贝叶斯神经网络----从贝叶斯准则到变分推断
前言
在认识贝叶斯神经网络之前,建议先复习联合概率,条件概率,边缘概率,极大似然估计,最大后验估计,贝叶斯估计这些基础
极大似然估计
一个神经网络模型可以视为一个条件分布模型 p ( y ∣ x , w ) p(y|x,w) p(y∣x,w),即在 x , w x,w x,w已知的条件下求出 y y y的分布,如果是分类问题,该分布对应分到各类的概率,如果是回归问题,则认为是高斯分布并取均值作为预测结果,相应地,神经网络的学习可以视作一个最大似然估计(Maximum Likelihood Estimation,MLE)
w M L E = a r g m a x w log p ( D ∣ w ) = a r g m a x w ∑ i log p ( y i ∣ x i , w ) w^{MLE}=\mathop{argmax}\limits_w \log p(D|w) \\ =\mathop{argmax}\limits_w \sum_i\log p(y_i|x_i,w) wMLE=wargmaxlogp(D∣w)=wargmaxi∑logp(yi∣xi,w)
也就是说,我们要寻找一组这样的 w w w,能够在样本集的所有数据上预测到真实值的概率最大。上式中 D D D对应训练所使用的数据集,回归问题中带入高斯分布可以得到平均平方误差,分类问题则带入逻辑函数可以推导出交叉熵,这一点会单独分一节来讨论。
最大后验概率
极大似然估计和最大后验概率估计的不同在于,在后验概率中,我们认为 w w w取值的机会不是均等的,而极大似然则单一认为 w w w取每个值的概率相同,其实最大后验概率更符合日常的模型,因为高斯模型这种代表“大部分人都是普通人的思想”几乎可见于数学的各个应用领域。
我们假设 w w w事先服从某种分布,一般为高斯分布,即 w w w在某个区间的取值概率是最大的,而不是可能取所有的值,这样一来,损失函数改写为:
w M A P = a r g m a x w log p ( D ∣ w ) p ( w ) = a r g m a x w log p ( D ∣ w ) + log p ( w ) w^{MAP}=\mathop{argmax}\limits_w \log p(D|w)p(w)\\ =\mathop{argmax}\limits_w \log p(D|w)+ \log p(w) wMAP=wargmaxlogp(D∣w)p(w)=wargmaxlogp(D∣w)+logp(w)
最大后验概率准则将 w w w的先验分布考虑进去,寻找这样的 w w w能够获得上式的最小值。
贝叶斯神经网络
传统的神经网络认为每一层的权重是一个“固定”的值,这个固定不是不变,而是在每次前向传播时,权重都只是一个值,而不是一种分布;而贝叶斯神经网络则认为每一个参数都是服从某种分布的,整个过程是建立在分布的基础上进行前向,反向传播的计算,网络的实际参数是根据参数的分布采样得到,我们需要更新的值实际上是参数所对应的分布。
贝叶斯要做的不是确定 w w w,而是求解能否根据观测数据,推测模型参数服从什么分布?即如何确定 p ( w ∣ D ) p(w|D) p(w∣D)?
