CVPR 2020 最佳论文解读:无需任何监督,即可重建三维图像

作者 | 陈大鑫、蒋宝尚
编辑 | 丛末
我有一张二维照片,能让它变成三维图像么?可以,当前的一些3D电影相册工具,给图片加一个相框也能形成动态效果。
另外,用PS软件,进行一步、两步、三步等等操作后,也可以2D变3D,只不过即使技艺精湛的设计师也需要花费一点时间。

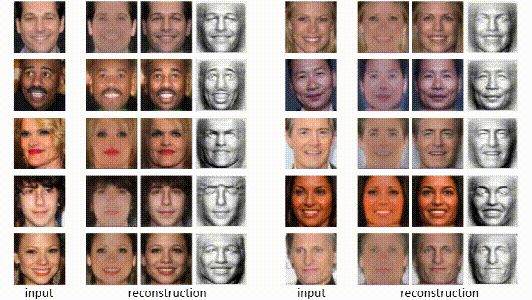
然而,这届的CVPR最佳论文提出了一种无监督的方法,能够常准确地从单目图像中恢复人脸、猫脸和汽车的三维形状。效果如下:

上下左右,前前后后,充分展示了三维图像的“长宽高”☺。重建的三维人脸包含了鼻子、眼睛和嘴的细节,即使在极端的面部表情下表现也非常优秀。

抽象图片与动漫图片也不在话下☝
除了重建三维,二维图像的照明效果也能调一调☝~

无需微调就可逐帧应用,充分实现“你动我也动”☝。
这篇论文也正是因为其提出方法优越的性能和其潜在的应用前景,被选中为CVPR 2020 最佳论文。另外,代码也已经开源。
 论文链接:https://arxiv.org/abs/1911.11130
论文链接:https://arxiv.org/abs/1911.11130
代码地址:https://github.com/elliottwu/unsup3d
项目地址:https://elliottwu.com/projects/unsup3d/
Demo 地址:http://www.robots.ox.ac.uk/~vgg/blog/unsupervised-learning-of-probably-symmetric-deformable-3d-objects-from-images-in-the-wild.html
这篇名为《Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild》的论文由牛津大学的吴尚哲、Christian Rupprecht、Andrea Vedak三位合著。
其中,第一作者是来自香港科技大学2014级的本科生吴尚哲,2018年本科毕业后进入了牛津大学视觉几何组,师从欧洲计算机科学家Andrew Vedaldi,另外,这篇论文的第三作者也是Andrew Zisserman的博士后Andrea Vedaldi。
同样,这项工作也得到了Facebook Research和ERC Horizon 2020研究与创新计划的支持。
1
模型简介与方法介绍

