【机器学习之决策树】决策树原理介绍及代码实现sklearn
文章目录
- 一、决策树(Decision Tree)
- 二、原理介绍
-
- 2.1 划分准则的选择
- 2.2 决策树分类实战
- 三、代码实现
-
- 3.1 sklearn-API的介绍
- 3.2 sklearn实现决策树分类代码
- 3.3 sklearn实现决策树回归代码
- 四、总结
一、决策树(Decision Tree)
决策树是一种非参数的有监督的学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,别用树状图的规则来呈现这些规则,已解决分类和回归问题。
二、原理介绍
2.1 划分准则的选择
决策树原理简单,容易理解,适合于各种类型的数据。那么决策树它是一棵树模型,它是如何从数据中找出最佳的节点和分歧呢?树模型本来就是一个容易过拟合的模型,如何让决策树模型停止生长,防止过拟合,这是我们需要考虑的。要知道它是如何工作的,我们先引出两个参数:
(1)信息熵information entropy:它是度量样本集合纯度最常用的一个指标,假定当前样本集合D中第k类样本所占的比例为Pk(k=1,2,3…),那么集合D的信息熵定义为:
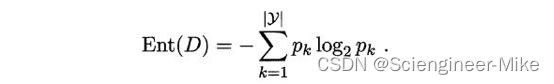
决策树中分类使用的指标是“信息增益”和“增益率”。
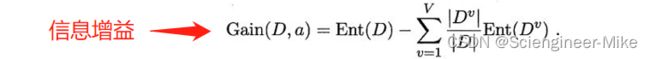

(2)基尼系数gini index:它也是度量样本集合纯度最常用的一个指标,假定当前样本集合D中第k类样本所占的比例为Pk(k=1,2,3…),那么集合D的信息熵定义为:
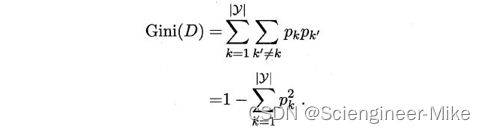
2.2 决策树分类实战
我将参考西瓜书里面的案例,来为大家讲解决策树是如何总结算法规则。
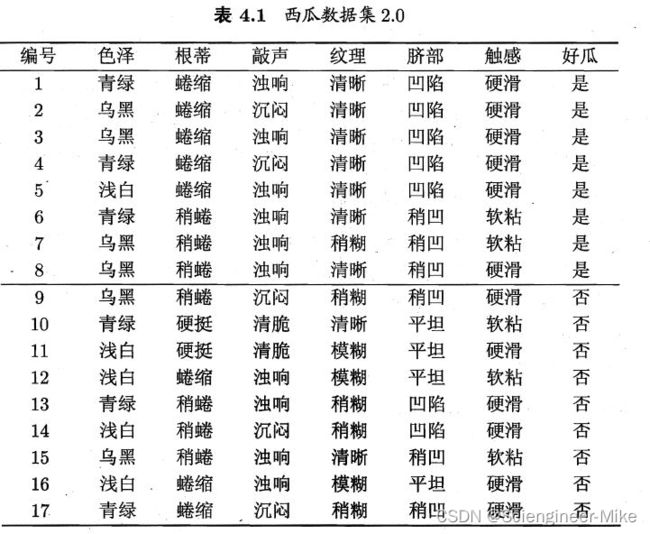
总共17个样本,我们要计算各个属性的信息增益,我们以色泽举例。色泽包含三种情况{青绿,乌黑,浅白}。其好瓜样本占属性样本比例分别是3/6,4/6,1/5。坏瓜样本占属性样本比例分别是3/6,2/6,4/5。那根据信息熵公式可得:
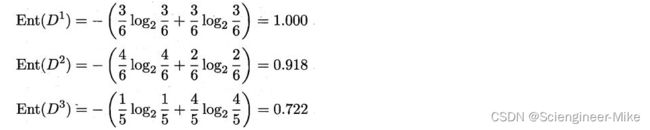
根据信息增益的公式可以得到:
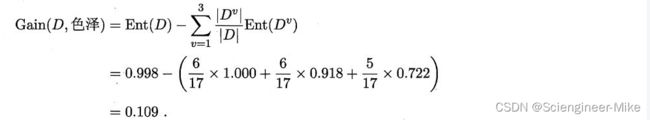
同理,我们计算得到其他属性的信息增益如下:

我们可以看到纹理的信息增益最大,为0.381。于是我们选择纹理作为我们的第一层属性结点。如下:

同理,计算剩余分支的信息增益,可得如下分类效果: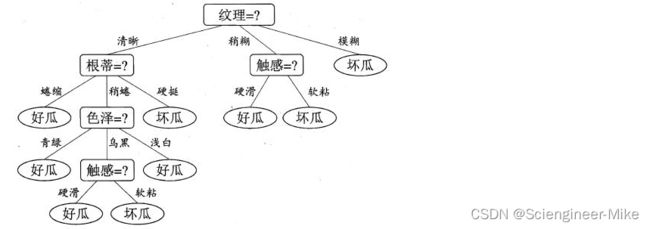
以上,我用一个例子解释了如何使用信息增益进行分类。信息增益率和基尼系数,有兴趣的可以去推导,加深理解。官方将以信息增益为化分准则的决策树算法叫做ID3决策树学习算法,将以增益率为划分准则的决策树算法叫做C4.5决策树学习算法,将以基尼系数为划分准则的决策树算法叫做CART决策树学习算法。
三、代码实现
3.1 sklearn-API的介绍
class sklearn.tree.DecisionTreeClassifier(*, criterion=‘gini’, splitter=‘best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0)
重要参数:
criterion:选择分类准则,包括信息熵:“entropy"和基尼系数”gini“;
random_state:随机模式;
splitter:用来控制决策树中的随机选项的,包括:“best"和"random”;
max_depth:树的最大深度;
min_samples_leaf:限定一个节点在分支后的每个子节点必须至少包含训练样本的数目;
3.2 sklearn实现决策树分类代码
# 导入相应的包
import numpy as np
import matplotlib.pyplot as plt
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
# 导入数据
X,y = load_wine(return_X_y=True)
# 测试集,训练集的划分
Xtrain,Xtest,Ytrain,Ytest=train_test_split(X,y,test_size=0.3,random_state=30)
# 建模训练
score_list = []
for i in np.arange(2,10,1):
clf=tree.DecisionTreeClassifier(criterion="entropy",max_depth=i)
clf=clf.fit(Xtrain,Ytrain)#训练
score=clf.score(Xtest,Ytest)#用测试机返回预测的准确度
score_list.append(score)
#展示结果
plt.plot(np.arange(2,10,1),score_list,color="red")
plt.show()
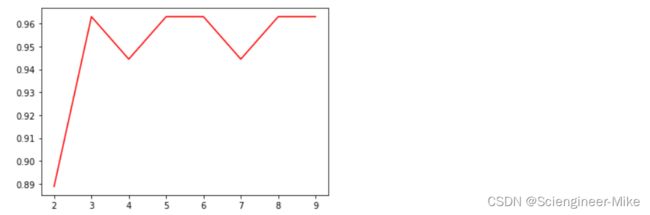
# 特征重要性分析
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
[*zip(feature_name,clf.feature_importances_)]

3.3 sklearn实现决策树回归代码
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
# Create a random dataset
rng = np.random.RandomState(1)
X = np.sort(5 * rng.rand(80, 1), axis=0)
y = np.sin(X).ravel()
y[::5] += 3 * (0.5 - rng.rand(16))
# Fit regression model
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_1.fit(X, y)
regr_2.fit(X, y)
# Predict
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
# Plot the results
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black", c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
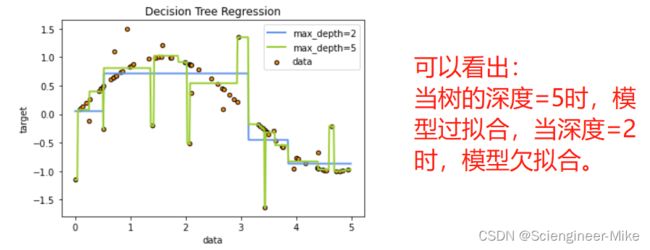
四、总结
决策树模型易于理解和解释,可以将树木画出来,能够同时处理各种数据(文本,数字),既可以做分类也可以做回归,并且需要很少的数据准备。但需要注意的是,决策树是贪婪算法,讲究的是局部最优,从而达到整体最优解,往往容易产生过拟合,需要我们对树进行修剪处理。