举个形象一点的例子,如果 D D D是我们养的一批猪,现在我们想根据这批猪的生长状况推测猪平时过得怎么样,如果猪看起来无精打采的,可能生活环境不太好,比如居住环境过于潮湿,饲料供应不新鲜,如果猪活蹦乱跳的,大概率住的生活环境也比较优渥,这里的生活环境就可以认为是参数 w w w。我们通过数据 D D D来推测 w w w的过程就是“inference”
根据贝叶斯准则,我们有:
p ( w ∣ D ) = p ( D , w ) p ( D ) = p ( D ∣ w ) p ( w ) p ( D ) p o s t e r i o r = l i k e l i h o o d ∗ p r i o r e v i d e n c e p(w|D)=\frac{p(D,w)}{p(D)}=\frac{p(D|w)p(w)}{p(D)}\\ posterior=\frac{likelihood*prior}{evidence} p(w∣D)=p(D)p(D,w)=p(D)p(D∣w)p(w)posterior=evidencelikelihood∗prior
上式里面 p ( D ∣ w ) p(D|w) p(D∣w)是可计算的,在参数 w w w确定时,可以通过 ∑ i p ( y i ∣ x i , w ) \sum_{i}p(y_i|x_i,w) ∑ip(yi∣xi,w)求解, p ( w ) p(w) p(w)也是可计算的,因为我们事先假设其服从某种分布。
但是难解的地方在于 p ( D ) p(D) p(D),因为 p ( D ) p(D) p(D)的计算需要知道所有潜在的 w w w所对应的 p ( D , w ) p(D,w) p(D,w),即:
p ( D ) = ∫ w 0 . . . ∫ w N − 1 p ( D , w ) d w 0 . . . d w N − 1 p(D)=\int_{w_0}...\int_{w_{N-1}}p(D,w)dw_0...dw_{N-1} p(D)=∫w0...∫wN−1p(D,w)dw0...dwN−1
其中 N N N为参数 w w w的维度。这个问题难解是因为我们需要对多个可能的模型计算联合概率,在高维情况下这是很难实现的,由此引入变分推断来解决这个问题。
变分推断(Variational Inference)
既然我们通过解析的方式不可能得到后验概率 p ( w ∣ D ) p(w|D) p(w∣D)的分布,我们能否寻找一个替代品来取代 p ( w ∣ D ) p(w|D) p(w∣D)?
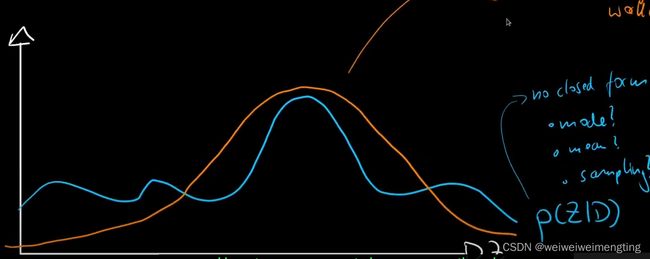
为什么可以这样考虑?
我们实际上的分布 p ( w ∣ D ) p(w|D) p(w∣D)可能是一个很复杂的曲线,他可能是不对称的,多峰的,但是在某些特征上,比如最值点,我们仍然可以使用高斯分布来近似他,因为最值点代表了我们实际上最为关注的信息,所以现在退而求其次,我们要找的不是 p ( w ∣ D ) p(w|D) p(w∣D),而是寻找什么样的高斯分布能够最接近这个分布。
现在的问题变成:
我们在所有可能的高斯分布中找出一个分布 q ( w ) , q ( w ) ∈ Q q(w), q(w) \in Q q(w),q(w)∈Q,使得这个分布能够最大程度上拟合后验分布 p ( w ∣ D ) p(w|D) p(w∣D),常用来衡量两个分布相似性的评价指标为KL散度:
K L ( q ( w ) ∣ ∣ p ( w ∣ D ) ) = E w ∈ q ( w ) [ log q ( w ) p ( w ∣ D ) ] = ∫ w q ( w ) log q ( w ) p ( w ∣ D ) d w KL(q(w)||p(w|D))=E_{w\in q(w)}[\log \frac{q(w)}{p(w|D)}]\\ =\int_w q(w)\log \frac{q(w)}{p(w|D)}dw KL(q(w)∣∣p(w∣D))=Ew∈q(w)[logp(w∣D)q(w)]=∫wq(w)logp(w∣D)q(w)dw
我们要找的是:
q ∗ ( w ) = arg m i n q ( w ) ∈ Q ( K L ( q ( w ) ∣ ∣ p ( w ∣ D ) ) ) q^*(w)=\mathop{\arg min} \limits_{q(w)\in Q}(KL(q(w)||p(w|D))) q∗(w)=q(w)∈Qargmin(KL(q(w)∣∣p(w∣D)))
为什么称上面的问题为变分(variational)问题?
