详解DETR (End-to-End Object Detection with Transformers)
文章目录
- 详解DETR (End-to-End Object Detection with Transformers)
-
- 简介
- 网络详解
-
- 总述
- 1. BackBone
- 2. Encoder
-
- 图像特征处理
- 位置编码
-
- 需要进行位置编码的原因
- NLP和CV位置编码的不同
- DETR的位置编码
- Encoder Layer
- 3. Decoder
- 4. Prediction Heads
- 5. 匹配策略
- 常见问题
-
- Encoder和Decoder中每个Self-Attention的Query和Key位置编码总结
详解DETR (End-to-End Object Detection with Transformers)
简介
PS:开局先说一下,如果看这篇文章的诸位是对Transformer不了解,或者对DETR刚开始了解,建议先去看Attention Is All You Need,也就是Transformer在NLP中的应用,个人也写了一篇博客:详解Transformer(Attention Is All You Need)。
DETR是Transformer在视觉上的最初应用,由脸书研究院于2020年5月提出,也是Transformer的第一次跨界尝试,并且取得了很好的效果。DETR简化了目标检测的算法流程,同时将一些需要手动设置的技巧,如NMS、anchor成功去掉,实现了端到端的自动训练和学习。
论文地址: https://arxiv.org/abs/2005.12872
论文源码:https://github.com/facebookresearch/detr
核心思想:
将Transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且在 object detection领域取得了和Faster RCNN相当的准确率和运行时间。这是第一个使用End to End方式解决检测问题的网络。
网络详解
总述
DETR按论文所述,整体可以分为 4 4 4个部分——BackBone, Encoder, Decoder, FFN,如下图

1. BackBone
BackBone与我们常用的网络的BackBone没有什么太大的区别,都是为了提取Feature Map,在原文中用的是ResNet。
为了方便后续讲解,假设BackBone输入的图像维度为: B × 3 × H 0 × W 0 B \times 3 \times H_0 \times W_0 B×3×H0×W0的Feature Map的维度为: B × C × H × W B \times C \times H \times W B×C×H×W,一般来说 C = 2048 / 256 C = 2048/256 C=2048/256, H = H 0 32 H = \frac{H_0}{32} H=32H0, W = W 0 32 W = \frac{W_0}{32} W=32W0。
2. Encoder
图像特征处理
Encoder的输入是BackBone的输出,即: B × C × H × W B \times C \times H \times W B×C×H×W的Feature Map。
根据原文和源码的内容,当Feature Map输入进来之后,进行如下几个操作
- 通道数压缩: 首先用 1 × 1 1 \times 1 1×1的
Conv2d处理,将原本的 c h a n n e l channel channel由 C = 2048 C = 2048 C=2048压缩到 d = 256 d = 256 d=256,即得到新的Feature Map,维度为 B × d × H × W B \times d \times H \times W B×d×H×W。 - 空间维度压缩,转换为序列化数据:将空间维度(宽 W W W和高 H H H)压缩到一个维度,即将原有维度为 B × d × H × W B \times d \times H \times W B×d×H×W,
reshape为 H W × B × d HW \times B \times d HW×B×d,其中 ( d = 256 ) (d = 256) (d=256)。
位置编码
需要进行位置编码的原因
这里的位置编码和NLP中的位置编码类似,但是在NLP中是每个单词都是独立的个体,对输入序列中的单词顺序没有表征方法;但是在CV中,其实原本的 B × d × H × W B \times d \times H \times W B×d×H×W的Feature Map是包含每个像素的位置信息的,但是为了后续输入到Encoder中,将维度进行了压缩,这就使得原本的位置信息丢失,因此需要单独进行位置编码来体现出原有的位置信息。
NLP和CV位置编码的不同
NLP中的位置编码,我已经在详解Transformer(Attention Is All You Need)中详细讲述过了,但是由于CV和NLP有所不同,所以这里稍微解释一下。
