cfg=dict(),
test_cfg=dict(mode='whole'))
dataset_type = 'PascalVOCDataset'
data_root = 'data/VOCdevkit/VOC2012'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(512, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=(512, 512), cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size=(512, 512), pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(512, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(
type='PascalVOCDataset',
data_root='data/VOCdevkit/VOC2012',
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/train.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(512, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=(512, 512), cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size=(512, 512), pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
]),
val=dict(
type='PascalVOCDataset',
data_root='data/VOCdevkit/VOC2012',
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(512, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='PascalVOCDataset',
data_root='data/VOCdevkit/VOC2012',
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(512, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
log_config = dict(
interval=50, hooks=[dict(type='TextLoggerHook', by_epoch=False)])
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
cudnn_benchmark = True
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
optimizer_config = dict()
lr_config = dict(policy='poly', power=0.9, min_lr=0.0001, by_epoch=False)
runner = dict(type='IterBasedRunner', max_iters=40000)
checkpoint_config = dict(by_epoch=False, interval=4000)
evaluation = dict(interval=4000, metric='mIoU', pre_eval=True)
work_dir = './work_dirs/pspnet_r50-d8_512x1024_40k_cityscapes'
gpu_ids = range(0, 1)
/nfs/private/mmsegmentation/mmseg/models/backbones/resnet.py:428: UserWarning: DeprecationWarning: pretrained is a deprecated, please use "init_cfg" instead
warnings.warn('DeprecationWarning: pretrained is a deprecated, '
2021-08-29 05:24:46,328 - mmcv - INFO - load model from: open-mmlab://resnet50_v1c
2021-08-29 05:24:46,328 - mmcv - INFO - Use load_from_openmmlab loader
2021-08-29 05:24:46,473 - mmcv - WARNING - The model and loaded state dict do not match exactly
unexpected key in source state_dict: fc.weight, fc.bias
/root/anaconda3/envs/mmseg/lib/python3.7/site-packages/mmcv/cnn/utils/weight_init.py:119: UserWarning: init_cfg without layer key, if you do not define override key either, this init_cfg will do nothing
'init_cfg without layer key, if you do not define override'
2021-08-29 05:24:46,909 - mmseg - INFO - EncoderDecoder(
(backbone): ResNetV1c(
(stem): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
)
init_cfg={'type': 'Pretrained', 'checkpoint': 'open-mmlab://resnet50_v1c'}
(decode_head): PSPHead(
input_transform=None, ignore_index=255, align_corners=False
(loss_decode): CrossEntropyLoss()
(conv_seg): Conv2d(512, 19, kernel_size=(1, 1), stride=(1, 1))
(dropout): Dropout2d(p=0.1, inplace=False)
(psp_modules): PPM(
(0): Sequential(
(0): AdaptiveAvgPool2d(output_size=1)
(1): ConvModule(
(conv): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(1): Sequential(
(0): AdaptiveAvgPool2d(output_size=2)
(1): ConvModule(
(conv): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(2): Sequential(
(0): AdaptiveAvgPool2d(output_size=3)
(1): ConvModule(
(conv): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(3): Sequential(
(0): AdaptiveAvgPool2d(output_size=6)
(1): ConvModule(
(conv): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
(bottleneck): ConvModule(
(conv): Conv2d(4096, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
init_cfg={'type': 'Normal', 'std': 0.01, 'override': {'name': 'conv_seg'}}
(auxiliary_head): FCNHead(
input_transform=None, ignore_index=255, align_corners=False
(loss_decode): CrossEntropyLoss()
(conv_seg): Conv2d(256, 19, kernel_size=(1, 1), stride=(1, 1))
(dropout): Dropout2d(p=0.1, inplace=False)
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(1024, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
init_cfg={'type': 'Normal', 'std': 0.01, 'override': {'name': 'conv_seg'}}
)
2021-08-29 05:24:46,932 - mmseg - INFO - Loaded 1464 images
2021-08-29 05:24:51,631 - mmseg - INFO - Loaded 1449 images
2021-08-29 05:24:51,632 - mmseg - INFO - Start running, host: root@k8s-deploy-wqssem-1624892297649-8599c8f79f-4x694, work_dir: /nfs/private/mmsegmentation/work_dirs/pspnet_r50-d8_512x1024_40k_cityscapes
