2021年最值得期待的数据智能赛事之一,有何解题妙招?
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

在 GIS(Geographic Information System)领域,由国际计算机学会 ACM 空间信息专业委员会主办的 ACM SIGSPATIAL,被认为是 GIS 科学与计算机科学结合最广泛的国际顶级会议。
今年,滴滴联合 ACM SIGSPATIAL,共同举办 2021 ACM SIGSPATIAL GISCUP 比赛,这也是 ACM SIGSPATIAL 会议是第一次离开美国在北京举办。
近日,以该赛事为主题,滴滴、biendata 、ACM SIGSPATIAL 中国分会、paper weekly 和 AI time 合作发起了一次赛题解析直播。
2021 ACM SIGSPATIAL GISCUP 的赛题是 “预估到达时间”(Estimated time of arrival,下文简称 “ETA”)。赛事详情可参见:
SIGSPATIAL 2021 官网:
https://sigspatial2021.sigspatial.org/sigspatial-cup/
Biendata 官网(点击文末“阅读原文”即可访问):https://www.biendata.xyz/competition/didi-eta/
直播主讲人为滴滴公司地图与公交事业部的资深算法工程师刘欣悦。她于 2019 年加入滴滴,担任地图与公交事业部 ETA 和路况策略团队资深算法工程师,主要负责滴滴平台 ETA 和预估算法优化的相关工作,在大规模深度学习模型方面经验丰富。
直播中,她详细介绍了比赛数据和赛题,并分享了滴滴在提升 ETA 能力上的实践经验,希望鼓励参与者基于滴滴发布的新数据集,进一步提升时间预估的准确性。
目前,比赛使用的行程时长数据集已通过滴滴盖亚数据开放计划(https://outreach.didichuxing.com/research/opendata/)对外发布,囊括了 2020 年 8 月在深圳经过脱敏处理的出行时间数据。
一、赛题:预估到达时间难在哪里?
作为大赛赛题,ETA 本身是一个较实用且容易理解的场景。
日常生活中,我们经常会说 “上下班路程大概要半个小时”,或者 “大约 5 分钟以后才能到目的地” 等,这些都是比较笼统的 ETA 的说法。
在滴滴或者其他地图工具的使用场景中,往往需要一个更加精细化的 ETA。
无论是滴滴的各个产品线上,还是其他地图工具,或多或少都会涉及这个议题。
如下图中导航界面的截图,可以看到三条路线,每条路线都会有一个预估的到达时间。这样可以方便用户在出行的时候,结合该时间来选择更适合自己的路线。
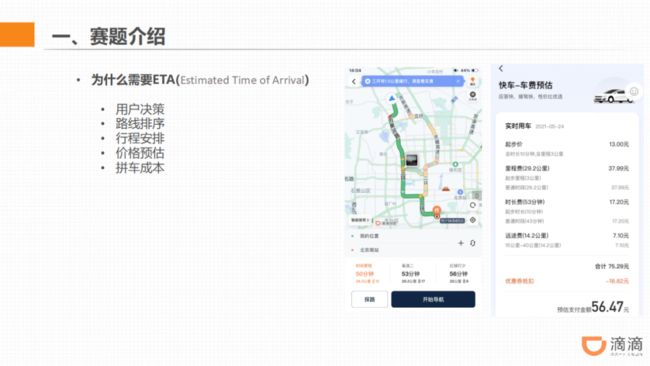
另外,预估到达时间也是同一个起点、终点之间多条路线间排序的重要特征,它可能会影响优先展示给用户的路线是哪一条。用户可以根据预估到达时间来安排自己的日程。
在滴滴网约车场景中,预估费用是根据路线距离和预估行程时间来计算得出的,所以,ETA 会直接影响到乘客对出行方式的选择。
在拼车的场景中,如何判断将哪些乘客拼成一个订单,ETA 也是一个非常重要的指标,它直接决定着订单的拼成率。
所以,可以看到,在滴滴的各产品线,ETA 必要性体现在用户决策、路线排序、行程安排、价格预估、拼车成本 5 个方面,它的准确性会直接影响乘客的体验和司机的效率。
不过,要想预估准确,并不是一件很容易的事情。