主要有以下几个不同的地方:
CV中的位置编码需要考虑x,y两个方向,即2D空间位置编码,但NLP只需要考虑一个方向即可;CV中的位置编码向量需要加入到每一个Encoder Layer中,而NLP中则只是在输入Encoder前使用了位置编码;- 在
CV中,位置编码Positional Encoding仅仅作用于Query和Key,即只与Query和Key相加,Value不做任何处理;而NLP中则是与三者都进行相加。
DETR的位置编码
DETR依旧是使用 sin , cos \sin, \cos sin,cos的方式进行位置编码,但是是对 x , y x, y x,y两个方向同时编码,每个方向各编码 128 128 128维向量,这种编码方式更符合图像的特点。
根据原文,DETR的编码规则如下:
P E ( p o s x , 2 i ) = sin ( p o s x 1000 0 2 i 128 ) PE(pos_x, 2i) = \sin(\frac{pos_x}{10000^{\frac{2i}{128}}} ) PE(posx,2i)=sin(100001282iposx)
P E ( p o s x , 2 i + 1 ) = cos ( p o s x 1000 0 2 i 128 ) PE(pos_x, 2i+1) = \cos(\frac{pos_x}{10000^{\frac{2i}{128}}} ) PE(posx,2i+1)=cos(100001282iposx)
P E ( p o s y , 2 i ) = sin ( p o s y 1000 0 2 i 128 ) PE(pos_y, 2i) = \sin(\frac{pos_y}{10000^{\frac{2i}{128}}} ) PE(posy,2i)=sin(100001282iposy)
P E ( p o s y , 2 i + 1 ) = cos ( p o s y 1000 0 2 i 128 ) PE(pos_y, 2i + 1) = \cos(\frac{pos_y}{10000^{\frac{2i}{128}}} ) PE(posy,2i+1)=cos(100001282iposy)
其中,
( p o s x , p o s y ) (pos_x, pos_y) (posx,posy)——特征图中的某一个位置, p o s x ∈ [ 1 , H W ] , p o s y ∈ [ 1 , H W ] pos_x \in [1, HW], pos_y \in [1, HW] posx∈[1,HW],posy∈[1,HW],
i i i——该位置的维度。
我们将 p o s x pos_x posx带入前两个编码公式,可以计算得到 128 128 128维的向量,代表 p o s x pos_x posx的位置编码;将 p o s y pos_y posy带入后两个编码公式,同样可以计算得到 128 128 128维的向量 ,代表 p o s y pos_y posy的位置编码;将 2 2 2个 128 128 128维的向量拼接起来,就可以得到一个 256 256 256维的向量,代表 ( p o s x , p o s y ) (pos_x, pos_y) (posx,posy)的位置编码。
计算所有的位置编码,就得到了 256 × H × W 256 \times H \times W 256×H×W的张量,代表这个batch的位置编码。此时的编码的维度是 B × 256 × H × W B \times 256 \times H \times W B×256×H×W,因为考虑到需要与图像特征相加的原因,在这里也将其reshape为 H W × B × 256 HW \times B \times 256 HW×B×256的向量,这样就可以后续与 H W × B × 256 HW \times B \times 256 HW×B×256维的图像特征向量进行相加。
Encoder Layer
为了方便大家理解,我把输入输出的特征向量在原文中图中进行标注,如下图。
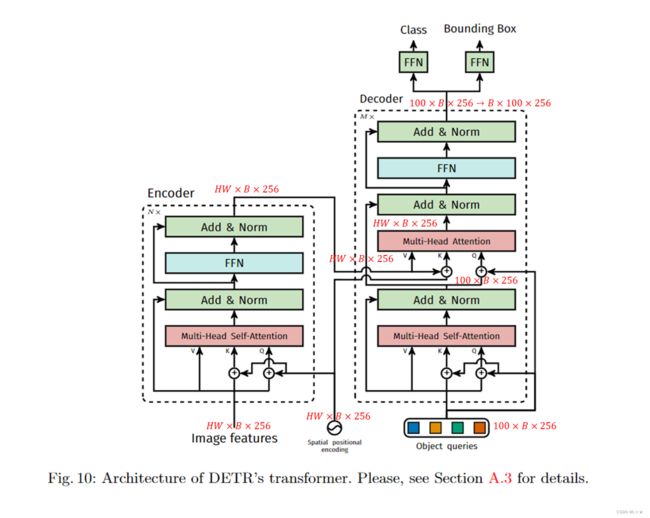
如果大家看了Attention Is All You Need的话,应该会发现这里面的Encoder和原版的Encoder没什么大区别,均是只包含一个Multi-Head Self-Attention和一个Feed Forward Neural Network需要注意的点上面已经说过了,这里再写一下,方便阅读:
DETR的位置编码需要加入到每一个Encoder Layer中,而NLP中则只是在输入Encoder前使用了位置编码;DETR的位置编码仅仅作用于Query和Key,即只与Query和Key相加,Value不做任何处理;而NLP中则是与三者都进行相加。
3. Decoder
Decoder的主要输入有以下几个:
Encoder输出的EmbeddingPosition EncodingObject Queries
其中,
Embedding——Encoder的输出,特征维度为 H W × B × 256 HW \times B \times 256 HW×B×256,
