Hadoop集群配置(一)
文章目录
- 一、 实验目标
- 二、 实验内容
- 三、 实验步骤
-
- 1、网卡配置,配置固定IP
- 2、关闭防火墙
- 3、关闭 selinux
- 4、配置主机名
- 5、安装java
- 6、添加hosts
- 7、安装SSH server、配置SSH无密码登陆
- 8、安装hadoop与配置
-
- 8.1、 将hadoop添加到环境变量中
- 8.2、配置hadoop-env.sh
- 8.3、配置core-site.xml
- 8.4、配置hdfs-site.xml
- 8.5、配置mapred-site.xml
- 8.6、配置yarn-site.xml
- 8.7、配置workers 文件
- 9、启动集群
-
- 9.1、格式化NameNode
- 9.2、启动HDFS
- 9.3、启动YARN
- 10、上传文件到集群
-
- 10.1、上传小文件
- 10.2、上传大文件
一、 实验目标
搭建Hadoop、Spark集群,掌握MapReduce编程模型,实现二次排序。
二、 实验内容
-
搭建Hadoop、Spark集群。
-
使用MapReduce或者Spark方式实现二次排序。
三、 实验步骤
以下为所有虚拟机的预先配置处理。
1、网卡配置,配置固定IP
[root@192 network-scripts]# cd /etc/sysconfig/network-scripts/
[root@192 network-scripts]# ls
ifcfg-ens33 ifdown-ippp ifdown-routes ifup ifup-ipv6 ifup-ppp ifup-tunnel
ifcfg-lo ifdown-ipv6 ifdown-sit ifup-aliases ifup-isdn ifup-routes ifup-wireless
ifdown ifdown-isdn ifdown-Team ifup-bnep ifup-plip ifup-sit init.ipv6-global
ifdown-bnep ifdown-post ifdown-TeamPort ifup-eth ifup-plusb ifup-Team network-functions
ifdown-eth ifdown-ppp ifdown-tunnel ifup-ippp ifup-post ifup-TeamPort network-functions-ipv6
[root@192 network-scripts]# vi ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static # => 设置为静态IP,static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=e151e1e4-14cd-477a-8b13-89464e7a5330
DEVICE=ens33 #网卡名
ONBOOT=yes # => 设置网卡启动方式为 开机启动
IPADDR=192.168.233.233 # => 设置的静态IP地址(compute设置为200)
NETMASK=255.255.255.0 # => 子网掩码
GATEWAY=192.168.233.2 # => 配置 网关地址
DNS1=192.168.233.2 # => 配置DNS地址(为网关地址)
重新启动服务
[root@192 network-scripts]# service network restart
重新连接centos,并查看ip
[root@192 ~]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.233.233 netmask 255.255.255.0 broadcast 192.168.233.255
inet6 fe80::9d76:3c8b:d37:c5e2 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:86:96:ca txqueuelen 1000 (Ethernet)
RX packets 13100 bytes 17072119 (16.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3881 bytes 287068 (280.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 136 bytes 11840 (11.5 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 136 bytes 11840 (11.5 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
2、关闭防火墙
[root@192 ~]# systemctl stop firewalld # 临时关闭
[root@192 ~]# systemctl disable firewalld # 禁止开机启动
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
3、关闭 selinux
[root@192 ~]# getenforce # 查看
Enforcing
[root@192 ~]# sestatus # 查看状态
SELinux status: enabled
SELinuxfs mount: /sys/fs/selinux
SELinux root directory: /etc/selinux
Loaded policy name: targeted
Current mode: enforcing
Mode from config file: enforcing
Policy MLS status: enabled
Policy deny_unknown status: allowed
Max kernel policy version: 31
[root@192 ~]# setenforce 0 # 临时关闭,设置后需要重启才能生效
[root@192 ~]# vi /etc/selinux/config # 永久关闭
[root@192 ~]# cat /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
#SELINUX=enforcing
SELINUX=disabled
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
[root@192 ~]# sestatus # 重启后
SELinux status: disabled
4、配置主机名
[root@192 ~]# vi /etc/hostname
master
localhost.localdomain
:wq
[root@192 ~]# hostname
192.168.233.233
[root@192 ~]# hostnamectl
Static hostname: master
Transient hostname: 192.168.233.233
Icon name: computer-vm
Chassis: vm
Machine ID: c9ea968579cf4f25b4471c73e6cd6e4a
Boot ID: 62ebc6095a2944f8be8f5003dd9f6231
Virtualization: vmware
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-1160.el7.x86_64
Architecture: x86-64
[root@192 ~]# reboot
[root@master ~]#
5、安装java
jdk-8u291-linux-x64.rpm # 上传到服务器
[root@master ~]# rpm -ivh jdk-8u291-linux-x64.rpm
警告:jdk-8u291-linux-x64.rpm: 头V3 RSA/SHA256 Signature, 密钥 ID ec551f03: NOKEY
准备中... ################################# [100%]
正在升级/安装...
