课程笔记
前言
两种可解释性:
局部解释:为什么这种图是猫?
全局解释:猫是什么样子的?

为什么需要可解释机器学习?(打开黑盒)

一般的提升效果的方法就是一顿暴调参数,可解释性可以帮助我们更好地提升模型性能。

其实人也是个黑盒(这个观点太6了)。
可解释机器学习的目标,不需要真正知道模型如何工作,只需要给出可信服的解释,让人满意就行。
对此还可以针对不同人的接受能力给出不同层次的解释。

模型的可解释性和模型的能力之间有矛盾。
一些模型,比如线性模型,可解释性很好,但效果不佳。而深度网络,虽然能力一流,但缺乏可解释性。
我们的目标不是直接选择可解释性好的模型,而是让能力强的模型具有更好的解释性。

同时具有强大能力和可解释性的,是决策树。
但决策树结构如果很复杂,那么可解释性也会很差。(森林)


局部解释
一个研究对象可以分成很多个部分,如何判断各部分对于决策的重要性?
可以通过修改或者删除这一部分来看看结果有多大的影响,如果影响很大,则这部分很重要。

举例:

可以用saliency map来可视化,图中的白点就是偏导数的值。

更多资料:

求导的局限性:比如鼻子长到一定程度,就可以确定这是一只大象,但是导数却是0,得出鼻子不重要这样的结论,明显是不对的。

这个也可以被对抗攻击,

宝可梦和数码宝贝的例子:
分类的效果太好了,用saliency map分析后发现,关注点在图的边缘,为什么?

因为格式不一样,背景不同。。。其实程序并没有学会分类宝可梦和数码宝贝。

全局解释
之前讲过,什么样的输入可以得到最好的分类结果,可以看到机器认为的居然是下面这样的一些图。

可以通过加正则项,然后来使图像看起来更像数字。

这样的话就有更多的超参数需要调了。。。。

如果说输入先经过一个生成器,使得不管什么样的向量,都可以经生成器得到一个合理的图片,然后再对图片分类。
通过图片的类别,反推优化输入,这样会更好一些。

得到的结果不错,

用另一个模型去做解释
可以用一个解释性更好的模型去模拟另一个模型的效果。
虽然线性模型不能完全模拟神经网络,但在局部上,模拟效果还是不错的。(LIME方法)
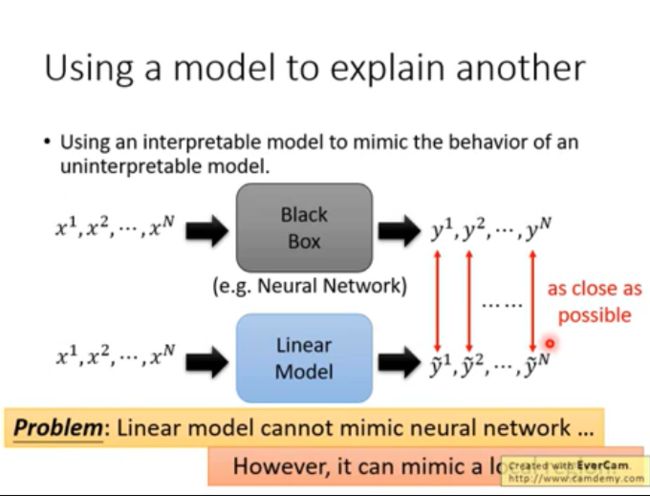
这个方法的局限是,选取的局部粒度的大小会影响模拟的效果。

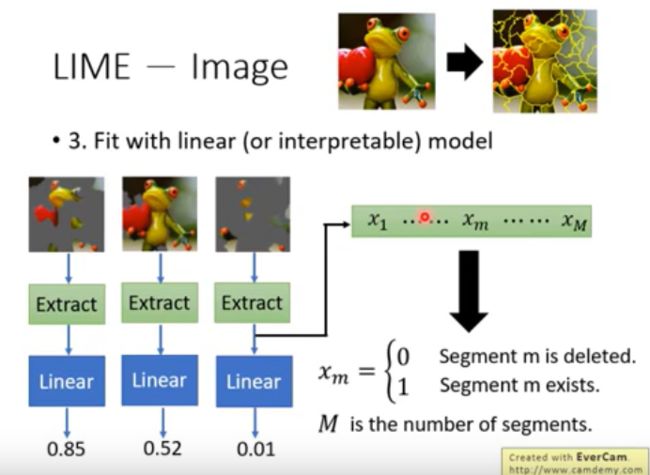
举例:

切分后,可以提取成一个向量,然后可以用线性模型拟合。通过权重的大小,判断各分块的重要性。

如果是决策树模型来模拟的话,我们希望这个树不要太大,那么可以设置一个树的复杂度参数。

不过这个复杂度参数不能微分。(paper中有一种收集很多复杂度数据,然后求解的方法)

课程地址
Explainable ML