论文笔记:Enhanced LSTM for Natural Language Inference
Enhanced LSTM for Natural Language Inference
https://arxiv.org/pdf/1609.06038v3.pdf
Related Work
- Enhancing sequential inference models based on chain networks
- Further, considering recursive architectures to encode syntactic parsing information
Hybrid Neural Inference Models
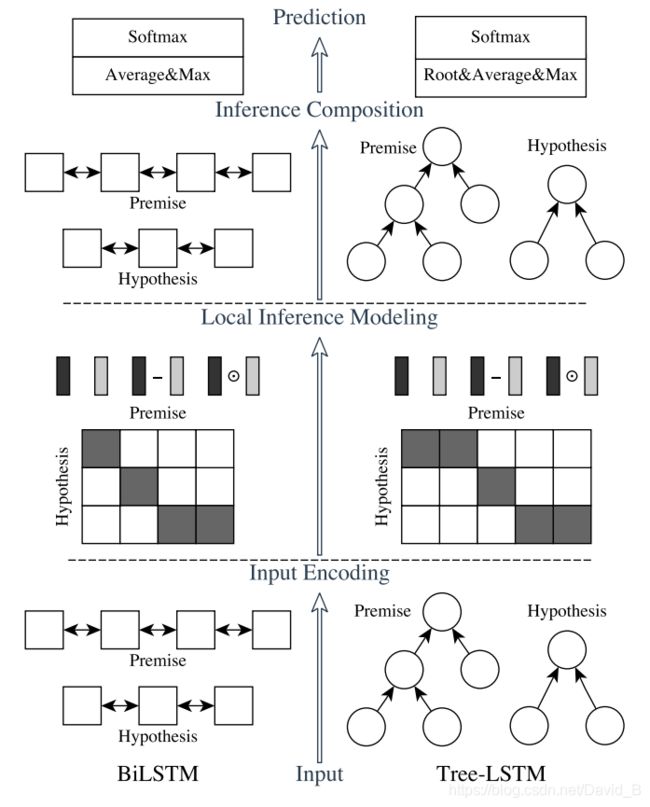
Major components
- input encoding、local inference modeling、inference composition
- ESIM(sequential NLI model)、Tree LSTM(incorporate syntactic parsing information)
Notation
- Two sentences:
- a = ( a 1 , . . . , a l a ) a = (a_1, ..., a_{l_a}) a=(a1,...,ala)
- b = ( b 1 , . . . , b l b ) b = (b_1, ..., b_{l_b}) b=(b1,...,blb)
- Enbedding of l l l-dimensional vector: a i a_i ai、 b j ∈ R l b_j\in \mathbb{R}^l bj∈Rl
- a ˉ i \bar {a}_i aˉi: generated by the B i L S T M BiLSTM BiLSTM at time i i i over the input sequence a a a
Goal
- Predict a label y y y that indicates the logic relationship between a a a and b b b
Input Encoding
-
Use B i L S T M BiLSTM BiLSTM to encode the input premise and hypothesis
-
Hidden states by two LSTMs at each time step are concatenated to represent that time step and its context
-
Encode syntactic parse trees of a premise and hypothesis through tree-LSTM
-
A tree node is deployed with a tree-LSTM memory block depicted
- At each node, an input vector x t x_t xt and hidden vectors of it( h t − 1 L h^L_{t-1} ht−1L and h t − 1 R h^R_{t-1} ht−1R)are taken in as the input to calculate the current node’s hidden vector h t h_t ht

- At each node, an input vector x t x_t xt and hidden vectors of it( h t − 1 L h^L_{t-1} ht−1L and h t − 1 R h^R_{t-1} ht−1R)are taken in as the input to calculate the current node’s hidden vector h t h_t ht
-
Detailed computation:
- h t = T r L S T M ( x t , h t − 1 L , h t − 1 R ) h_t=TrLSTM(x_t, h^L_{t-1}, h^R_{t-1}) ht=TrLSTM(xt,ht−1L,ht−1R)
- h t = o t ⊙ t a n h ( c t ) h_t=o_t\odot tanh(c_t) ht=ot⊙tanh(ct)
- o t = σ ( W o x t + U o L h t − 1 L + U o R h t − 1 R ) o_t=\sigma(W_ox_t+U^L_oh^L_{t-1}+U^R_oh^R_{t-1}) ot=σ(Woxt+UoLht−1L+UoRht−1R)
- c t = f t T ⊙ c t − 1 L + f t R ⊙ c t − 1 R + i t ⊙ u t c_t=f_t^T \odot c^L_{t-1}+f^R_t\odot c^R_{t-1}+i_t\odot u_t ct=ftT⊙ct−1L+ftR⊙ct−1R+it⊙ut
- f t L = σ ( W f x t + U f L L h t − 1 L + U f L R h t − 1 R ) f^L_t=\sigma(W_fx_t+U^{LL}_fh^L_{t-1}+U^{LR}_fh^R_{t-1}) ftL=σ(Wfxt+UfLLht−1L+UfLRht−1R)
- f t R = σ ( W f x t + U f R L h t − 1 L + U f R R h t − 1 R ) f^R_t=\sigma(W_fx_t+U^{RL}_fh^L_{t-1}+U^{RR}_fh^R_{t-1}) ftR=σ(Wfxt+UfRLht−1L+UfRRht−1R)
- i t = σ ( W i x t + U i L h t − 1 L + U i R h t − 1 R ) i_t=\sigma(W_ix_t+U^L_i h^L_{t-1}+U^R_ih^R_{t-1}) it=σ(Wixt+UiLht−1L+UiRht−1R)
- u t = t a n h ( W c x t + U c L h t − 1 L + U c R h t − 1 R ) u_t=tanh(W_cx_t+U^L_ch^L_{t-1}+U^R_ch^R_{t-1}) ut=tanh(Wcxt+UcLht−1L+UcRht−1R)
-
All W ∈ R d × l , U ∈ d × d W\in \mathbb{R}^{d\times l}, U\in\mathbb{d\times d} W∈Rd×l,U∈d×d are weight matrices to be learned
Local Inference Modeling
Locality of inference
- Employ some forms of hard or soft alignment to associate the relevant subcomponents between a premise and a hypothesis
- Argue for leveraging attention over the bidirectional sequential encoding of the input
- soft alignment layer computes the attention weights as the similarity of a hidden state tuple < a ˉ i , b ˉ j > <\bar a_i,\bar b_j> <aˉi,bˉj> between a premise and a hypothesis with e i j = a ˉ i T b ˉ j e_{ij}= \bar {a}^T_i \bar b_j eij=aˉiTbˉj
