【语义相似度】ESIM:语义相似度领域小模型的尊严
点击上方,选择星标,每天给你送干货!
来自:CS的陋室
先把论文放出来:Enhanced LSTM for Natural Language Inference,说实话这篇论文不算新了,但是在语义相似度方至今仍流传着他的传说,因此我还是把这篇论文拿着读了起来。近期也是看了很多文章,但是终究不如读论文来的过瘾,大部分博客对这篇论文的模型核心做了很多介绍,但各个操作的出发点和一些独到的见解却写的不多,这次我会在介绍ESIM的过程中讨论一下。
当然,还是建议大家好好品读原论文,更有味道。
另外给点代码,看论文不清楚的看看论文也挺好:
https://blog.csdn.net/wcy23580/article/details/84990923。
https://github.com/weekcup/ESIM。
有关语义匹配和推理
一般地,向量召回主要用的表征模型,但是表征模型没有用到交互特征,因此匹配的准确率上肯定比不过交互模型,所以一般工程上用表征模型召回,然后用交互模型来做精排,这样能保证整个搜索系统的效果更加稳定可靠(看到没,准召分离的思路又来了),而交互模型这块,比较可靠的基线,应该就要数ESIM了。
ESIM里,我比较欣赏的是这几点:
LSTM抽取上下文信息。Tree-LSTM的尝试也为信息抽取带来启发。
把Decomposable attention作为交互特征的思路有机组合起来了。
多种交互形式的特征concat起来。
当然具体阅读后,我还提炼了一些新的idea,在文末。有了这些思路,先让我们来看看具体的模型,其实论文的行文里讨论了很多思路,我们先来看整体论文思路,然后再来提炼里面的独到之处。
模型整体
论文的模型其实没有想象中的困难,在很早就把整篇论文给到了:
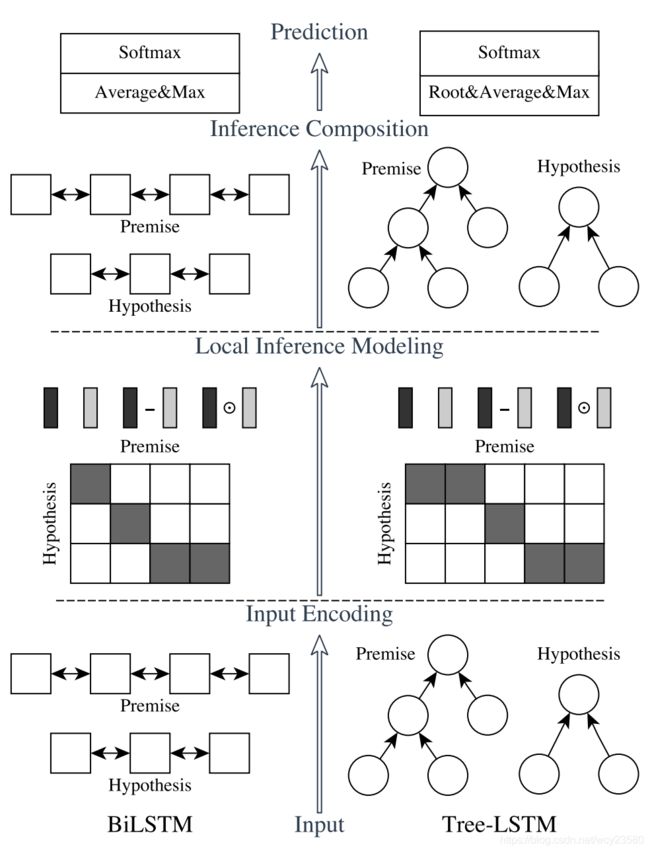
输入层是embedding+LSTM的组合。
Local Inference Modeling层,用的Decomposable Attention来体现两者的交互型。
Inference composition层则把上面一层的结果进行多种组合计算,得到多种特征,说白了就是比较。
输出层就不多说了,大家都懂的。
输入层
一般的输入层只会是简单的word2vector,但这里其实加了一个LSTM,还是双向的,就是用来获取各路信息。来看看代码,这个还是比较清晰的:
i1 = Input(shape=(SentenceLen,), dtype='float32')
i2 = Input(shape=(SentenceLen,), dtype='float32')
x1 = Embedding([CONFIG])(i1)
x2 = Embedding([CONFIG])(i2)
x1 = Bidirectional(LSTM(300, return_sequences=True))(x1)
x2 = Bidirectional(LSTM(300, return_sequences=True))(x2)
Local Inference Modeling
中文翻译应该是局部推理层,我的理解这一层是用于抽取局部信息的,作者用的方法应该来源于这篇论文:A Decomposable Attention Model for Natural Language Inference,这里其实是一个计算交互特征的过程,即一一分析两个句子之间每个位置的相似度,最简单的方式就是点乘,而这篇论文就是使用的这个最简单的方式:
然后再把权重分散到各个位置,其实形态就很像softmax了:
这个其实就是做了一个交叉,计算整个句子的权重,然后用类似softmax的形式整上,非常讨巧,相信ESIM的成功很大程度上就和这个有关。
而这并没结束,作者进行了进一步的强化,对比Decomposable Attention前后的变化,进行了组合。
Inference Composition
推理层应该是进入最终预测之前的最后一层了。这一层的操作同样没那么简单,大部分人可能flatten、maxpool、avgpool之类的就直接全连接了,但是这里并不是,而是做了一系列的再提取和再处理,最终才完成预测向量的:
作者是真的把信息抽取和特征的组合做到了极致,对上面构造的两个组合特征 再进行了一次特征提取,用的依旧是熟悉的Bilstm,值得注意的是他操作的维度,来看一个ESIM的开源代码吧:
class InferenceCompositionLayer(object):
"""
Layer to compose the local inference information.
"""
def __init__(self, hidden_units, max_length=100, dropout=0.5,
activation='tanh', sequences=True):
self.hidden_units = hidden_units
self.max_length = max_length
self.dropout = dropout
self.activation = activation
self.sequences = sequences
def __call__(self, input):
composition = Bidirectional(LSTM(self.hidden_units,
activation=self.activation,
return_sequences=self.sequences,
recurrent_dropout=self.dropout,
dropout=self.dropout))(input)
reduction = TimeDistributed(Dense(self.hidden_units,
kernel_initializer='he_normal',
activation='relu'))(composition)
return Dropout(self.dropout)(reduction)
这里用到另一个我没见过的keras层,即TimeDistributed,有兴趣可以了解下。
此后,非常精髓的使用avg-pool和max-pool的组合,有关池化,max和avg一直打得火热,没有人能给出非常稳定的结论,因此作者就用了两者的组合:
启示
整篇文章其实没有构造出非常高端的结构,只是一些非常朴素的操作,但是综合起来成了现在也非常推荐用的基线,是有很多有借鉴意义的东西的,我这里一一列举,大家可以直接在里面选择需要的来用。
BiLSTM似乎还挺好用的。当然私以为CNN其实也可以尝试的。
花式concat,多种信息抽取方式进行组合,小孩子才做选择,大人全都要。
attention的使用,其实有出处A Decomposable Attention Model for Natural Language Inference,思想其实是两者一一对比得到交互矩阵,利用该交互矩阵构造类似softmax的权重,为各自的关键信息进行加权,重点提取。
信息的对比来自于可以来自减和乘,减直接计算两者的差距,类似欧氏距离,乘的使用则来源于余弦距离,既然要对比特征,那就把这两个用到极致。
avg和max哪个好,别争了,都用,哪个比较重要交给后面的全连接层来决定吧。
我的这篇文章里面没有讲tree-lstm,主要是因为我们平时比较难用到,原因是这个树不好构建,需要依赖依存句法,但是的确是一个挺有意思的思想,只有真的去读论文的人才能知道。
参考资料
论文原文:Enhanced LSTM for Natural Language Inference
论文解读:https://blog.csdn.net/wcy23580/article/details/84990923
keras版本代码:https://github.com/weekcup/ESIM/blob/master/src/model.py
依旧推荐大家直接去读论文,文章对他为什么做这些操作有很明确的思想,其实在我看来这些思想比操作本身还要重要,毕竟思想是需要启发的,在这些思想的指导下,我在思考解决方案的时候就能有参考,方案可以借鉴,但是这个思想的实现并不局限在一个方法上。
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心![]() 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!