从可能的函数集合中寻找一个满足条件的函数,这称为“变分”,所以我们现在想要寻找一个函数,以便能够进行推理,所以称为变分推断(Variational Inference)
接着来看上面公式的求解,由于我们不知道后验概率,所以将原始的后验概率用贝叶斯准则进行替换:
K L ( q ( w ) ∣ ∣ p ( w ∣ D ) ) = ∫ w q ( w ) log q ( w ) p ( w ∣ D ) d w = ∫ w q ( w ) log q ( w ) ⋅ p ( D ) p ( w , D ) d w = ∫ w q ( w ) log q ( w ) p ( w , D ) d w + ∫ w q ( w ) log p ( D ) d w = E w ∈ q ( w ) log [ q ( w ) p ( w , D ) ] + E w ∈ q ( w ) log p ( D ) = − E w ∈ q ( w ) log [ p ( w , D ) q ( w ) ] + log p ( D ) = − E w ∈ q ( w ) log [ p ( w , D ) ] + E w ∈ q ( w ) log [ q ( w ) ] + log p ( D ) KL(q(w)||p(w|D))\\ =\int_w q(w)\log \frac{q(w)}{p(w|D)}dw\\ =\int_w q(w)\log \frac{q(w) \cdot p(D)}{p(w,D)}dw \\ =\int_w q(w)\log \frac{q(w)}{p(w,D)}dw + \int_w q(w)\log p(D)dw \\ =E_{w\in q(w)}\log [\frac{q(w)}{p(w,D)}]+E_{w\in q(w)}\log p(D)\\ =-E_{w\in q(w)}\log [\frac{p(w,D)}{q(w)}] + \log p(D)\\ =-E_{w\in q(w)}\log [p(w,D)] + E_{w\in q(w)}\log [q(w)] + \log p(D) KL(q(w)∣∣p(w∣D))=∫wq(w)logp(w∣D)q(w)dw=∫wq(w)logp(w,D)q(w)⋅p(D)dw=∫wq(w)logp(w,D)q(w)dw+∫wq(w)logp(D)dw=Ew∈q(w)log[p(w,D)q(w)]+Ew∈q(w)logp(D)=−Ew∈q(w)log[q(w)p(w,D)]+logp(D)=−Ew∈q(w)log[p(w,D)]+Ew∈q(w)log[q(w)]+logp(D)
上式中最后一项 log p ( D ) \log p(D) logp(D)是一个固定值( p ( D ) p(D) p(D)是通过观测得到的,他不随参数的改变而改变,他是所有可能参数的情况的期望),同时KL散度≥0,因此前面的需要满足: E w ∈ q ( w ) log [ p ( w , D ) ] − E w ∈ q ( w ) log [ q ( w ) ] ≤ log P ( D ) E_{w\in q(w)}\log [p(w,D)] - E_{w\in q(w)}\log [q(w)] \leq \log P(D) Ew∈q(w)log[p(w,D)]−Ew∈q(w)log[q(w)]≤logP(D)
当等号满足的时候,KL散度为零,但是实际上很难成立,所以退而求其次,我们需要让前面的这一项越大越好,反过来说,我们希望 − E w ∈ q ( w ) log [ p ( w , D ) ] + E w ∈ q ( w ) log [ q ( w ) ] -E_{w\in q(w)}\log [p(w,D)] + E_{w\in q(w)}\log [q(w)] −Ew∈q(w)log[p(w,D)]+Ew∈q(w)log[q(w)]越小越好,这称之为Evidence Lower Bound (ELBO),其中evidence指的是后面的 log p ( D ) \log p(D) logp(D),且是前面那一项的下界(Lower Bound)。
我们称:
L ( q ) = E w ∈ q ( w ) log [ p ( w , D ) ] − E w ∈ q ( w ) log [ q ( w ) ] \mathcal{L(q)}=E_{w\in q(w)}\log [p(w,D)] - E_{w\in q(w)}\log [q(w)] L(q)=Ew∈q(w)log[p(w,D)]−Ew∈q(w)log[q(w)]
我们需要最大化 L ( q ) \mathcal{L(q)} L(q),将上式再次使用贝叶斯准则展开,可以写为:
L ( q ) = E w ∈ q ( w ) log [ p ( D ∣ w ) ] + E w ∈ q ( w ) log [ p ( w ) ] − E w ∈ q ( w ) log [ q ( w ) ] \mathcal{L(q)}=E_{w\in q(w)}\log [p(D|w)] + E_{w\in q(w)}\log [p(w)] - E_{w\in q(w)}\log [q(w)] L(q)=Ew∈q(w)log[p(D∣w)]+Ew∈q(w)log[p(w)]−Ew∈q(w)log[q(w)]
所以整个网络的求解过程就是最大化上式,并且上面三项都是可计算的。下面具体解释三项分别怎么计算:
- E w ∈ q ( w ) log [ p ( D ∣ w ) ] E_{w\in q(w)}\log [p(D|w)] Ew∈q(w)log[p(D∣w)]:
在模型参数 w w w确定的条件下,计算 p ( D ∣ w ) p(D|w) p(D∣w)的分布 - E w ∈ q ( w ) log [ p ( w ) ] E_{w\in q(w)}\log [p(w)] Ew∈q(w)log[p(w)]
计算 w w w的先验 p ( w ) p(w) p(w) - E w ∈ q ( w ) log [ q ( w ) ] E_{w\in q(w)}\log [q(w)] Ew∈q(w)log[q(w)]
计算当前的前向传播过程下,假设的 q ( w ) q(w) q(w)的分布,我们前面讲过,网络实际是优化的是什么样的 μ \mu μ和 δ \delta δ形成的高斯分布 q ( w ) q(w) q(w)
贝叶斯神经网络编程实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Normal
import numpy as np
from scipy.stats import norm