#### 查看安装目录 ####
[root@master java]# cd jdk1.8.0_291-amd64/
[root@master jdk1.8.0_291-amd64]# ls
bin javafx-src.zip legal man src.zip
COPYRIGHT jmc.txt lib README.html THIRDPARTYLICENSEREADME-JAVAFX.txt
include jre LICENSE release THIRDPARTYLICENSEREADME.txt
#### 配置环境变量 #####
[root@master jdk1.8.0_291-amd64]# vi ~/.bashrc
###添加如下环境###
# set java environment######
JAVA_HOME=/usr/java/jdk1.8.0_291-amd64
JRE_HOME=/usr/java/jdk1.8.0_291-amd64/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
# end #########
[root@master jdk1.8.0_291-amd64]# source ~/.bashrc #立即生效
[root@master ~]# java -version
java version "1.8.0_291"
Java(TM) SE Runtime Environment (build 1.8.0_291-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.291-b10, mixed mode)
6、添加hosts
| 类型 | IP | 主机名 |
|---|---|---|
| master | 192.168.233.233 | master |
| slave1 | 192.168.233.234 | slave1 |
| slave2 | 192.168.233.235 | slave2 |
在master主机下,添加slave1,slave2 如下配置:
[root@master ~]# vi /etc/hosts
### 添加如下
192.168.233.233 master
192.168.233.235 slave2
192.168.233.234 slave1
### 测试是否可以 ping 通
[root@master ~]# ping master
PING master (192.168.233.233) 56(84) bytes of data.
64 bytes from master (192.168.233.233): icmp_seq=1 ttl=64 time=0.097 ms
64 bytes from master (192.168.233.233): icmp_seq=2 ttl=64 time=0.023 ms
--- slave1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.023/0.060/0.097/0.037 ms
[root@master ~]# ping slave2
PING slave2 (192.168.233.235) 56(84) bytes of data.
64 bytes from slave2 (192.168.233.235): icmp_seq=1 ttl=64 time=2.13 ms
--- slave2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 2.134/2.134/2.134/0.000 ms
同理在slave1添加master和slave2 , 在slave2 添加master和slave1 .
注意不要添加在localhost后面(导致后面开启的服务只能在localhost访问),导致其他服务错误。
7、安装SSH server、配置SSH无密码登陆
这里的centos7min版默认安装了ssh
[root@slave2 ~]# systemctl status sshd.service
● sshd.service - OpenSSH server daemon
Loaded: loaded (/usr/lib/systemd/system/sshd.service; enabled; vendor preset: enabled)
Active: active (running) since 日 2021-06-20 23:26:36 CST; 20min ago
Docs: man:sshd(8)
man:sshd_config(5)
Main PID: 899 (sshd)
CGroup: /system.slice/sshd.service
└─899 /usr/sbin/sshd -D
配置master通过SSH无密码登陆slave
master 机器上生成秘钥对上进行如下配置 生成密钥对:
[root@master ~]# ssh-keygen -t rsa
[root@master ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:w+BO37iDUngU5SLBj8we1gzCo84ieZW+vRJ6lIztbQQ root@master
The key's randomart image is:
+---[RSA 2048]----+
| . .. .. |
| + o... |
| . =.Bo.. |
|. Eo=+ |
|o. O *o S |
|+oo Xo+. + |
|o. + O..o . |
| . * = .. |
| . +.... |
+----[SHA256]-----+
# 三次回车默认即可
[root@master ~]# ls -a
. anaconda-ks.cfg .bash_logout .bashrc jdk-8u291-linux-x64.rpm .tcshrc
.. .bash_history .bash_profile .cshrc .ssh
# ssh-copy-id命令可以将你的公共密钥填充到一个远程机器上的authorized_keys文件中
[root@master ~]# ssh-copy-id slave1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'slave1 (192.168.233.234)' can't be established.
