深度学习笔记:CNN+RNN+LSTM
卷积神经网络(Convolutional Neural Network, CNN)
参考博客:https://easyai.tech/ai-definition/cnn/
CNN 是一种前馈神经网络,通常由卷积层(Convolutional Layer),池化层(Pooling Layer)和全连接层(Fully Connected Layer,对应经典的 NN)组成。卷积层负责提取图像中的局部特征;池化层用来大幅降低参数量级(降维);全连接层类似传统神经网络的部分,用来输出想要的结果。
两大特点:
- 能够有效的将大数据量的图片降维成小数据量
- 能够有效的保留图片特征,符合图片处理的原则
解决的问题
- 图像需要处理的数据量太大,导致成本很高,效率很低 —“将复杂问题简化”,把大量参数降维成少量参数,再做处理。
- 图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高—用类似视觉的方式保留了图像的特征
卷积——提取特征
上图中左侧的绿色大矩阵表示输入数据,在绿色大矩阵上不断运动的黄色小矩阵叫做卷积核,每次卷积核运动到一个位置,它的每个元素就与其覆盖的输入数据对应元素相乘求积,然后再将整个卷积核内求积的结果累加,结果填注到右侧红色小矩阵中。
卷积核横向每次平移一列,纵向每次平移一行。最后将输入数据矩阵完全覆盖后,生成完整的红色小矩阵就是卷积运算的结果。

池化层(下采样)——数据降维,避免过拟合
池化层简单说就是下采样,他可以大大降低数据的维度

上图中,我们可以看到,原始图片是20×20的,我们对其进行下采样,采样窗口为10×10,最终将其下采样成为一个2×2大小的特征图。之所以这么做的原因,是因为即使做完了卷积,图像仍然很大(因为卷积核比较小),所以为了降低数据维度,就进行下采样。
总结:池化层相比卷积层可以更有效的降低数据维度,这么做不但可以大大减少运算量,还可以有效的避免过拟合。
全连接层——输出结果
经过卷积层和池化层降维过的数据,全连接层才能”跑得动”,不然数据量太大,计算成本高,效率低下。

在经过多轮卷积层和池化层的处理之后,在CNN的最后一般会由1到2个全连接层来给出最后的分类结果。经过几轮卷积层和池化层的处理之后,可以认为图像中的信息已经被抽象成了信息含量更高的特征。我们可以将卷积层和池化层看成自动图像特征提取的过程。在提取完成之后,仍然需要使用全连接层来完成分类任务。
循环神经网(Recurrent Neural Network,RNN)
参考:https://zhuanlan.zhihu.com/p/30844905
https://www.jianshu.com/p/c0a2e3984128
RNN用于处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNN能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关。
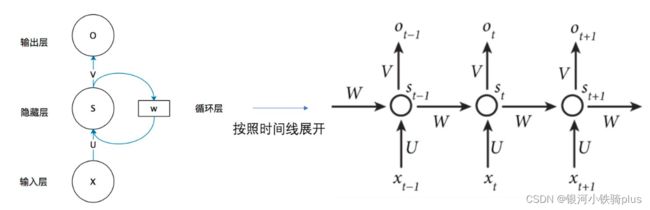
网络在t时刻接收到输入 xt 之后,隐藏层的值是 [公式] ,输出值是 [公式] 。关键一点是, [公式] 的值不仅仅取决于 [公式] ,还取决于 [公式] 。
我们来看输入,共分为两个时刻,其中t0=1,t1=2,输入是如何转换为输出的呢,下面逐步进行分解。
- 初始时刻,没有上一个隐层的输出,因此初始化为[0,0]。
- 将上一个隐层的输出与当前时刻输入xt进行拼接,得到第一个隐藏计算的输入。
- 隐层内计算,将拼接后的输入值与初始权重W进行相乘,同时加上偏置b,得到一个基础值,值得注意的是这个W和b是一个更新的过程,需要不断迭代计算。
- 第一次激活,这次激活是对s(t)进行激活,采用的激活函数为tanh函数,将上一步得到的基础值代入到tanh函数中,得到的输出即为s(t),这个s(t)将作为下一层的s(t-1)参与下一个隐层的计算。
- 当前层输出基础值计算,将s(t)和新的权重V相乘加上偏置b,得到当前层输出基础值。
- 当前层最终输出,加上激活函数以后就是当前层的输出啦,此时采用的激活函数一般为softmax()。
前向传播算法:
从循环神经网络的原理,我们可以知道对于一个有序序列,假设有t个时刻,那么他会经过t次隐藏层的计算,以其中任意一次为案例进行说明。当前隐藏层状态h(t)由当前的输入x(t)和上一层的输出h(t-1)决定。