2021-08-29 05:24:51,633 - mmseg - INFO - workflow: [('train', 1)], max: 40000 iters
2021-08-29 05:25:32,794 - mmseg - INFO - Iter [50/40000] lr: 9.989e-03, eta: 9:00:24, time: 0.812, data_time: 0.044, memory: 7603, decode.loss_seg: 1.0363, decode.acc_seg: 45.8973, aux.loss_seg: 0.4420, aux.acc_seg: 45.1200, loss: 1.4783
2021-08-29 05:26:05,793 - mmseg - INFO - Iter [100/40000] lr: 9.978e-03, eta: 8:09:18, time: 0.660, data_time: 0.007, memory: 7603, decode.loss_seg: 0.9552, decode.acc_seg: 46.7384, aux.loss_seg: 0.3801, aux.acc_seg: 46.6537, loss: 1.3353
2021-08-29 05:26:39,061 - mmseg - INFO - Iter [150/40000] lr: 9.967e-03, eta: 7:53:05, time: 0.665, data_time: 0.006, memory: 7603, decode.loss_seg: 0.8589, decode.acc_seg: 49.3040, aux.loss_seg: 0.3501, aux.acc_seg: 48.7704, loss: 1.2090
2021-08-29 05:27:12,109 - mmseg - INFO - Iter [200/40000] lr: 9.956e-03, eta: 7:43:59, time: 0.661, data_time: 0.007, memory: 7603, decode.loss_seg: 0.7557, decode.acc_seg: 51.4131, aux.loss_seg: 0.3250, aux.acc_seg: 50.8509, loss: 1.0807
2021-08-29 05:27:45,702 - mmseg - INFO - Iter [250/40000] lr: 9.945e-03, eta: 7:39:44, time: 0.672, data_time: 0.006, memory: 7603, decode.loss_seg: 0.8035, decode.acc_seg: 49.5761, aux.loss_seg: 0.3529, aux.acc_seg: 48.6321, loss: 1.1564
2021-08-29 05:28:18,991 - mmseg - INFO - Iter [300/40000] lr: 9.933e-03, eta: 7:36:03, time: 0.666, data_time: 0.007, memory: 7603, decode.loss_seg: 0.7953, decode.acc_seg: 45.9399, aux.loss_seg: 0.3519, aux.acc_seg: 44.7584, loss: 1.1472
2021-08-29 05:28:52,232 - mmseg - INFO - Iter [350/40000] lr: 9.922e-03, eta: 7:33:10, time: 0.665, data_time: 0.006, memory: 7603, decode.loss_seg: 0.7948, decode.acc_seg: 50.9613, aux.loss_seg: 0.3574, aux.acc_seg: 49.7895, loss: 1.1522
2021-08-29 05:29:27,901 - mmseg - INFO - Iter [400/40000] lr: 9.911e-03, eta: 7:34:52, time: 0.713, data_time: 0.043, memory: 7603, decode.loss_seg: 0.7284, decode.acc_seg: 50.9671, aux.loss_seg: 0.3482, aux.acc_seg: 49.3723, loss: 1.0766
2021-08-29 05:30:01,397 - mmseg - INFO - Iter [450/40000] lr: 9.900e-03, eta: 7:32:53, time: 0.670, data_time: 0.006, memory: 7603, decode.loss_seg: 0.6057, decode.acc_seg: 55.5479, aux.loss_seg: 0.3009, aux.acc_seg: 53.0798, loss: 0.9066
2021-08-29 05:30:34,741 - mmseg - INFO - Iter [500/40000] lr: 9.889e-03, eta: 7:30:59, time: 0.667, data_time: 0.006, memory: 7603, decode.loss_seg: 0.6258, decode.acc_seg: 49.7284, aux.loss_seg: 0.3041, aux.acc_seg: 47.9995, loss: 0.9299
2021-08-29 05:31:08,198 - mmseg - INFO - Iter [550/40000] lr: 9.878e-03, eta: 7:29:28, time: 0.669, data_time: 0.007, memory: 7603, decode.loss_seg: 0.6351, decode.acc_seg: 54.8636, aux.loss_seg: 0.3146, aux.acc_seg: 52.2358, loss: 0.9497
2021-08-29 05:31:41,692 - mmseg - INFO - Iter [600/40000] lr: 9.866e-03, eta: 7:28:08, time: 0.670, data_time: 0.006, memory: 7603, decode.loss_seg: 0.6320, decode.acc_seg: 55.1720, aux.loss_seg: 0.3079, aux.acc_seg: 53.1876, loss: 0.9399
2021-08-29 05:32:15,345 - mmseg - INFO - Iter [650/40000] lr: 9.855e-03, eta: 7:27:06, time: 0.673, data_time: 0.006, memory: 7603, decode.loss_seg: 0.6433, decode.acc_seg: 54.4495, aux.loss_seg: 0.2987, aux.acc_seg: 52.7829, loss: 0.9421
2021-08-29 05:32:49,039 - mmseg - INFO - Iter [700/40000] lr: 9.844e-03, eta: 7:26:10, time: 0.674, data_time: 0.006, memory: 7603, decode.loss_seg: 0.6603, decode.acc_seg: 53.6086, aux.loss_seg: 0.3270, aux.acc_seg: 50.7462, loss: 0.9872
2021-08-29 05:33:24,346 - mmseg - INFO - Iter [750/40000] lr: 9.833e-03, eta: 7:26:41, time: 0.706, data_time: 0.046, memory: 7603, decode.loss_seg: 0.6054, decode.acc_seg: 55.7598, aux.loss_seg: 0.3070, aux.acc_seg: 52.9001, loss: 0.9124
2021-08-29 05:33:57,742 - mmseg - INFO - Iter [800/40000] lr: 9.822e-03, eta: 7:25:30, time: 0.668, data_time: 0.006, memory: 7603, decode.loss_seg: 0.5071, decode.acc_seg: 51.1340, aux.loss_seg: 0.2809, aux.acc_seg: 47.9697, loss: 0.7879
2021-08-29 05:34:31,597 - mmseg - INFO - Iter [850/40000] lr: 9.811e-03, eta: 7:24:45, time: 0.677, data_time: 0.007, memory: 7603, decode.loss_seg: 0.5503, decode.acc_seg: 57.1445, aux.loss_seg: 0.2985, aux.acc_seg: 53.4582, loss: 0.8488
2021-08-29 05:35:05,391 - mmseg - INFO - Iter [900/40000] lr: 9.800e-03, eta: 7:23:58, time: 0.676, data_time: 0.006, memory: 7603, decode.loss_seg: 0.6008, decode.acc_seg: 52.3851, aux.loss_seg: 0.2968, aux.acc_seg: 49.7548, loss: 0.8976