ECDSA key fingerprint is SHA256:TltGk849++Z8CaQ57MuIbagnImZGK1et3VqRh98rBN4.
ECDSA key fingerprint is MD5:cd:01:58:44:6c:09:78:78:58:0d:f5:26:5c:35:d5:fe.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@slave1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'slave1'"
and check to make sure that only the key(s) you wanted were added.
# 测试免密ssh登录
[root@master ~]# ssh slave1
Last login: Wed Jun 23 18:30:45 2021 from 192.168.233.1
[root@slave1 ~]# exit
登出
Connection to slave1 closed.
[root@master ~]# ssh-copy-id master # 自己免密登录自己
# 同理添加其他机器,使得互相之间可以免密登录
注意自己免密自己
8、安装hadoop与配置
集群部署规划:
| master | slave1 | slave2 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
- NameNode和SecondaryNameNode不安装在同一台服务器(因为占用内存比较多)。
- ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台服务器。
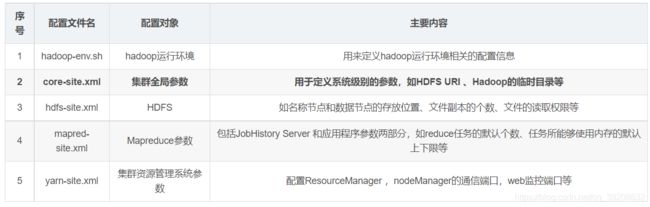
配置Hadoop的主要5个文件
将hadoop-2.7.5.tar.gz上传到服务器,并解压。
[root@master ~]# cp hadoop-2.7.5.tar.gz /opt/
[root@master opt]# ls
hadoop-2.7.5.tar.gz
[root@master opt]# tar -xvf hadoop-2.7.5
[root@slave1 hadoop-2.7.5]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
8.1、 将hadoop添加到环境变量中
### set hadoop environment
export HOME=/opt/hadoop-2.7.5
export PATH=$HOME/bin:$HOME/sbin:$PATH
### end #######
[root@master hadoop]# source ~/.bashrc
[root@master hadoop]# hadoop version
Hadoop 2.7.5
Subversion https://[email protected]/repos/asf/hadoop.git -r 18065c2b6806ed4aa6a3187d77cbe21bb3dba075
Compiled by kshvachk on 2017-12-16T01:06Z
Compiled with protoc 2.5.0
From source with checksum 9f118f95f47043332d51891e37f736e9
This command was run using /opt/hadoop-2.7.5/share/hadoop/common/hadoop-common-2.7.5.jar
[root@master hadoop]#
8.2、配置hadoop-env.sh
配置hadoop使用的java环境
[root@master hadoop]# cat hadoop-env.sh
...
# The java implementation to use.
export JAVA_HOME=${JAVA_HOME} # 使用环境变量JAVA_HOME
...
[root@master hadoop]# echo $JAVA_HOME
/usr/java/jdk1.8.0_291-amd64
## 配置JAVA时候已经指定JAVA_HOME环境变量,因此这里可以使用默认
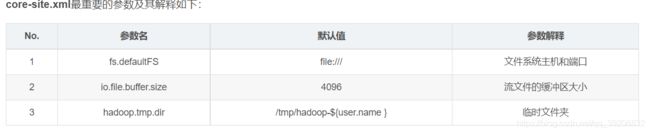
8.3、配置core-site.xml
[root@master hadoop]# cp core-site.xml core-site.xml.bak
[root@master hadoop]# vi core-site.xml
.....