import matplotlib.pyplot as plt
class Linear_BBB(nn.Module):
"""
Layer of our BNN.
"""
def __init__(self, input_features, output_features, prior_var=1.):
"""
先验分布是以均值为0,方差为1的高斯分布
Initialization of our layer : our prior is a normal distribution
centered in 0 and of variance 1.
"""
# initialize layers
super().__init__()
# set input and output dimensions
# 输入和输出的维度
self.input_features = input_features
self.output_features = output_features
# initialize mu and rho parameters for the weights of the layer
# 初始化该层的权重和偏置 ====》y = w * x + b
# 该层的每一个权重和偏置都有自己的方差和均值
self.w_mu = nn.Parameter(torch.zeros(output_features, input_features))
self.w_rho = nn.Parameter(torch.zeros(output_features, input_features))
# initialize mu and rho parameters for the layer's bias
# 网络的参数是权重和偏置的期望与方差
# 实际的参数,即参与计算的参数是从这个分布里面采样的
self.b_mu = nn.Parameter(torch.zeros(output_features))
self.b_rho = nn.Parameter(torch.zeros(output_features))
# initialize weight samples (these will be calculated whenever the layer makes a prediction)
self.w = None
self.b = None
# initialize prior distribution for all of the weights and biases
# 假设该层的所有权重和偏置均为正态分布
self.prior = torch.distributions.Normal(0, prior_var)
def forward(self, input):
"""
Optimization process
"""
# sample weights
"""
从均值为0,方差为1的高斯分布中采样一些样本点 u + log(1 + exp(p)) * w'
一种重参数技巧,最早用于VAE中
对于原本服从 N~(u , p)的随机变量w,先不直接根据这个分布采样,而是先根据标准正态分布采样 w_epsilon
随后根据 w = u + log(1 + exp(p)) * w' 得到实际的采样值,这样做的目的是为了便于反向传播
"""
w_epsilon = Normal(0, 1).sample(self.w_mu.shape)
self.w = self.w_mu + torch.log(1 + torch.exp(self.w_rho)) * w_epsilon
# sample bias
b_epsilon = Normal(0, 1).sample(self.b_mu.shape)
self.b = self.b_mu + torch.log(1 + torch.exp(self.b_rho)) * b_epsilon
# record log prior by evaluating log pdf of prior at sampled weight and bias
"""
对已经采样的值,计算其在预先定义的分布上的对数形式得到的值(log_prob(value)是计算value在定义的正态分布(mean,1)中对应的概率的对数)
损失函数是要最大化elbo下界:L = sum[log(q(w))]- sum(log P(w)) - sum(log P(y_i | w, x_i))
"""
# 计算 p(w)
w_log_prior = self.prior.log_prob(self.w)
b_log_prior = self.prior.log_prob(self.b)
self.log_prior = torch.sum(w_log_prior) + torch.sum(b_log_prior)
# record log variational posterior by evaluating log pdf of normal distribution defined by parameters with respect at the sampled values
# 计算 q(w),也有称其为 p(w|theta)的
# q(w) 表示根据当前的网络参数 w_mu,w_rho,b_mu,b_rho 计算q(w),也就是说q(w)就是我们损失函数要求解的分布
self.w_post = Normal(self.w_mu.data, torch.log(1 + torch.exp(self.w_rho)))
self.b_post = Normal(self.b_mu.data, torch.log(1 + torch.exp(self.b_rho)))
self.log_post = self.w_post.log_prob(self.w).sum() + self.b_post.log_prob(self.b).sum()
return F.linear(input, self.w, self.b)
class MLP_BBB(nn.Module):
def __init__(self, hidden_units, noise_tol=.1, prior_var=1.):
# initialize the network like you would with a standard multilayer perceptron, but using the BBB layer
super().__init__()