即便是同一条路线,在不同的时刻出发,可能会面临不同的路况环境,花费的时间也会差很多。
比如早晚高峰、工作日和周末的拥堵情况和拥堵时间段都不太一样,由此带来的路况变化和波动,会直接导致路线花费时间差距变大。
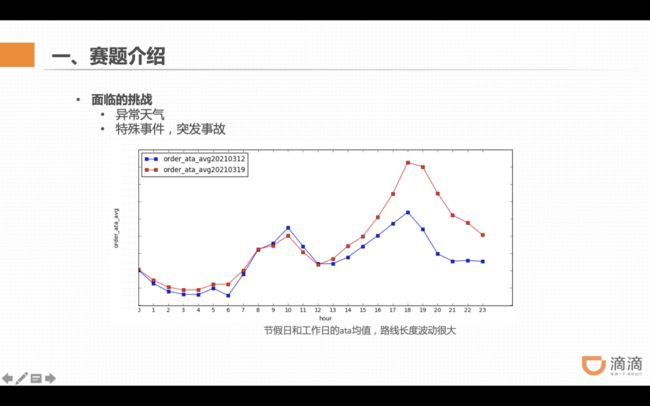
如果遇到了极端天气,或者是一些突发的交通事故,比如说演唱会或者重大赛事等等,也会带来路况的变化。
例如,今年 3 月份某个周五下午,北京突降暴雨,那一天,几乎所有的订单都比平时要慢很多。事后,我们统计了那一天的订单分布,可以看到的是,从下午开始,订单时间明显比一个普通周五的平均订单时间要长。所以,如果当天我们用了一个正常模型来预测,那么情况会变得很困难。
另外,还有一些可以预想到的日常会发生的情况,比如说红绿灯的影响,有的人可能会运气比较好,一路上没有碰到什么红灯,有的人在同一条路就反复碰到,同样会影响预测结果。
简而言之,异常天气、特殊事件 / 突发事故,是提高 ETA 准确率所要面临的主要挑战。

本次比赛的 ETA 任务,使用的数据由滴滴盖亚数据开放计划提供,即 “行程到达时间预估数据集”。数据为 2020 年 8 月份深圳市网约车的真实订单数据,这一整个月的订单数据含有出发时间日期、行程路线、路况信息、网络拓扑结构等信息。
且该数据集已经进行了脱敏处理,所有订单数据都不包括任何司机和乘客的个人信息。比赛任务即根据这些特征来预测每个订单的到达时间。
接下来,将介绍滴滴盖亚数据开放计划以及比赛流程。

通过滴滴盖亚数据开放计划,滴滴将脱敏数据集开放给学术界,希望携手学界一起去探索科学的边界,共同产出一定的学术成果。
截止目前,滴滴已经陆续开放了十五大特色数据集,可在滴滴盖亚数据开放计划的官网下载这些数据集用于科学研究,目前已有 1 万余人次进行了数据集的申请。这一系列数据集也已支持了大量的 AI 类竞赛,包括 2020 KDD CUP、CCF BDCI 路况预测竞赛,以及这一次的 SIGSPATIAL GISCUP ETA 竞赛。统计显示,已有 90 篇以上学术文章采用了这些数据。且这些数据也为很多高校提供了支持,至少有 20 多个教师团队进行了相关课程建设。
滴滴希望,这些数据集能够真正帮到学术界的老师和同学产出对社会有帮助的科研成果。

具体的比赛流程方面,本次比赛在 4 月 23 日正式对外开放注册,目前仍可以进行注册。
其中,4 月 30 日至 8 月 9 日是参赛选手的成果提交阶段,选手需要提交测试集的预测结果。此次比赛采用 ab 榜的机制,8 月 2 日前,选手可使用 a 榜每日测试自己模型的当前水平。组队截止时间为 8 月 2 日,当日也将公布 b 榜的竞赛数据。
8 月 31 日正式公布比赛结果,比赛结果以 b 榜的成绩为准,获得前 5 名的队伍需要提交一份训练的代码及注释、可复现最高分的预测模型,最后按照 ACM 的格式要求,产出一篇不多于 4 页的英文论文,论文提交的截止时间是 9 月 15 日。
11 月 2-4 日,前 5 名的参赛队伍会受邀参加 SIGSPATIAL2021 进行现场展示,同时也欢迎其他的参赛选手参加这次会议。