- use bidirectional LSTM and tree-LSTM to encode the premise and hypothesis
- In sequential inference model, use BiLSTM
Local inference collected over sequences
- Local inference is determined by the attentiion weight e i j e_{ij} eij, which is used to obtain the local relevance between a premise and hypothesis
- The content in { b ˉ j } j = 1 l b {\{\bar b_j\}}^{l_b}_{j=1} {bˉj}j=1lb that is relevant to a ˉ i \bar a_i aˉi will be selected and represented as a ~ i \tilde a_i a~i
a ~ i = ∑ j = 1 l b e x p ( e i j ) ∑ k = 1 l b e x p ( e i k ) b ˉ j , ∀ i ∈ [ 1 , . . . , l a ] \tilde a_i =\sum\limits_{j=1}^{l_b}\frac{exp(e_{ij})}{\sum^{l_b}_{k=1}exp(e_{ik})}\bar b_j, \forall i \in[1,...,l_a] a~i=j=1∑lb∑k=1lbexp(eik)exp(eij)bˉj,∀i∈[1,...,la]
b ~ j = ∑ i = 1 l a e x p ( e i j ) ∑ k = 1 l a e x p ( e k j ) a ˉ i , ∀ j ∈ [ 1 , . . . , l b ] \tilde b_j =\sum\limits_{i=1}^{l_a}\frac{exp(e_{ij})}{\sum^{l_a}_{k=1}exp(e_{kj})}\bar a_i, \forall j \in[1,...,l_b] b~j=i=1∑la∑k=1laexp(ekj)exp(eij)aˉi,∀j∈[1,...,lb]
Local inference collected over parse trees
- compute the difference and the element-wise product for the tuple < a ˉ , a ~ > <\bar a, \tilde a> <aˉ,a~>as well as for
< b ˉ , b ~ > <\bar b, \tilde b> <bˉ,b~> - The difference and element-wise product are then concatenated with the original vectors
m a = [ a ˉ ; a ~ ; a ˉ − a ~ ; a ˉ ⊙ a ~ ; ] m_a=[\bar a;\tilde a;\bar a-\tilde a;\bar a \odot \tilde a;] ma=[aˉ;a~;aˉ−a~;aˉ⊙a~;]
m b = [ b ˉ ; b ~ ; b ˉ − b ~ ; b ˉ ⊙ b ~ ; ] m_b=[\bar b;\tilde b;\bar b-\tilde b;\bar b \odot \tilde b;] mb=[bˉ;b~;bˉ−b~;bˉ⊙b~;]
Inference Composition
- Explore a composition layer to compose the enhanced local inference information m a m_a ma and m b m_b mb
The composition layer
- In sequential inference model, use BiLSTM to compose local inference information sequentially
- Formulas for BiLSTM are used to capture local inference information m a m_a ma and m b m_b mb and their context here for inference composition
- In the tree composition, a tree node updates to compose local inference
v a , t = T r L S T M ( F ( m a , t ) , h t − 1 L , h t − 1 R ) v_{a,t}=TrLSTM(F(m_{a,t}), h^L_{t-1}, h^R_{t-1}) va,t=TrLSTM(F(ma,t),ht−1L,ht−1R)
v b , t = T r L S T M ( F ( m b , t ) , h t − 1 L , h t − 1 R ) v_{b,t}=TrLSTM(F(m_{b,t}), h^L_{t-1}, h^R_{t-1}) vb,t=TrLSTM(F(mb,t),ht−1L,ht−1R)
- Use a 1-layer feedforward neural network with the ReLU activation, which is also applied to BiLSTM in sequential inference composition
Pooling
- Convert the resulting vectors obtained above to a fixed-length vector with pooling and feeds it to the final classifier to determine the overall inference relationship
- Compute both average and max pooling, and concatenate all these vectors to form the final fixed length vector v v v
v a , a v e = ∑ i = 1 l a v a , i l a v_{a,ave}=\sum\limits_{i=1}^{l_a}\frac{v_{a,i}}{l_a} va,ave=i=1∑lalava,i, v a , m a x = max i = 1 l a v a , i v_{a,max}=\max\limits_{i=1}^{l_a}v_{a,i} va,max=i=1maxlava,i
v b , a v e = ∑ j = 1 l b v b , j l b v_{b,ave}=\sum\limits_{j=1}^{l_b}\frac{v_{b,j}}{l_b} vb,ave=j=1∑lblbvb,j, v b , m a x = max j = 1 l b v b , j v_{b,max}=\max\limits_{j=1}^{l_b}v_{b,j} vb,max=j=1maxlbvb,j
v = [ v a , a v e ; v a , m a x ; v b , a v e ; v b , m a x ] v =[v_{a,ave};v_{a,max};v_{b,ave};v_{b,max}] v=[va,ave;va,max;vb,ave;vb,max]
- Put v v v into a final multilayer perceptron(MLP) classifier
- Use multi-class cross-entropy loss