self.hidden = Linear_BBB(1, hidden_units, prior_var=prior_var)
self.out = Linear_BBB(hidden_units, 1, prior_var=prior_var)
self.noise_tol = noise_tol # we will use the noise tolerance to calculate our likelihood
def forward(self, x):
# again, this is equivalent to a standard multilayer perceptron
x = torch.sigmoid(self.hidden(x))
x = self.out(x)
return x
def log_prior(self):
# calculate the log prior over all the layers
return self.hidden.log_prior + self.out.log_prior
def log_post(self):
# calculate the log posterior over all the layers
return self.hidden.log_post + self.out.log_post
# 损失函数的计算
def sample_elbo(self, input, target, samples):
# we calculate the negative elbo, which will be our loss function
#initialize tensors
outputs = torch.zeros(samples, target.shape[0])
log_priors = torch.zeros(samples)
log_posts = torch.zeros(samples)
log_likes = torch.zeros(samples)
# make predictions and calculate prior, posterior, and likelihood for a given number of samples
# 蒙特卡洛近似,根据给定的样本数采样
# 蒙特卡洛在这里用来计算前向传播的次数,所以蒙特卡洛可能与模型权重的不确定性有关
for i in range(samples):
outputs[i] = self(input).reshape(-1) # make predictions
log_priors[i] = self.log_prior() # get log prior
log_posts[i] = self.log_post() # get log variational posterior
log_likes[i] = Normal(outputs[i], self.noise_tol).log_prob(target.reshape(-1)).sum() # calculate the log likelihood
# calculate monte carlo estimate of prior posterior and likelihood
log_prior = log_priors.mean()
log_post = log_posts.mean()
log_like = log_likes.mean()
# calculate the negative elbo (which is our loss function)
loss = log_post - log_prior - log_like
return loss
def toy_function(x):
return -x**4 + 3*x**2 + 1
# toy dataset we can start with
x = torch.tensor([-2, -1.8, -1, 1, 1.8, 2]).reshape(-1,1)
y = toy_function(x)
net = MLP_BBB(32, prior_var=10)
optimizer = optim.Adam(net.parameters(), lr=.1)
epochs = 1000
for epoch in range(epochs): # loop over the dataset multiple times
optimizer.zero_grad()
# forward + backward + optimize
loss = net.sample_elbo(x, y, 1)
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print('epoch: {}/{}'.format(epoch+1,epochs))
print('Loss:', loss.item())
print('Finished Training')
# samples is the number of "predictions" we make for 1 x-value.
# 网络训练完成后,对于随机给定的输入值 x,计算模型的输出值 y
# samples 表示采样次数,即预测多少次,最后对这些次的结果取平均值
samples = 10
x_tmp = torch.linspace(-5, 5, 100).reshape(-1, 1)
y_samp = np.zeros((samples, 100))
print(x_tmp.shape)
for s in range(samples):
y_tmp = net(x_tmp).detach().numpy()
y_samp[s] = y_tmp.reshape(-1)
plt.plot(x_tmp.numpy(), np.mean(y_samp, axis=0), label='Mean Posterior Predictive')
plt.fill_between(x_tmp.numpy().reshape(-1), np.percentile(y_samp, 2.5, axis=0),
np.percentile(y_samp, 97.5, axis=0), alpha=0.25, label='95% Confidence')
plt.legend()
plt.scatter(x, toy_function(x))
plt.title('Posterior Predictive')
plt.show()
if __name__ == '__main__':
print("done!")