此次比赛总奖金池达到 25,000 美元。其中,冠军队伍一名,将会获得 1 万美元的奖励。亚军两名,将分别获得 5000 美元,季军队伍两名,将分别获得 2500 美元。奖金力度非常可观。
二、大赛数据字段详解
此次大赛提供了三份数据,本节将对第一份数据 —— 行程路线和路况数据进行详解。
该数据分为三个部分,每个部分之间用两个分号分隔。
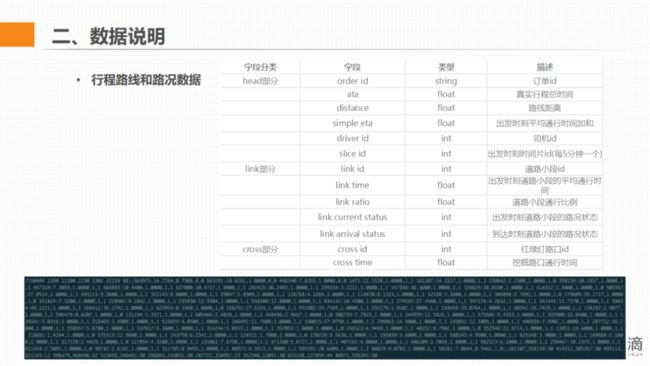
第一个部分是 head 部分,字段之间由空格隔开。
link 部分和 cross 部分都是序列数据,每个序列中会有很多小段数据,每一个小段数据都有自己的特征。小段之间用空格隔开,特征之间是用逗号隔开,详细的格式网页上都会有说明。

在此,进一步详细说明每个字段的含义:
l ATA,是指实际到达时间,也是这次比赛的一个 label 和训练的目标。ATA 的获得方式是乘客到达时间减去乘客上车时间,单位是秒。我们以 ATA 为训练目标进行训练。
l Drive ID,是指行程里驾车司机的 ID,已经过脱敏处理,不涉及司机个人信息。
l Distance,是路线的路面距离,单位是米。
l Slice ID,代表的是乘客上车的时间,它由时间转换而来,每 5 分钟有一个对应的 ID, 24 小时循环一次。

l Link ID,指路线中的每一个子路段的 ID。两个圆点之间就是一个 link。
l Link time,是指平均通过一个 link 的时间。滴滴在计算过程中做了一些轨迹的数据清理,总的来说,link time 是一个比较准确的平均统计值,但是因为它是用历史轨迹统计出来的,所以没有任何预测含义。我们可以直接用 link time 累加作为 ETA,但是它可能在预估上不含有任何未来信息,所以不会特别准。Link time 考虑了 link ratio。
l Link ratio,指的是 link 在整条路线中被覆盖到的比例,除了头尾 link 以外都是 1,头尾可能 < 1。
l Link current status,代表的是该 link 的路况状态,路况状态正常情况下有 4 个等级,1 等于畅通,2 是缓行,3 是拥堵,4 是极度拥堵。需要注意,这是乘客上车时候的路况。
l Link arrival status,是司机到达时刻该 link 的路况状态。它相当于一个泄露信息,因为不可能在行程开始的时候就获知这一信息,所以测试集中不包含这一字段,只有训练集有。
l Link 长度已经过脱敏处理。

l Cross ID,代表的是红绿灯路口的概念,数据是由一个 link ID 加一个下划线,再加一个 link ID 组成的。两个 link ID 分别代表的是进和出这一路口的 link。
l Cross time,是路口的一个平均等待红绿灯的时间,属于挖掘值,它也是利用历史轨迹统计出来的。
l Simple ETA , 是全程所有 link time 和 cross time 之和。

第二份数据是路网的拓扑结构数据。拓扑数据总共有两列,第一列代表一个 link id;第二列是由逗号分隔的很多个 link ID,它代表的是 link ID 的每一个下游,它们的顺序是没有前后关系的。
另外,还有一份天气数据 —— 深圳 2020 年 8 月份整个月的天气情况,包括了当天的晴雨情况以及最高气温和最低气温。
三、比赛评测标准:MAPE 权威计分
本次比赛的评测标准采用 MAPE(Mean absolute percentage error)进行计分。