<configuration>
<!-- 指定hdfs的nameservice为master -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
### hdfs://master:9000 这个这里报错,可能因为master包含下划线###
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.5/tmp</value>
</property>
</configuration>
.....
8.4、配置hdfs-site.xml

[root@master hadoop]# cp hdfs-site.xml hdfs-site.xml.bak
[root@master hadoop]# vi hdfs-site.xml
....
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
<description>NameNode对外暴露的web端口</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:9868</value>
<description>Secondary NameNode对外暴露的web端口</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>设置副本数</description>
</property>
...
8.5、配置mapred-site.xml
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
....
<configuration>
<!-- 指定mapreduce框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
....
8.6、配置yarn-site.xml
[root@master hadoop]# cp yarn-site.xml yarn-site.xml.bak
[root@master hadoop]# vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
<description>resourcemanager</description>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandle</value>
<description>NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>由于我的测试机内存少,所以就关闭虚拟内存检测s</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>slave1:8025</value>
<description>The hostname of the RM.</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>slave1:8030</value>
<description>The hostname of the RM.</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>slave1:8050</value>
<description>The hostname of the RM.</description>
</property>
</configuration>
8.7、配置workers 文件
[root@master hadoop]# cp slaves slaves.bak
[root@master hadoop]# vi slaves
[root@master hadoop]# cat slaves
## 将localhost删除,添加slave
master
slave1
slave2
将master机器的opt目录下的hadoop-2.7.5拷贝到slave1,slave2主机的opt目录下,同时将.barshrc文件拷贝过去,并使用source激活一下。
9、启动集群
9.1、格式化NameNode
如果集群是第一次启动,需要格式化NameNode( 注意: 格式化NameNode会产生新的集群id,导致NameNode和DataNode集群的id不一致,集群找不到以往的数据。如果集群在运行中报错,需要重新格式化NameNode的话,一定要先停止NameNode和DataNode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
[root@master hadoop]# hdfs namenode -format
9.2、启动HDFS
启动HDFS
[root@master sbin]# ./start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-namenode-master.out
slave1: starting datanode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-datanode-slave1.out
slave2: starting datanode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-datanode-slave2.out
master: starting datanode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-datanode-master.out
Starting secondary namenodes [slave2]
slave2: starting secondarynamenode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-secondarynamenode-slave2.out
[root@master sbin]# jps
17074 Jps
16856 DataNode
16732 NameNode
[root@master sbin]#
查看两个slave:
### slave1
[root@slave1 logs]# jps
15920 Jps
15719 DataNode
### slave2
[root@slave2 logs]# jps
15286 SecondaryNameNode
15192 DataNode
15452 Jps
如果发现对应的服务没起来,需要查看logs目录下的日志,查看java抛出的异常进行解决( 解决后最好把 logs,tmp 目录删掉, 再重写新初始化)
访问master:9870 (192.168.233.235:9870), 查看web管理页面,如下:

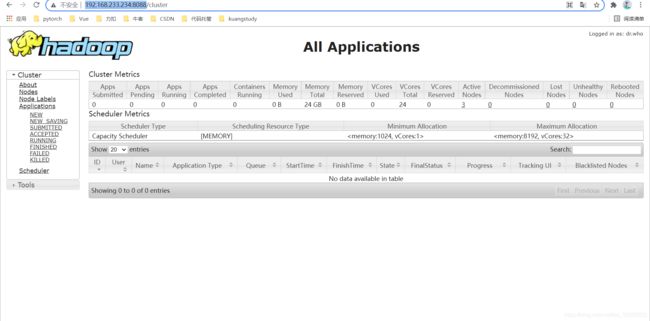
9.3、启动YARN
在slave2启动ResourceManager
[root@slave2 sbin]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.5/logs/yarn-root-resourcemanager-slave1.out
slave1: Warning: Permanently added the ECDSA host key for IP address '192.168.233.234' to the list of known hosts.