其中,\sigma代表中激活函数,其实在RNN中就两种,一种是tanh函数用于将值转化到0-1之间,一种是softmax函数,用于输出概率值,在隐藏层中选择的是tanh函数。当前隐藏层的输出用如下函数计算:

转换为最终的预测值输出就是:

这里的激活函数是softmax函数因为要做最终的分类用了。值得一提的是,损失函数就是yp和y之间的差值,可以用对数损失函数,平方损失函数等等,根据问题的不同来选择。
长短期记忆(Long short-term memory, LSTM)
参考学习:https://zhuanlan.zhihu.com/p/32085405
https://blog.csdn.net/fan3652/article/details/95615096
LSTM,全称 Long Short Term Memory (长短期记忆) 是一种特殊的递归神经网络 。主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。它由Hochreiter & Schmidhuber (1997)
提出,并被Alex GravesAlexGraves进行了改良和推广,现在在机器学习领域被广泛使用。简单来说,LSTM相比普通的RNN,能够在更长的序列中有更好的表现,它能通过门的控制保留很久之前的特征,这是它最大的特点。
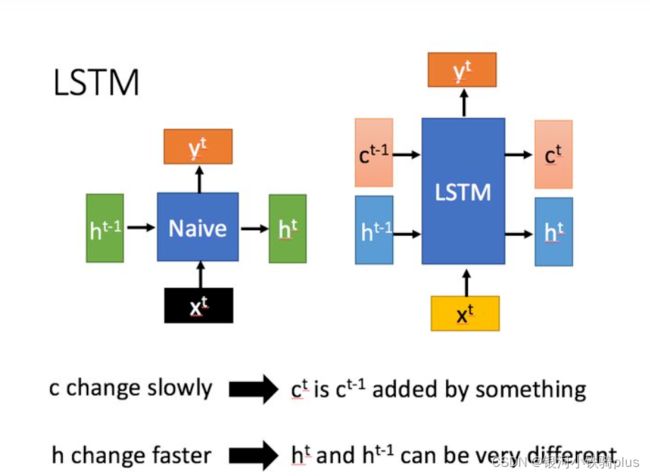
相比RNN只有一个传递状态ht ,LSTM有两个传输状态,一个 ct (cell state),和一个ht (hidden state)。(Tips:RNN中的 ht 对于LSTM中的 ct )
其中对于传递下去的 ct 改变得很慢,通常输出的 ct 是上一个状态传过来的 ct-1 加上一些数值。
而 ht 则在不同节点下往往会有很大的区别。
LSTM的关键,就是怎样控制长期状态c。在这里,LSTM的思路是使用三个控制开关。
- 第一个开关,负责控制继续保存长期状态c;
- 第二个开关,负责控制把即时状态输入到长期状态c;
- 第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出。
分别对应以下三个门:
- 输入门 :控制当前时刻的候选状态 有多少信息需要保存;
- 遗忘门 :控制上一个时刻的内部状态 需要遗忘多少信息;
- 输出门:控制当前时刻的内部状态ct有多少信息需要输出给外部状态。