主办方将会使用模型产出的订单 ETA 减去它作为 label 的 ata 获得的绝对值,除以 ata 得到一个比值,最终所有测试集取均值作为分数。
如果出现两个队伍分数相同,则以提交次数更少的队伍为获胜方。如果两个队伍提交的分数和次数都相同,则按照提交时间早的队伍为获胜方。
之所以用 MAPE 作为评测标准,是因为,目前它在业界和学术界都是一个获得通用认可的指标。
同时,在我们日常的感受中,它也是更接近用户感知的。
一条比较长的路线,人们可能会认为稍微高估 5 分钟或者低估 5 分钟,差别不是特别的明显。但是如果全程就只有 10 分钟,系统还高估 5 分钟,你会感觉预测特别不准,而 MAPE 在这一点上也是比较结合这种感受的。
四、滴滴解决 ETA 任务的总结
正如上文所提,滴滴在 ETA 任务的处理上有着长期的积累,本节将分享滴滴团队在 ETA 上尝试过的思路和方法,以帮助参赛者碰撞出更好的解决方案。

首先,ETA 是一个回归问题。理论上,要预测一个 ETA 的值,我们现在可以想到的几乎所有的回归问题解法,在这个场景上都是可以使用的。
同时,鉴于这些数据有很明显的序列特征,进一步地,可以很明确地想到一些序列的建模方式,比如说 LSTM,把它套用到这些有序列特征的模型上是比较方便的。
另一方面,ETA 问题可能和 NLP 中存在很明确上下文关系的情况又不是那么相似,即没有那么强烈的上下文依赖性,所以,有的时候可以用例如 CNN 这样的深度网络也是可行的。

第二个思路是考虑邻域的影响。路网数据本身是有邻域的关系,除了受到路线的上下游影响之外,也可能会受到自己在地图网中的上下游的影响,所以,邻域之间的影响是存在的。
加之本次比赛也开放了拓扑关系的路网数据,利用拓扑关系,可以结合图神经网络的建模方式,让模型学到更多的上下游信息,丰富模型的特征表。
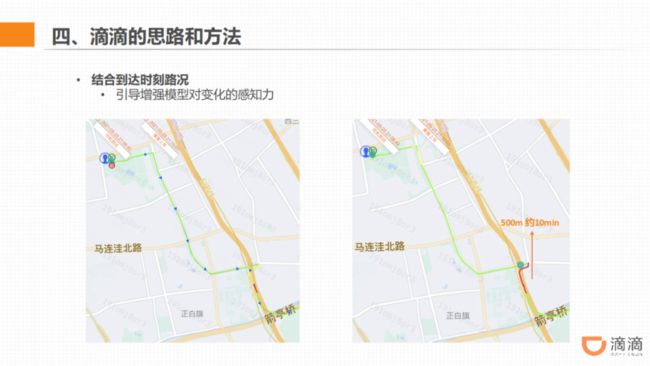
第三个思路在于,上文有提到,ETA 的难点之一是路况变化会导致预估难度增加。
如上图所示,出发时刻的路况是左图,路线上有一小段拥堵,大部分是缓行。但当司机已经开到拥堵路段附近时,又变成了全程拥堵的情况,最终开过去 500 米用了整整 10 分钟。
这就是路况变化带来的预估困难问题。而这次的数据有泄露的特征,即到达时刻的路况。之所以提供了泄露的特征,是希望引导参赛者考虑让模型能够在训练的过程中学到路况有可能变化的信息,增强模型本身对变化的感知力。
第四个思路是特征工程。我们经常说,一个模型的上限其实是由特征来决定的,所以,建议参赛者在建模的时候,不要忽略特征工程可以带来的收益。
本次比赛提供的数据特征虽然都是相同的,但是选手可以通过自己去挖掘数据中的特征统计值、以及数据之间的组合方法和变换方式,去发现更多的、有统计含义的信息来丰富特征,可能会达到更好的预测效果。
直播回放地址:
【赛事分享】2021 SIGSPATIAL GISCUP 滴滴ETA赛题解析-哔哩哔哩】
https://b23.tv/eBnmgc
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

(点击“阅读原文”了解赛事更多信息)