Position Encoding——图像特征图的位置编码,特征维度为 H W × B × 256 HW \times B \times 256 HW×B×256,
Object Queries——一个维度为 100 × B × 256 100 \times B \times 256 100×B×256的张量,数值类型为nn.Embedding,说明这个张量是可以学习的。该张量内部通过学习建模了100个Object之间的关系。
特别注意的是:Decoder的输入一开始也初始化成维度为 100 × B × 256 100 \times B \times 256 100×B×256的元素全为 0 0 0的张量,和Object Queries加在一起之后,充当第一个 Multi_Head Self-Attention的Query和Key。第一个Multi-Head Self-Attention的Value为Decoder的输入,也就是维度为 100 × B × 256 100 \times B \times 256 100×B×256的元素全为 0 0 0的张量。
到了Decoder的第 2 2 2个Multi-Head SelfAttention,它的Value来自于Encoder的输出张量,维度为 H W × B × 256 HW \times B \times 256 HW×B×256;Key则是Encoder的输出张量和图像特征位置编码之和,维度也为 H W × B × 256 HW \times B \times 256 HW×B×256;Query值一部分来自第一个Add & Norm,维度为 100 × B × 256 100 \times B \times 256 100×B×256的张量,另一部分来自Object Queries,充当可学习的位置编码。所以第二个Multi-Head Self-AttentionKey和Value的维度为 H W × B × 256 HW \times B \times 256 HW×B×256,而Query的维度为 100 × B × 256 100 \times B \times 256 100×B×256。
这里,我们会发现,Object Queries其实是一个类似于位置编码的作用,只不过是一个可学习的位置编码。
每个Decoder的输出维度为 1 × B × 100 × 256 1 \times B \times 100 \times 256 1×B×100×256,送入后续的Feed Forward Neural Network,最终得到 B × 100 × 256 B \times 100 \times 256 B×100×256的张量。
4. Prediction Heads
将Decoder输出的维度为 B × 100 × 256 B \times 100 \times 256 B×100×256的张量,送入 2 2 2个前馈网络FFN得到Class和Bounding Box。
这里会得到 N = 100 N = 100 N=100个预测目标,包含Class和Bounding Box,这里的 100 100 100是远大于图像中目标的个数的。如果不够 100 100 100则用背景填充,计算loss的时候仅仅计算有目标位置的loss,背景集合忽略。
所以,DETR输出的张量的维度为: B × 100 × ( c l a s s + 1 ) B \times 100 \times (class + 1) B×100×(class+1)和 B × 100 × 4 B \times 100 \times 4 B×100×4。
对应COCO数据集而言, c l a s s + 1 = 92 class + 1 = 92 class+1=92; 4 4 4指的是每个预测目标归一化后的坐标 ( c x , c y , w , h ) (c_x, c_y, w, h) (cx,cy,w,h)。
5. 匹配策略
提到上面预测的内容,可能会存在一些疑惑,在loss计算或者评估的时候,预测框和真值框怎么一一对应的呢?
这里就涉及到了匹配策略,一般大家用的都是经典的双边匹配算法,也就是常说的匈牙利算法,该算法广泛应用于最优分配问题。有兴趣的,大家可以自己查一下。
该算法主要的作用就是:找到每个真值对应的预测值是哪个。
常见问题
Encoder和Decoder中每个Self-Attention的Query和Key位置编码总结
| Encoder每个Layer的位置编码来源 | Query | Key |
|---|---|---|
第 1 1 1个Multi-Head Self-Attention |
Positional Encoding |
Positional Encoding |
| Decoder每个Layer的位置编码来源 | Query | Key |
第 1 1 1个Multi-Head Self-Attention |
Object Queries |
Object Queries |
第 2 2 2个Multi-Head Self-Attention |
Object Queries |
Positional Encoding |