前面也提到,这篇最佳论文最亮的点是:基于原始单目图像学习3D可变形物体类别,而且无需外部监督。
具体而言,其使用的方法是基于一个自动编码器,这个编码器能够将每张输入图像分解为深度、反射率、视点和光照四个组件。整体模型结构如下:
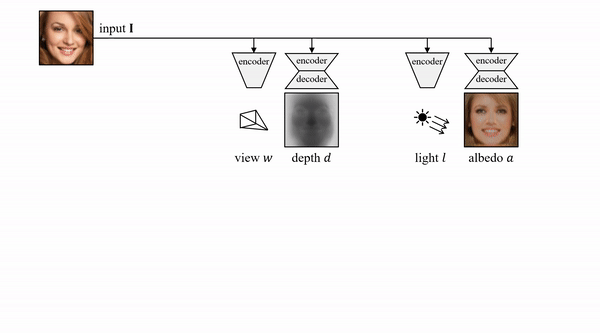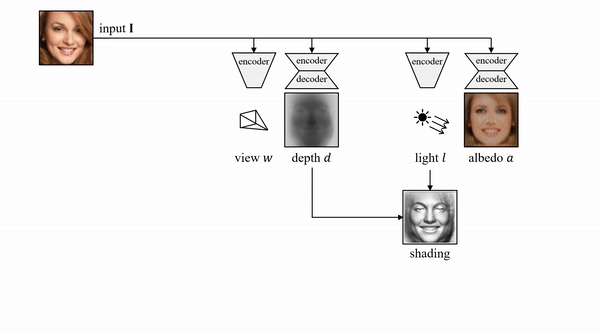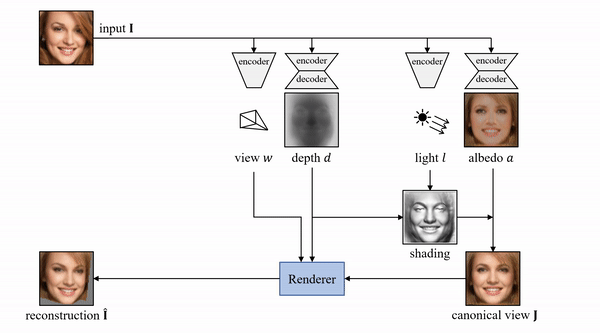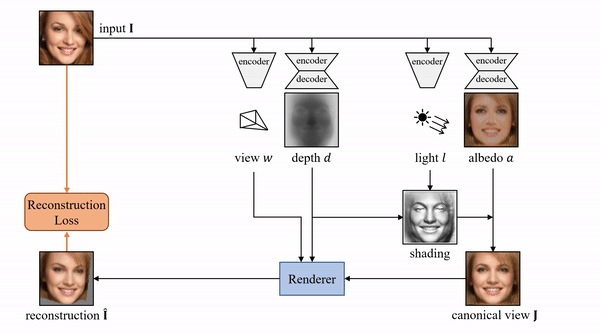
在论文中,作者提到,为了在无监督的情况下分离这些组件,其利用许多物体类别至少在原则上具有对称结构这一事实。
另外,作者通过预测一个对称概率图,对可能对称但不确定对称的物体建模,并与模型的其他组件进行端到端学习。
实验结果表明,作者的方法能够在不需要任何监督和先验形状模型的情况下,非常准确地从单目图像中恢复人脸、猫脸和汽车的三维形状。
在基准测试中,与另一种使用2D图像对应级别的监督方法相比,作者的方法有着优越的准确性。
在具体建模过程中,作者在两种具有挑战性的条件下进行研究,第一个条件是没有2D或3D的ground truth信息(如关键点、分割、深度图或3D模型的先验知识)可用。第二个条件是,该算法必须使用无约束的单目图像集合。
针对这两个条件,作者整体的学习算法过程是:先摄取大量可变形对象类别的单视图图像,然后输出一个深度网络,并且该网络可以根据给定的单一图像估计任何实例的3D形状。
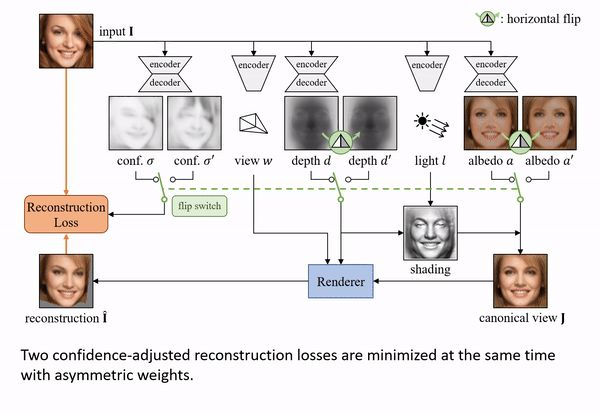
另外,具体的物体实例实际上从来都不是完全对称的,无论是在形状上还是在外观上。由于姿势或其他细节(如发型或面部表情)的变化,形状是不对称的,反射率也可能是非对称的(如猫脸的不对称纹理)。即使当形状和反射率都是对称的,由于不对称的光照,外观仍然可能不对称。
作者用了两种方式解决这个问题。首先,明确地建立光照模型来利用底层的对称性,并表明,通过这样做,模型可以利用光照作为恢复形状的额外线索。其次,扩充模型,以推理物体中潜在的不对称。
值得注意的是,在损失函数方面,作者观察到L1损失函数式对小的几何缺陷敏感,容易导致重建模糊。所以作者添加了一个感知损失项来缓解这个问题。
在训练过程中,作者使用Adam优化器对batch为64的输入图像进行训练,图像大小resize为64×64像素。输出深度和反射率的大小也是64×64。训练大约进行5万次迭代,对于可视化,深度图将上采样到256。
2
实验结果更准确
论文的最后,作者在三个人脸数据集上进行了测试:CelebA、3DFAW和BFM。同时也在猫脸和合成汽车上进行了测试,文章的开头就是部分测试结果,下面是“猫主子”重建结果:

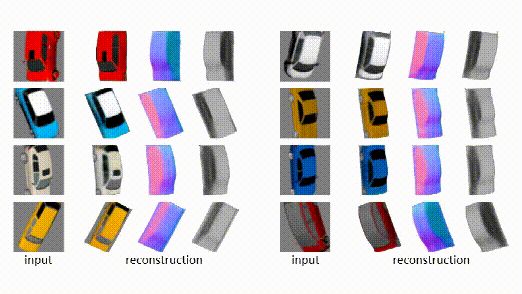
小车重建3D效果:
另外,与完全监督的方法和表现一般的无监督baseline相比,作者的方法在BFM数据集上重建得到的的SIDE误差和MAD误差明显优于baseline并且接近完全监督,如下表损失所示。☟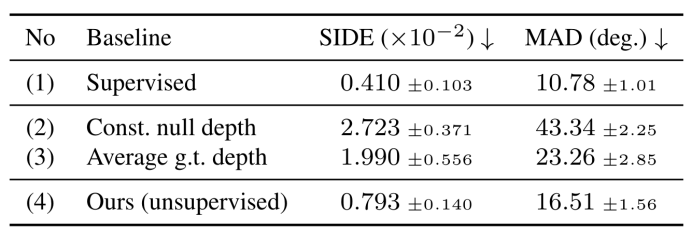
消融实现性能评估☟
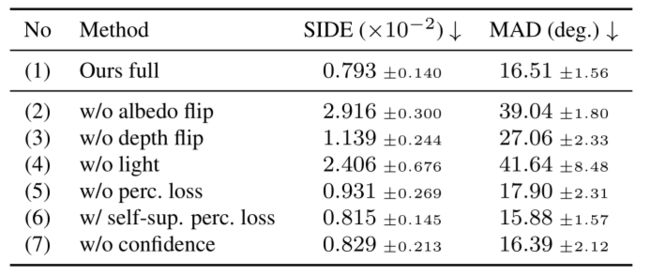
与当前SOTA比较☟

同时,作者在论文的最后也提到了目前工作的限制和不足。

主要有三点,其一如果假设一个简单的Lambertian阴影模型,忽略阴影和镜面反射,这会导致在极端照明条件或高度非Lambertian曲面下的不精确重建,如上图a所示;其二,分离嘈杂的深色纹理和阴影非常困难,如上图b所示;其三,极端姿态下的重建质量较低,如上图c所示。
3
磁灶“95后”一作
前面也提到,这篇CVPR 2020 最佳论文有三位作者,他们都来自牛津大学,其中吴尚哲在2018年从香港科技大学毕业后进入牛津视觉几何组,进行计算机视觉领域的研究。

当他进入赴牛津大学攻读博士时候,他的家乡晋江对他进行了报道,晋江新闻网说:
年仅22岁的吴尚哲2014年考取香港科技大学,今年以来,他接连收到了牛津大学、苏黎世联邦理工学院、洛桑联邦理工学院的博士项目全额奖学金录取,以及号称“世界计算机第一学府”的美国卡内基梅隆大学硕士项目录取。再过不久,他将前往牛津大学,加入世界顶级的计算机视觉研究组,师从“欧洲计算机科学家”Andrew Zisserman的其弟子Andrea Vedaldi,致力于人工智能相关研究。

通过晋江新闻的报道,我们也可以看出,他家境并不富裕,父母亲在磁灶社区的老街里经营着一家裁缝店。在他年幼时,全家4口人挤住在一个30平方米的两层老房子里。
贫困的家庭环境中,每日耳濡目染父母亲为了生计的艰辛,培养了他独立自主的能力,更坚定了他奋发学习的决心。
通过努力学习,吴尚哲中学期间获得过全国中学生物理竞赛福建省一等奖,数学竞赛福建省三等奖,以及英语演讲比赛各级奖项等。得益于竞赛获奖的缘故,他获得了保送西安交大的机会,但在一次偶然的机会,他又自己做主报考了香港科技大学。
在香港科技大学读大三时,其就开始跟随导师邓智强和戴宇榮从事计算机视觉相关研究,甚至当时还发表了两篇国际顶级会议论文,并获得出国交流学习的机会。
而如今,我们可以从上面谷歌学术的截图能够看到,吴尚哲已经有了三篇顶会论文,而且都是第一作者。并且,这三篇论文已经有了些引用量。
当初,他远赴牛津大学深造,家乡媒体为他报道,是对他刻苦学习的认可,如今他能够在几千篇CVPR论文中斩获得最佳论文,则是他不忘初心,持续奋斗,回报家乡的最好礼物。
最后,我们也祝愿这位同学,继续努力学习技能,用知识改变命运,争取早日学有所成,回报社会,回报家乡。
Via http://news.ijjnews.com/system/2018/08/24/011032512.shtml
END

备注:3D

三维视觉与三维重建交流群
3D计算机视觉技术、3D重建等技术,
若已为CV君其他账号好友请直接私信。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 