master: starting nodemanager, logging to /opt/hadoop-2.7.5/logs/yarn-root-nodemanager-master.out
slave2: starting nodemanager, logging to /opt/hadoop-2.7.5/logs/yarn-root-nodemanager-slave2.out
slave1: starting nodemanager, logging to /opt/hadoop-2.7.5/logs/yarn-root-nodemanager-slave1.out
[root@slave1 hadoop]# jps
18594 ResourceManager
18951 Jps
18425 DataNode
18702 NodeManager
##查看master和slave2
#####slave2
[root@slave2 logs]# jps
16481 Jps
15286 SecondaryNameNode
15192 DataNode
16344 NodeManager
#####master
[root@master sbin]# jps
21908 NodeManager
20727 DataNode
22056 Jps
20602 NameNode
可以看到每个服务器都跑起来一个NodeManager, slave1开启一个ResourceManager。
访问slave1:8088(默认端口)(http://192.168.233.234:8088/)
yarn.resourcemanager.webapp.address
参数解释:ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。
默认值:${yarn.resourcemanager.hostname}:8088
可以修改这个属性自定义端口
访问web ui 地址 可以查看YARN资源调度页面:
10、上传文件到集群
10.1、上传小文件
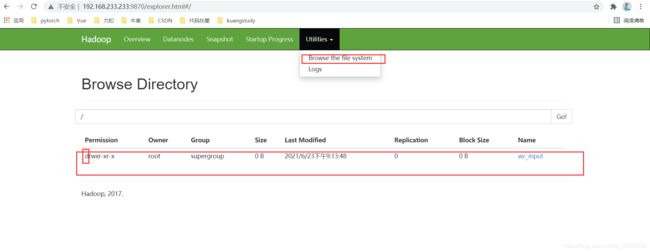
# 创建目录
[root@master ~]# hadoop fs -mkdir /wc_input
# 上传小文件
[root@master ~]# hadoop fs -put ~/wc_input/wordcount.txt /wc_input
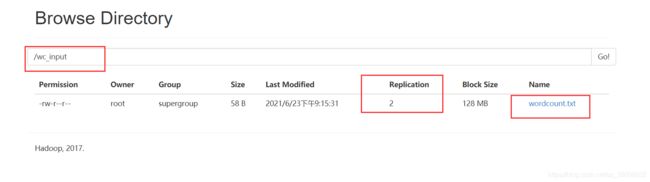
查看DataNode中数据的存储:
[root@master ~]# cd /opt/hadoop-2.7.5/tmp/dfs/data/
[root@master data]# ls
current in_use.lock
[root@master data]# cd current/
[root@master current]# ls
BP-1679516797-192.168.233.233-1624450918458 VERSION
[root@master current]# cd BP-1679516797-192.168.233.233-1624450918458/
[root@master BP-1679516797-192.168.233.233-1624450918458]# ls
current scanner.cursor tmp
[root@master BP-1679516797-192.168.233.233-1624450918458]# cd current/
dfsUsed finalized/ rbw/ VERSION
[root@master BP-1679516797-192.168.233.233-1624450918458]# cd current/finalized/subdir0/subdir0/
[root@master subdir0]# ls
blk_1073741825 blk_1073741825_1001.meta
[root@master subdir0]# cat blk_1073741825
lixibin
lixibin
luanqi
luanqi
lihaiting
lihaiting
wanghao
[root@master subdir0]#
slave1中
[root@slave1 subdir0]# pwd
/opt/hadoop-2.7.5/tmp/dfs/data/current/BP-1679516797-192.168.233.233-1624450918458/current/finalized/subdir0/subdir0
[root@slave1 subdir0]# ls
blk_1073741825 blk_1073741825_1001.meta
[root@slave1 subdir0]# cat blk_1073741825
lixibin
lixibin
luanqi
luanqi
lihaiting
lihaiting
wanghao
slave2中
[root@slave2 finalized]# pwd
/opt/hadoop-2.7.5/tmp/dfs/data/current/BP-1679516797-192.168.233.233-1624450918458/current/finalized
[root@slave2 finalized]# ls
[root@slave2 finalized]#
可以看到数据存储了两份。
10.2、上传大文件
上传到根目录下:
[root@master subdir0]# hadoop fs -put ~/hadoop-2.7.5.tar.gz /
[root@master subdir0]#

同理查看在DataNode中的存储:
[root@master subdir0]# ls
blk_1073741825 blk_1073741826 blk_1073741827
blk_1073741825_1001.meta blk_1073741826_1002.meta blk_1073741827_1003.meta
[root@master subdir0]# cat blk_1073741826 >> recover.tar.gz
[root@master subdir0]# cat blk_1073741827 >> recover.tar.gz
[root@master subdir0]# ls
blk_1073741825 blk_1073741826 blk_1073741827 recover.tar.gz
blk_1073741825_1001.meta blk_1073741826_1002.meta blk_1073741827_1003.meta
[root@master subdir0]# ll
总用量 639372
-rw-r--r-- 1 root root 58 6月 23 21:15 blk_1073741825
-rw-r--r-- 1 root root 11 6月 23 21:15 blk_1073741825_1001.meta
-rw-r--r-- 1 root root 134217728 6月 23 21:30 blk_1073741826
-rw-r--r-- 1 root root 1048583 6月 23 21:30 blk_1073741826_1002.meta
-rw-r--r-- 1 root root 82711846 6月 23 21:30 blk_1073741827
-rw-r--r-- 1 root root 646195 6月 23 21:30 blk_1073741827_1003.meta
-rw-r--r-- 1 root root 216929574 6月 23 21:34 recover.tar.gz
[root@master subdir0]# mv recover.tar.gz ~
[root@master ~]# ll
总用量 749100
-rw-------. 1 root root 1232 6月 20 21:06 anaconda-ks.cfg
-rw-r--r-- 1 root root 216929574 6月 20 23:13 hadoop-2.7.5.tar.gz #####
-rw-r--r-- 1 root root 114063112 6月 20 19:15 jdk-8u291-linux-x64.rpm
-rw-r--r-- 1 root root 216929574 6月 23 21:34 recover.tar.gz ####recover.tar.gz 就是hadoop-2.7.5.tar.gz
drwxr-xr-x 2 root root 27 6月 23 16:02 wc_input
drwxr-xr-x 2 root root 88 6月 23 16:36 wc_output
[root@master ~]# tar -xvf recover.tar.gz
[root@master ~]# ls
anaconda-ks.cfg hadoop-2.7.5 hadoop-2.7.5.tar.gz jdk-8u291-linux-x64.rpm recover.tar.gz wc_input wc_output
[root@master ~]# cd hadoop-2.7.5
[root@master hadoop-2.7.5]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
###可以看到可以正常解压出hadoop-2.7.5
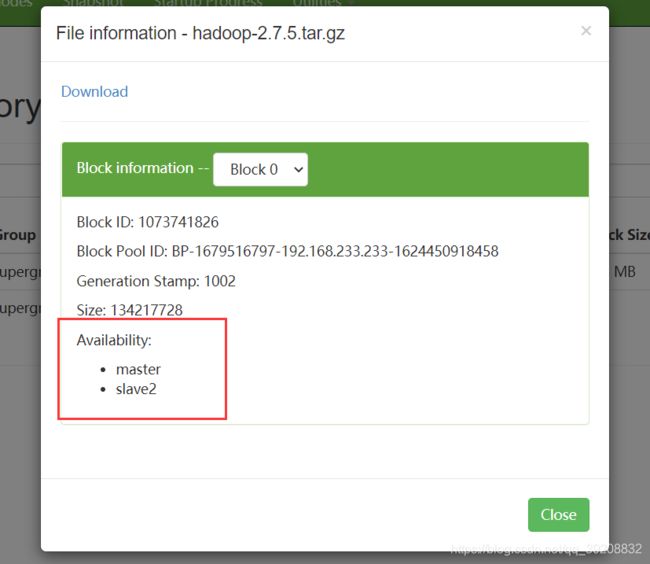
并且如上可以看到存储在哪个节点;